JUC是什么
JUC就是java.util .concurrent工具包的简称。是处理线程的工具包,JDK 1.5更新的。
锁
在并发情况下,需要加锁以防各种并发问题,下面来看下原生的锁和JUC下的锁实现方式
Synchronized VS Lock 实现差异
public class Demo1Controller {
public static void main(String[] args) {
TicketBySynchronized ticket=new TicketBySynchronized();
new Thread(()-> {
for (int i = 0; i < 20; i++) {
ticket.sall1();
}
},"a").start();
new Thread(()->{
for (int i = 0; i < 20; i++) {
ticket.sall1();
}
},"b").start();
new Thread(()->{
for (int i = 0; i < 20; i++) {
ticket.sall1();
}
},"c").start();
}
}
/*
*原版synchronized解决并发代码
*/
class TicketBySynchronized{
private int count=10;//一共有10张票
public void sall1(){
synchronized (this) {//同步代码块方式
if(count>0){
try {
TimeUnit.SECONDS.sleep(1);//加等待是为了方便复现不加synchronized并发问题
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(String.format("线程%s买到了第%s张票", Thread.currentThread().getName(), count--));
}
}
}
public synchronized void sall2(){//加到方法上的方式
if(count>0){
try {
TimeUnit.SECONDS.sleep(1);//加等待是为了方便复现不加synchronized并发问题
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(String.format("线程%s买到了第%s张票",Thread.currentThread().getName(),count--));
}
}
}
/**
* JUC ReentrantLock防止并发代码如下
*/
class TicketByJuc{
private int count=10;//一共有10张票
Lock reentrantLock = new ReentrantLock();//可重入锁
public void sall(){
reentrantLock.lock();
try {
if(count>0){
try {
TimeUnit.SECONDS.sleep(1);//加等待是为了方便复现不加synchronized并发问题
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(String.format("线程%s买到了第%s张票", Thread.currentThread().getName(), count--));
}
}finally {
reentrantLock.unlock();//必须要在finally中解锁,以防死锁
}
}
}
Synchronized & Lock 总结
-
Synchronized是java内置关键字,在jvm层面,Lock是个java类;
-
Synchronized无法判断是否获取锁的状态,Lock可以判断是否获取到锁;
-
Synchronized会自动释放锁(正常执行完会释放、发生异常会释放);
Lock需在finally中手工释放锁(unlock()方法释放锁),否则容易造成线程死锁;
- 用Synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1
阻塞,线程2则会一直等待下去;
Lock锁就不一定会等待下去,如果尝试获取不到锁,线程可以不用一直等待就结束了;
- Synchronized的锁可重入、不可中断、非公平,而Lock锁可重入、可判断&可公平
- Lock锁适合大量同步的代码的同步问题,Synchronized锁适合代码少量的同步问题。
Synchronized锁的对象是什么
非静态方法,锁的就是调用方法的那个实例对象
静态方法,锁的是class文件
同步代码块,锁的是配置的对象
生产者&消费者
只有两个线程的生产者消费者模式
程序流程,当库存等于1的时候,A线程生产,否则A线程等待,当库存大于1的时候,B线程消费,否则B线程等待
a. 传统模式,synchronized
public class Demo1 {
public static void main(String[] args) {
PublicData1 pub=new PublicData1();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.produce();//启动生产者,生产50次
}
},"A").start();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.consume();//启动消费者,消费50次
}
},"B").start();
}
}
/**
* 公共资源抽取(传统模式,synchronized)
*/
class PublicData1{
private int count=0;
public synchronized void produce(){
if(count!=0){
//有库存,生产者等待
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//没库存,生产者运行(count++)
System.out.println(String.format("线程%s生产了%s",Thread.currentThread().getName(),count++));
//唤醒其他线程
this.notifyAll();
}
public synchronized void consume(){
if(count==0){
//没库存,消费者等待
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//有库存,消费者运行(count--)
System.out.println(String.format("线程%s消费了%s",Thread.currentThread().getName(),count--));
//唤醒其他线程
this.notifyAll();
}
}
b. JUC模式
public class Demo1 {
public static void main(String[] args) {
PublicData2 pub=new PublicData2();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.produce();//启动生产者,生产50次
}
},"A").start();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.consume();//启动消费者,消费50次
}
},"B").start();
}
}
/**
* 公共资源抽取(JUC模式)
*/
class PublicData2{
private int count=0;
Lock lock=new ReentrantLock();
Condition condition = lock.newCondition();
public void produce(){
lock.lock();
try {
if(count!=0){
//有库存,生产者等待
try {
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//没库存,生产者运行(count++)
System.out.println(String.format("线程%s生产了%s",Thread.currentThread().getName(),count++));
//唤醒其他线程
condition.signalAll();
}finally {
lock.unlock();
}
}
public void consume(){
lock.lock();
try {
if(count==0){
//没库存,消费者等待
try {
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//有库存,消费者运行(count--)
System.out.println(String.format("线程%s消费了%s",Thread.currentThread().getName(),count--));
//唤醒其他线程
condition.signalAll();
}finally {
lock.unlock();
}
}
}
两个线程以上的生产者消费者模式
a. 传统模式,synchronized
public class Demo1 {
public static void main(String[] args) {
PublicData1 pub=new PublicData1();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.produce();
}
},"A").start();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.consume();
}
},"B").start();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.produce();
}
},"C").start();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.consume();
}
},"D").start();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.produce();
}
},"E").start();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.consume();
}
},"F").start();
}
}
/**
* 公共资源抽取(传统模式,synchronized)
*/
class PublicData1{
private int count=0;
public synchronized void produce(){
while (count!=0){
//有库存,生产者等待
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//没库存,生产者运行(count++)
System.out.println(String.format("线程%s生产了%s",Thread.currentThread().getName(),count++));
//唤醒其他线程
this.notifyAll();
}
public synchronized void consume(){
while(count==0){
//没库存,消费者等待
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//有库存,消费者运行(count--)
System.out.println(String.format("线程%s消费了%s",Thread.currentThread().getName(),count--));
//唤醒其他线程
this.notifyAll();
}
}
b. JUC模式
public class Demo1 {
public static void main(String[] args) {
PublicData2 pub=new PublicData2();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.produce();
}
},"A").start();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.consume();
}
},"B").start();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.produce();
}
},"C").start();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.consume();
}
},"D").start();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.produce();
}
},"E").start();
new Thread(()->{
for (int i = 0; i <50 ; i++) {
pub.consume();
}
},"F").start();
}
}
/**
* 公共资源抽取(JUC模式)
*/
class PublicData2{
private int count=0;
Lock lock=new ReentrantLock();
Condition condition = lock.newCondition();
public void produce(){
lock.lock();
try {
while (count!=0){
//有库存,生产者等待
try {
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//没库存,生产者运行(count++)
System.out.println(String.format("线程%s生产了%s",Thread.currentThread().getName(),count++));
//唤醒其他线程
condition.signalAll();
}finally {
lock.unlock();
}
}
public void consume(){
lock.lock();
try {
while(count==0){
//没库存,消费者等待
try {
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//有库存,消费者运行(count--)
System.out.println(String.format("线程%s消费了%s",Thread.currentThread().getName(),count--));
//唤醒其他线程
condition.signalAll();
}finally {
lock.unlock();
}
}
}
两个线程 & 两个以上线程的消费者生产者区别对比
有多个线程(两个以上)同时对公共资源进行操作(多个加、减操作),会导致虚假唤醒的情况出现,代码体现如下

精准唤醒
上面的例子,虽然保证了生产和消费是有序的,但无法保证多个线程如何精准唤醒,既ABCD四个线程执行是乱序的,下面来看如何指定线程唤醒
实现ABC三个线程顺序输出abcabcabc
public class Demo2 {
public static void main(String[] args) {
PublicData pub=new PublicData();
new Thread(()->{
for (int i = 0; i <3 ; i++) {
pub.A();
}
},"A").start();
new Thread(()->{
for (int i = 0; i <3 ; i++) {
pub.B();
}
},"B").start();
new Thread(()->{
for (int i = 0; i <3 ; i++) {
pub.C();
}
},"C").start();
}
}
/**
* 公共资源抽取()
*/
class PublicData{
private int tag=0;// 0=A线程 1=B线程 2=C线程
Lock lock=new ReentrantLock();
Condition conditionA = lock.newCondition();
Condition conditionB = lock.newCondition();
Condition conditionC = lock.newCondition();
public void A(){
lock.lock();
try {
//判断A线程是否可执行
while (tag !=0){
//不为0,则等待
try {
conditionA.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
tag=1;//将标记为修改为下一个线程B的
System.out.println(String.format("线程%s执行%s",Thread.currentThread().getName(),"a"));
conditionB.signal();//唤醒B线程
}finally {
lock.unlock();
}
}
public void B(){
lock.lock();
try {
//判断B线程是否可执行
while (tag !=1){
//不为1,则等待
try {
conditionB.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
tag=2;//将标记为修改为下一个线程C的
System.out.println(String.format("线程%s执行%s",Thread.currentThread().getName(),"b"));
conditionC.signal();//唤醒C线程
}finally {
lock.unlock();
}
}
public void C(){
lock.lock();
try {
//判断B线程是否可执行
while (tag !=2){
//不为2,则等待
try {
conditionC.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
tag=0;//将标记为修改为下一个线程A的
System.out.println(String.format("线程%s执行%s",Thread.currentThread().getName(),"c"));
conditionA.signal();//唤醒A线程
}finally {
lock.unlock();
}
}
}
多线程下集合如何保证并发安全
注:java中所有的集合都是不安全的,并发下会报 ConcurrentModificationException异常
CopyOnWriteArray
List
JUC的方式:CopyOnWriteArrayList
public static void main(String[] args) {
CopyOnWriteArrayList copyOnWriteArrayList = new CopyOnWriteArrayList();//获得一个线程安全的List,底层采用复制写入方法
for (int i = 0; i <10 ; i++) {
int finalI = i;
new Thread(()->{
copyOnWriteArrayList.add(finalI);
System.out.println(copyOnWriteArrayList);
}).start();
}
}
其他保证安全的解决办法
- Vector是线程安全类,在JDK1.0就有了,比ArrayList早,性能差
- 使用Collections.synchronizedList()修改为安全的,性能差
为什么CopyOnWriteArray性能要高
Vector是增删改查方法都加了synchronized,保证同步,但是每个方法执行的时候都要去获得锁,性能就会大大下降,而CopyOnWriteArrayList 只是在增删改上加锁,但是读不加锁,在读方面的性能就好于Vector,CopyOnWriteArrayList支持读多写少的并发情况
Set
JUC的方式:CopyOnWriteArraySet
public static void main(String[] args) {
CopyOnWriteArraySet copyOnWriteArraySet = new CopyOnWriteArraySet();
for (int i = 0; i <50 ; i++) {
int finalI = i;
new Thread(()->{
copyOnWriteArraySet.add(finalI);
System.out.println(copyOnWriteArraySet);
}).start();
}
}
注:hashset底层就是hashmap
其他保证安全的解决办法
Collections.synchronizedSet()
Map
JUC的方式:ConcurrentHashMap
public static void main(String[] args) {
ConcurrentHashMap concurrentHashMap = new ConcurrentHashMap();
for (int i = 0; i <100 ; i++) {
int finalI = i;
new Thread(()->{
concurrentHashMap.put(finalI,finalI);
System.out.println(concurrentHashMap);
}).start();
}
}
其他保证安全的解决办法
Collections.synchronizedMap()
Callable
带返回值的线程
public class Demo1 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
PublicCallable callable=new PublicCallable();
FutureTask task=new FutureTask(callable);//用它包装一下实现Callable的对象
new Thread(task).start();//Thread类不能直接接收一个Callable类,所以找官方文档,发现Runnable有一个实现类FutureTask
System.out.println(task.get());//这会有返回值,如果线程还未执行完,会阻塞下去
// System.out.println(task.get(2,TimeUnit.SECONDS));可以设置等待多久,超时会报TimeoutException
}
}
class PublicCallable implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("调用了");
TimeUnit.SECONDS.sleep(2);
return "ok";
}
}
多线程常用辅助类
CountDownLatch
可设置一个屏障,只有指定数量线程|功能执行完后(--操作),才去执行指定代码的,否则就一直等待
//不论怎么执行,end都是最后一个出现
public static void main(String[] args) throws ExecutionException, InterruptedException, TimeoutException {
CountDownLatch countDownLatch = new CountDownLatch(3);
for (int i = 0; i <5 ; i++) {
new Thread(()->{
System.out.println(Thread.currentThread().getName());
countDownLatch.countDown();//执行完一个,就减一个
},"t"+i).start();
}
countDownLatch.await();//当CountDownLatch(3) 三个执行后,主程序继续执行
//countDownLatch.await(2,TimeUnit.SECONDS);//可设置一个超时时间,如果超时未执行完,则返回false,否则返回true,后继续输出end
System.out.println("end");
}
CountDownLatch 主要有两个方法,当一个或多个线程调用 await 方法时,这些线程会阻塞
其他线程调用CountDown方法会将计数器减1(调用CountDown方法的线程不会阻塞)
当计数器变为0时,await 方法阻塞的线程会被唤醒,继续执行
应用场景
CyclicBarrier
可设置一个屏障,只有指定数量线程|功能执行完后(++操作),才去执行代码的,否则就一直等待
public static void main(String[] args) throws ExecutionException, InterruptedException, TimeoutException {
CyclicBarrier cyclicBarrier = new CyclicBarrier(3,()->{//三个人都到的时候才执行下面的
System.out.println("人数够了");
});
new Thread(()->{
System.out.println("第一个人到了");
try {
cyclicBarrier.await();//人数++操作
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}).start();
new Thread(()->{
System.out.println("第二个人到了");
try {
cyclicBarrier.await();//人数++操作
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}).start();
new Thread(()->{
System.out.println("第三个人到了");
try {
cyclicBarrier.await();//人数++操作
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}).start();
}
应用场景
Semapore
最大访问量控制,线程池、流量控制
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(3);//设置只有三个线程的位置
for (int i = 0; i <5; i++) {
new Thread(()->{
try {
semaphore.acquire();//每个线程开始执行前,先去获取一下,是否还有位置,没有位置就阻塞等待
System.out.println(Thread.currentThread().getName()+"-in");
TimeUnit.SECONDS.sleep(3);
System.out.println(Thread.currentThread().getName()+"-out");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
semaphore.release();//执行完释放位置,其他等待线程加入执行
}
},"A"+i).start();
}
}
应用场景
读写锁
ReenTrantReadWriteLock
关系: 读读可并行;读写不可并行;写写不可并行
下面的例子如果不加读写锁,那么就不能保证写的时候**一定是 **开始->执行中->结束
如果加上读写锁,如果在线程A读的时候发现还有线程B在写同一个数据,则会等待线程B写完后再继续,防止B刚读完,A把数据修改了,造成脏读
public static void main(String[] args) {
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
ReentrantReadWriteLock.ReadLock readLock = lock.readLock();//获得读锁
ReentrantReadWriteLock.WriteLock writeLock = lock.writeLock();//获得写锁
for (int i = 0; i <5 ; i++) {
new Thread(()->{
try {
writeLock.lock();//写锁加锁
exe_write();
}finally {
writeLock.unlock();//写锁释放
}
},"写"+i).start();
}
for (int i = 0; i <5 ; i++) {
new Thread(()->{
try {
readLock.lock();//读锁加锁
exe_read();
}finally {
readLock.unlock();//读锁释放
}
},"读"+i).start();
}
}
public static void exe_write(){
String name = Thread.currentThread().getName();
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(name+"开始");
System.out.println(name+"执行中");
System.out.println(name+"结束");
}
public static void exe_read(){
String name = Thread.currentThread().getName();
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(name+"开始");
System.out.println(name+"执行中");
System.out.println(name+"结束");
}
对比:

阻塞队列
只列举了部分,更多见JDK8文档
当队列是空的,从队列中获取元素的操作将会被阻塞。
当队列是满的,从队列中添加元素的操作将会被阻塞。
试图从空的队列中获取元素的线程将会被阻塞,直到其他线程往空的队列插入新的元素。
ArrayBlockingQueue
由数组组成的队列,必须指定队列大小
常用方法
ArrayBlockingQueue queue = new ArrayBlockingQueue(3);//数组实现的阻塞队列(必须指定队列大小)
queue.add("a1");//向队列中插入一个元素,如果超出队列数量,则抛出Queue full异常
queue.offer("a2");//尝试向队列中插入元素,成功返回true,否则返回false
queue.contains("a1");//判断队列中是否有指定元素,有的话返回true,队列为空则 抛异常 NoSuchElementException
queue.element();//获得队首的元素,如果队列为空会抛异常 NoSuchElementException
queue.remove();//删除队首元素,如果队列为空会抛异常 NoSuchElementException
queue.take();//获得队首元素,如果队列为空,则阻塞等待到有值为止
queue.peek();//获得队首元素,但不从队列中移除,如果队列中没有元素,返回null
queue.poll();//获得队首元素,并且从队列中移除,如果队列中没有元素,返回null;可设置超时时间,等待指定时间后如果没有获取到数据,则返回null
LinkedBlockingQueue
由链表组成的队列,可不指定队列大小,默认大小为 Integer.MAX_VALUE
常用方法
参考ArrayBlockingQueue
SynchronousQueue
队列只有一个位置,不存储多余的元素
常用方法
参考ArrayBlockingQueue
LinkedBlockingDeque
由链表组成的双端队列,可不指定队列大小,默认大小为 Integer.MAX_VALUE
常用方法
LinkedBlockingDeque deque = new LinkedBlockingDeque(2);
deque.add("a1");//在队尾添加元素,如果队列超出大小,抛出 Deque full
deque.addFirst("a2");//在队首添加元素,如果队列超出大小,抛出 Deque full
deque.addLast("a3");//在队尾添加元素,如果队列超出大小,抛出 Deque full
deque.element();//获得队首元素,不在队列中删除,队列为空抛出NoSuchElementException
deque.getFirst();//获得队首元素,不在队列中删除,队列为空抛出NoSuchElementException
deque.getLast();//获得队尾元素,不在队列中删除,队列为空抛出NoSuchElementException
deque.offerFirst("a4");//在队首插入元素,如果成功返回true,否则返回false,如果队列满了,可以指定等待时间,如果时间内有空间了,就返回true
deque.offerLast("a5");//在队尾插入元素,如果成功返回true,否则返回false,如果队列满了,可以指定等待时间,如果时间内有空间了,就返回true
deque.peekFirst();//获得队首元素,但不从队列中删除,队列为空返回null
deque.peekLast();//获得队尾元素,但不从队列中删除,队列为空返回null
deque.pollFirst();//获得队首元素,从队列中删除,队列为空返回null,可以指定等待时间,如果时间内有元素了,就返回
deque.pollLast();////获得队尾元素,从队列中删除,队列为空返回null,可以指定等待时间,如果时间内有元素了,就返回
deque.remove("a1");//删除指定元素,成功true 否则false
deque.removeFirst();//删除队首元素,并返回删除的元素,队列为空抛出异常NoSuchElementException
deque.removeLast();//删除队尾元素,并返回删除的元素,队列为空抛出异常NoSuchElementException
deque.takeFirst();//删除队首元素,并返回删除的元素,队列为空则阻塞等待
deque.takeLast();//删除队尾元素,并返回删除的元素,队列为空则阻塞等待
线程池
Executors
newFixedThreadPool
public static void main(String[] args) throws InterruptedException, ExecutionException {
//创建一个固定长度(核心线程和最大线程数都为3的线程),没有过期时间,一个大小为Integer.MAX_VALUE的链表阻塞队列
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
for (int i = 0; i <10 ; i++) {//执行10个没有返回值的线程
fixedThreadPool.execute(()->{
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程"+Thread.currentThread().getName()+"来了");
});
}
for (int i = 0; i < 10; i++) {//执行10个有返回值的线程
FutureTask futureTask = new FutureTask(new FutureTaskDemo());
fixedThreadPool.submit(futureTask);
System.out.println(futureTask.get());//获得线程执行后的返回值,如果还没返回阻塞等待
}
fixedThreadPool.shutdown();//关闭线程池
}
static class FutureTaskDemo implements Callable<String>{
@Override
public String call() throws Exception {
String name = Thread.currentThread().getName();
System.out.println("线程"+ name +"开始休息");
TimeUnit.SECONDS.sleep(2);
return "线程"+ name +"休息了两秒,通知上级";
}
}
newCachedThreadPool
ExecutorService executorService = Executors.newCachedThreadPool();
//创建一个可变长度的(大小0~Integer.MAX_VALUE),存活时间60秒的队列
//使用方法同fixedThreadpool
newSingleThreadPool
ExecutorService executorService = Executors.newSingleThreadExecutor();
//创建一个只有定长的线程池(只有一个线程),并用LinkedBlockingQueue存储还未执行的(LinkedBlockingQueue长度为Integer.MAX_VALUE)
//使用方法同fixedThreadpool
newScheduledThreadPool
public static void main(String[] args) throws Exception {
//创建一个核心线程数为指定个数,最大线程数为Intager.MAX_VALUE的线程池,创建的线程不会自动失效
ScheduledExecutorService pool = Executors.newScheduledThreadPool(2);
FutureTask futureTask = new FutureTask(new FutureTaskDemo());
pool.scheduleWithFixedDelay(()->{
System.out.println("线程"+Thread.currentThread().getName());
},1,5,TimeUnit.SECONDS);//指定首次运行在1秒以后,然后保持5秒钟执行一次
}
newSingleThreadScheduledExecutor
ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();
//创建一个创建一个核心线程数为1的线程池,其他方法同newScheduledThreadPool
注意
以上使用Executors创建线程池都有隐患,阿里开发手册也明确禁止使用,因为上面都用了Intager.MAX_VALUE,会导致各种内存溢出等问题。
推荐用ThreadPoolExecutor创建
ThreadPoolExecutor
七个参数
corePollSize :核心线程数。在创建了线程池后,线程中没有任何线程,等到有任务到来时才创建线程去执行任务。默认情况下,在创建了线程池后,线程池中的 线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中。
maximumPoolSize :最大线程数。表明线程中最多能够创建的线程数量,此值必须大于等于1。
keepAliveTime :空闲的线程保留的时间。
TimeUnit :空闲线程的保留时间单位。
BlockingQueue< Runnable> :阻塞队列,存储等待执行的任务。参数有ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue可选。
ThreadFactory :线程工厂,用来创建线程,一般默认即可
RejectedExecutionHandler:队列已满,而且任务量大于最大线程的异常处理策略。
四个拒绝策略
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务
(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
原理

函数式接口
Function
函数型接口,有一个输入,有一个输出 ,可指定入参出参的类型,Function<T, R>
public static void main(String[] args) {
Function<Integer, String> function = new Function<Integer, String>() {
@Override
public String apply(Integer integer) {
return "test"+integer;
}
};
//上面是非简化版的,下面是通过lombda简化版的
Function<Integer,String> simple_function=num->{return "test"+num;};//拿到传入的对象做点事情后返回
System.out.println(function.apply(2));
}
Predicate
断定型接口,有一个输入参数,返回只有布尔值 ,可指定入参类型
public static void main(String[] args) {
Predicate<String> stringPredicate = new Predicate<String>() {
@Override
public boolean test(String s) {
return false;
}
};
//上面是非简化版的,下面是通过lombda简化版的
Predicate<String> predicate=s -> {return true;};//拿到传入的对象做点事情后返回
System.out.println(predicate.test("a"));
}
Consumer
消费型接口,有一个输入参数,没有返回值 可指定入参类型
public static void main(String[] args) {
Consumer<String> stringConsumer = new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println("处理了数据"+s);
}
};
//上面是非简化版的,下面是通过lombda简化版的
stringConsumer.accept("rb");
Consumer<String> simple_stringConsumer =s -> { System.out.println("处理了数据"+s);};//拿到传入的对象做点事情
simple_stringConsumer.accept("RB");
}
Supplier
供给型接口,没有输入参数,只有返回参数
public static void main(String[] args) {
Supplier supplier = new Supplier() {
@Override
public Object get() {
return "rb";
}
};
//上面是非简化版的,下面是通过lombda简化版的
System.out.println(supplier.get());
Supplier simple_supplier =()->{return "RB";};//返回某些业务中的数据
System.out.println(simple_supplier.get());
}
Stream流式计算
测试代码
@Data
class User {//vo
private int id;
private String userName;
private int age;
}
List<User> list=new ArrayList();
for (int j = 10; j >=0 ; j--) {//封装测试数据
User user = new User();
int age = j - 1;
user.setAge(age);
user.setId(j);
user.setUserName("RB"+j);
list.add(user);
}
Stream<User> stream = list.stream();//获得流
filter
stream.filter(u -> u.getAge() > 3 && u.getId()>4);//过滤年龄大于3岁并且id大于4的
值求和计算
stream.mapToInt(User::getAge).sum();//对年龄求和 mapToDouble mapToLong mapToInt
MaxMin,获得流中最大&最小的元素
stream.max(Comparator.comparing(User::getId).reversed());//获得集合中最小的元素,不加reversed()就是返回最大的
//stream.min同理
Match,判断流中是否包含指定关键字
当所有元素都 -不具备- 指定关键字的时候,返回true
stream.noneMatch(user -> user.getUserName().contains("1"));//user集合中姓名都不包含1,返回true
当所有元素都 -具备- 指定关键字的时候,返回true
stream.allMatch(user -> user.getUserName().contains("B"));//user集合中姓名都包含B,返回true
-只要- 有元素具备指定关键字的时候,返回true
stream.anyMatch(user -> user.getUserName().contains("B10"));//user集合中姓名有包含B10的,返回true
map
stream.map(user-> user.getUserName().toLowerCase());//将集合中姓名转大写,并且将此列返回
findFirst
System.out.println(stream.findFirst());//获得第一个元素
limit
stream.limit(2);获得下标0-1的元素
distinct
stream.distinct();//去重
sorted
stream.sorted(Comparator.comparing(User::getId).reversed());//按照id倒序,不加.reversed()就是按照id正序
Arrays.asList(3,4,1,2,5).stream().sorted(((o1, o2) -> o2.compareTo(o1)))//如果集合中不是对象,直接调用.sorted()就是正序,否则传入对应参数为倒序
forEach
stream.forEach(System.out::println);//循环输出处理后的数据
collect
System.out.println(stream.collect(Collectors.toList()));//将结果转为list集合
System.out.println(stream.collect(Collectors.toSet()));//将结果转为set集合
System.out.println(stream.collect(Collectors.toMap(user -> user.getId(), user -> user)));//返回一个map,key=userid,value=User对象
ForkJoin
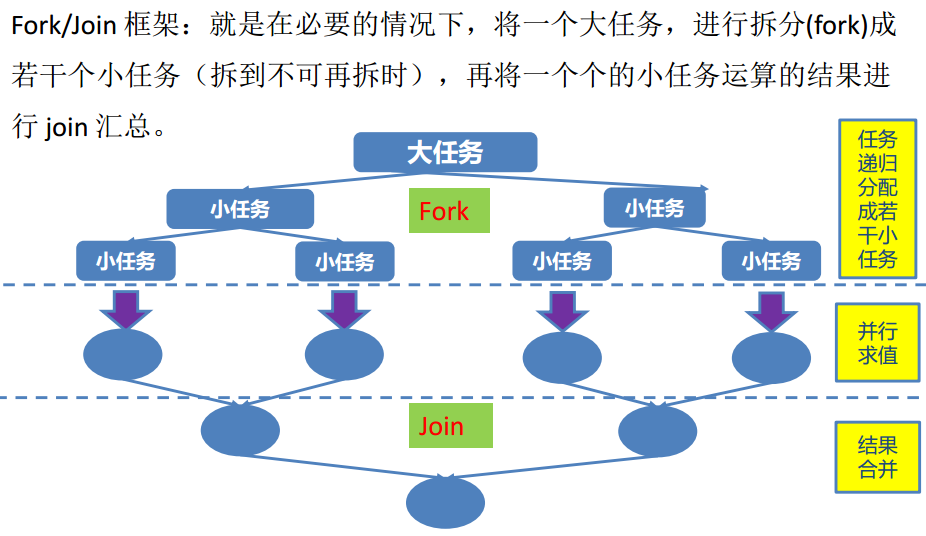
public static void main(String[] args) throws Exception {
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask forkJoinDemo = new ForkJoinDemo(0L, 100000000L);
ForkJoinTask<Long> submit = forkJoinPool.submit(forkJoinDemo);
System.out.println(submit.get());
}
//继承RecursiveTask是有返回值的,继承RecursiveAction是无返回值的,无返回值的compute如下
//@Override
//protected void compute() {}
class ForkJoinDemo extends RecursiveTask<Long> {
private Long start;//起始值
private Long end;//结束值
public static final Long upper_limit = 1000L;//最小任单位,小于这个值直接计算,否则就进行任务拆分
public ForkJoinDemo(Long start, Long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long len = end - start;
if(len<=upper_limit){//判断是否是最小任务单位
//直接执行后返回
long count=0L;
for (long i = start; i < end; i++) {
count=i+1;
}
return count;
}else{
Long temp=(end + start)/2;//如果不是最小单位,则继续拆分
ForkJoinDemo forkJoinDemo1 = new ForkJoinDemo(start, temp);//递归,拿到最新的start,end去看看是否要拆分
ForkJoinDemo forkJoinDemo2 = new ForkJoinDemo(temp+1, end);//递归,拿到最新的start,end去看看是否要拆分
forkJoinDemo1.fork();//拆分后的任务开始执行
forkJoinDemo2.fork();//拆分后的任务开始执行
return forkJoinDemo1.join()+forkJoinDemo2.join();//对结果进行汇总返回
}
}
}
Future(异步回调)
无返回值
CompletableFuture<Void> voidCompletableFuture = CompletableFuture.runAsync(()->{
try {
TimeUnit.SECONDS.sleep(2);//延时两秒钟
System.out.println("异步执行");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println("主线程执行");
voidCompletableFuture.get();//等待异步执行完成
有返回值
CompletableFuture<String> objectCompletableFuture = CompletableFuture.supplyAsync(()->{
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "异步执行结果";
});
System.out.println("主线程执行");
System.out.println(objectCompletableFuture.get());