最好大学网
2018大学排名
功能描述:
输入:大学排名url链接
输出:大学排名信息的屏幕输出(排名,大学名称,总分)
技术路线:requests库和bs4库
定向爬虫:仅对输入的URL进行爬取,不扩展爬取
步骤:
1、输入url网址,查看源代码,发现信息都在HTML文件中
2、打开http://www.zuihaodaxue.cn/robots.txt,发现:not found,说明没有对爬取进行robots协议限制,可以进行爬取
3、程序的结构设计:
步骤1,从网络上获取大学排名网页内容,getHTMLText()
步骤2、提取网页内容中信息到合适的数据结构,fillUnivList()
步骤3、利用数据结构展示并输出结果,printUnivList()
代码:
import requests from bs4 import BeautifulSoup import bs4#为了使用bs4的标签函数 #获取页面信息 def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return '' #将数据存到list中 def fillUnivList(ulist,html): soup=BeautifulSoup(html,'html.parser') #查看HTML源码发现每一所大学都在tbody标签中,这里一个tr表示一所大学 for tr in soup.find('tbody').children: if isinstance(tr,bs4.element.Tag):#判断是否为标签类型,过滤掉字符串 tds=tr('td') ulist.append([tds[0].string,tds[1].string,tds[2].string]) #pass #将num个list中的数据打印显示出来,可视化输出 def printUnivList(ulist,num): #打印表头 print('{:^10} {:^6} {:^10}'.format('排名','学校名称','总分')) for i in range(num): u=ulist[i] print('{:^10} {:^6} {:^10}'.format(u[0],u[1],u[2])) #print('Suc'+str(num)) #主函数 def main(): uinfo=[]#待放入数据的列表 url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html' html=getHTMLText(url) fillUnivList(uinfo,html) printUnivList(uinfo,20)#打印20组数据 main()
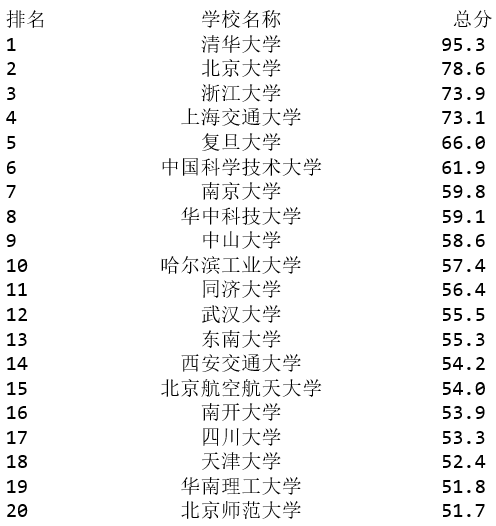
结果展示:

以上程序有一个问题,就是总分一栏输出的竟然是省份,这其实是这一行代码的问题:
ulist.append([tds[0].string,tds[1].string,tds[2].string]) #这里应该改为 #ulist.append([tds[0].string,tds[1].string,tds[3].string])
更改后就没有问题了。
在这里我们的设计思路是:
先搭建程序的框架,先定义三个函数名,然后定义主函数,主函数会依次调用三个函数,然后再分别充实三个子函数,一步步的写,这是写程序的正确方法。
当遇到bug时,我们可以逐步排查,比如先运行第一个程序,看看是否已经获得html文件,再逐步检查。
代码优化:
format属性
中文对齐的问题:
| : | <填充> | <对齐> | <宽度> | , | <精度> | <类型> |
|
引号 符号 |
用于填充 的单个字符 |
<左对齐 >右对齐 ^居中对齐 |
槽的设定 输出宽度 |
数字的千位 分隔符适用 于整数和浮点数 |
浮点数小数部分 的精度或字符串 的最大输出长度 |
整数类型b,c,d, o,x,X浮点数类型 e,E,f,% |
当中文字符宽度不够时,采用西文字符填充;中西文字符占用宽度不同。
解决方法:采用中文空格填充chr(12288)
将print**函数做修改
def printUnivList(ulist,num): #打印表头 tplt='{0:^10} {1:{3}^10} {2:^10}'#定义模板 print(tplt.format('排名','学校名称','总分',chr(12288))) for i in range(num): u=ulist[i] print(tplt.format(u[0],u[1],u[2],chr(12288)))
输出结果如下:发现输出已经居中