
本文是基于弱监督的深度学习的图像分割方法的综述,阐述了弱监督方法的原理以及相对于全监督方法的优势。
1 基础概念
生活中,我们和周围的事物都是有“标签”的,比如人、杯子、天空等等。在不同的场景下,相同的事物可能对应了不同的标签,比如长在地上的一片小草称为“草地”,长在花盆里的很可能属于“盆栽”,画在画中的又属于“装饰”。
如果把整幅图像比作我们生活的世界,那么具有相同“标签”的像素就组成了我们和周围的事物。图像分割的任务就是给这些像素标注它们所对应的“标签”,而这个标签通常取决于这个像素所属于的“整体”的类别。比如下图中就被分割成了天空、植被、草地和大象。

当然,与生活中相似,根据分类方式的不同,一个像素可能属于多种类别。比如下图中组成椅子的像素,按照整体应标注为“椅子”,细分下又属于“椅背”,按照材料分又属于“木头”。

根据方法和任务的不同,图像分割可以分成很多类。比如在只关心图像主要内容的时候,类别可能只有两类:前景(关心的内容)和背景(除前景之外的其他部分,即不关心的内容)。或者只关心可数的目标,比如行人、自行车、杯子等等;或只关心不可数目标,比如天空、草地、海洋等。由此,我们给出了下面两种可能的分类方式:
- 按模型分类:根据实现分割的手段,图像分割可以大致分为传统方法与基于深度学习的方法。前者依靠纯数学公式推导实现分割,而后者则依靠深度学习结构(如神经网络、随机树等)实现分割。
- 按任务分类:根据图像分割的具体任务,又可以将其分为语义分割(semantic segmentation)、实例分割(instance segmentation)与全景分割(panoptic segmentation)。
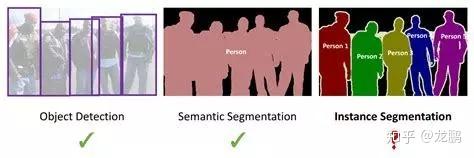
如上图所示,语义分割是比较容易的一种,其要求的是对所有像素点进行类别标注,比如天空、车、杯子等,但是不区分相同类别的个体,即所有属于“杯子”的像素点都被标注成相同的标签。而实例分割比语义分割困难一些,其不仅要求要标注像素点,还要区分相同类别的不同实例,比如“这个杯子”和“那个杯子”。
但是实例分割受限其要求,通常都是对可数的物体进行分割,而在不可数内容上(比如草地、马路等),要么没有分割,要么属于一个类别。当其将属于某一个不可数类别的像素点都标注成相同标签,而所有属于可数类别的像素点按实例标注时,就成为了所谓的全景分割(如下图所示)。

本文中我们主要介绍基于深度学习的图像分割方法,包括语义分割、实例分割和全景分割。
2 为什么要弱监督学习
像前面说过的,图像分割的任务是对每个像素都进行标注。因此,在深度学习方法中,直观上就需要所有的像素都有真值标注。不难看出,这个要求下,真值标注的生成是极度耗时耗力的,尤其是以人工标注的方式。比如,CityScapes数据库,在精标条件下,一张图片的标注就需要1.5个小时。如此一来,数据库标注的成本可想而知。
基于此,许多研究人员就想到用弱监督的方式进行网络训练,从而降低标注成本。所谓弱监督,就是用更容易获得的真值标注替代逐像素的真值标注,常见的输入有image-level tags和bounding boxes。下图给出的是这两种标注的示例。

image-level tag:一张图片对应一个标签。如上图,标签为“猫”。

bounding box:即用一个矩形框(2D)或长方体(3D)给出目标存在的位置及标签。
可见,这两种标注的获得比逐个像素标注容易太多。具体来说,一个bounding box的标注只需要7秒,而一个image-level tag的标注只需要1秒,按照这种方式,CityScapes数据库的标注时间将缩短30倍。
在弱监督算法中,有的网络是直接利用这些标注作为输入;也有的网络是在这些标注的基础上生成部分像素点的标注,再进行全监督训练。但无论哪种方式,都可见直接降低了标注成本。
3 常用的弱监督分割算法
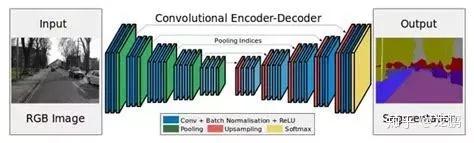
说完了基本概念和必要性,下面我们从输入的角度具体聊一下常用的弱监督分割算法有哪些。在分割任务中,常用的分割网络有AlexNet、VGG、GoogleNet、ResNet和ReNet等,且通常借助迁移学习和必要的数据处理及扩张实现较好的分割。这些方法和结构在弱监督分割算法中也非常常见。具体而言,分割任务中常用的方法有译码器(decoder)的变体;整合上下文信息的方法,如条件随机场、扩张卷积、多尺度估计、特征融合等。
下图就是一个典型的编码器-解码器结构。
考虑到关于分割算法的综述有许多,本文着重介绍弱监督分割算法中特殊的处理方法。针对不同任务需求,每种输入下的算法都按照语义分割、实例分割进行归纳(前景分割被归入语义分割中);而全景分割要同时完成两种分割任务,因此单独列出来。总体上,目前弱监督的语义分割研究成果比较多,但是实例分割与全景分割则要少很多。由于论文数量庞大,这里每种场景仅列出一篇有代表性的论文作为范例。
1. 基于image-level tags的分割算法
Image-level tags已经在前文给出了示例,可以看出这一种标注中主要包含的是相同类别之间的共性,但无法区分实例(比如所有的车都会被标注成“车”,而不会区分颜色、形状、大小、牌子等等)。因此基于image-level tags的算法大多用于语义分割,或是具有语义分割功能的实例分割或全景分割算法。下面就按照分类介绍部分基于image-level tags的深度学习分割算法。
(1) 《Built-in Foreground/Background Prior for Weakly-Supervised Semantic Segmentation》
这篇论文中提出的方法,是利用目标标签作为语义分割训练的先验,从而实现更高精度的分割效果。为了实现这个目的,这个方法中构建了一个预训练网络,其作用是给出前景像素点信息,而忽略背景信息。
下图是具体的网络结构。给定输入图像,网络经过了一个典型的编码器-解码器结构,随后通过一个条件随机场(CRF)生成最后的mask。整个网络的训练只需要image-level tags就可以。
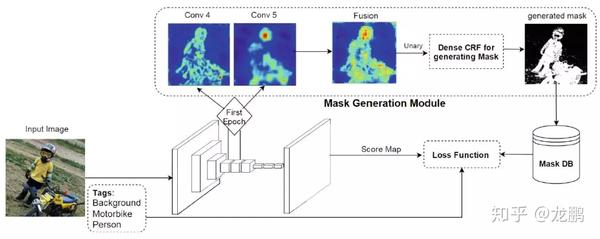
带有内置前背景先验的弱监督网络结构,图片来源于论文。

上图是编码器-解码器神经网络部分的完整结构,图片来源于论文。该网络结构是从VGG-16网络结构来的,感受野128,步长8。
(2) 《Exploiting saliency for object segmentation from image level labels》
此前的研究已经证明,可以从image-level labels中提取不同目标的信息(如下图所示)。

热度图(heatmap),图片来源于论文。
但是从上面的热度图也可以看出,如果目标之间存在遮挡,那么在没有额外信息的情况下,获取完整的目标就很困难了(固有的不适定问题)。
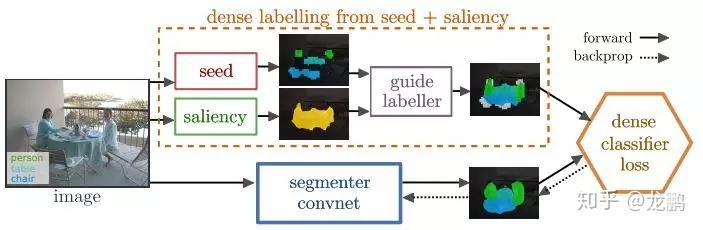
出于这个考虑,这篇论文中提出了一个可以提供辅助信息的模型。整个网络的训练只用到了image-level labels和saliency masks。下图是标注和论文结果。

下图是具体的网络结构,可以看出,辅助信息与分割网络是并行的,共同用于计算最后的损失。图片来源于论文。
2. 基于bounding boxes的分割算法
Bounding boxes是目标识别中常用的一种标注方式。现在许多算法已经能够实现很高精度的bounding boxes检测了,因此COCO Challenge等许多比赛已经取消了bounding boxes为输出的部分,而是更多关注于像素级的分割任务。
尽管如此,bounding boxes作为一种能够有效区分不同实例的标注方式,既包含了语义信息,也包含了实例信息。因此,bounding boxes被广泛应用于分割任务中,尤其是实例分割与全景分割。
(1) 语义分割
《Image Segmentation with A Bounding Box Prior》
这篇论文放在这里作为一个基准,是微软2009年提出的一种基于传统手段的前景分割方法。在此之前,尽管bounding box被广泛利用与图像分割任务中,但是大多数算法只是用其排除外部信息或有时用于初始化能量函数。
这篇论文中提出bounding box可以作为一种强大的拓扑先验(topological prior),既可以防止模型过度萎缩(分割小于前景目标的区域),也可以确保bounding box就足够用于分割任务了。论文用包含在全局能量最小化框架内的强约束表达此先验,从而构造一个NP-hard的完整程序。
下图左边是没有先验的分割结果,右边是有先验的分割结果。图片来源于论文。

下面的公式是将tightness prior融入图割(gruph cut framework)而得到的integer program(IP):

论文随后还介绍了一种可能的优化策略,包括linear relaxation和一种新的graph cut算法(称作pinpointing)。后者既可以作为fractional LP solution的舍入法(rounding method,效果比阈值方法好),也可以作为独立的快速启发式搜索(fast standalone heuristic)。下图是pinpointing的结果,图片来源于论文。

下图是论文中的算法与其他算法的实验结果比较,图片来源于论文。可以看出,在人的头部附近和植物枝干附近,这篇论文中的算法具有明显优势。

(2) 实例分割
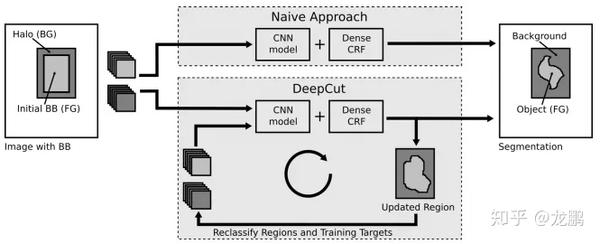
《DeepCut: Object Segmentation from Bounding Box Annotations using Convolutional Neural Networks》
这篇论文提出了一种给定弱标注的实例分割方法。其将微软研究院提出的GrabCut进行扩展,可以实现给定bounding boxes的神经网络分类器训练。该论文将分类问题视为在稠密连接的条件随机场下的能量最小化问题,并通过不断迭代实现实例分割。
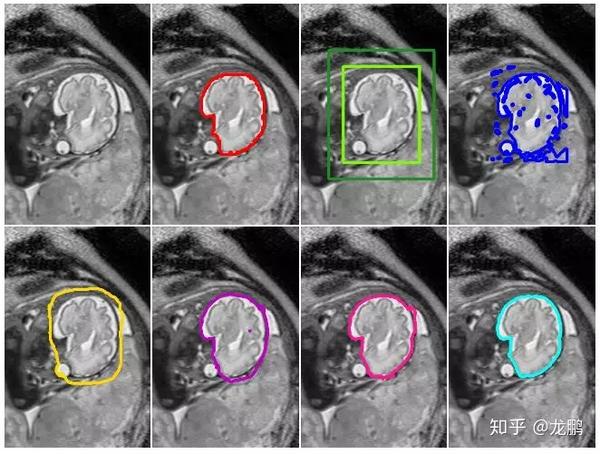
论文中还提出了一些DeepCut方法的变体,并将它们与其它算法在弱监督条件下进行了比较。值得注意的是,该算法在解决大脑和肺的两个问题上已经得到了实验,精度还不错(使用的数据库是fetal magnetric resonance dataset)。下图是基本的DeepCut网络结构,图片来源于论文。
下图是实验结果,图片来自于论文。
3. 全景分割
《Weakly- and Semi-Supervised Panoptic Segmentation》
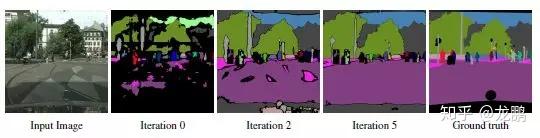
这篇文章介绍了一种基于弱监督的全景分割(实例分割加语义分割)的网络结构,目前在CityScapes上面语义分割与实例分割都是第一。论文中其实主要提出的是一种可以通过image-level tags和bounding boxes生成像素点标注的方法,当然这个方法无法标注全部的像素点的真值,但是按照前文所提到的理论,这些像素点的个数已经足够支撑网络的训练。同时,真值会随着网络结构的不断训练,逐渐完善。下图是真值标注的完善过程,图片来源于论文。
结果示例,图片来源于论文。

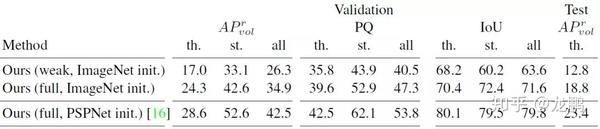
论文效果,图片来源于论文。
4 总结一下
通过这篇文章,我们了解了什么是图像分割及其种类,什么是图像分割中的弱监督训练,以及常用的方法。简而言之,弱监督训练就是用更少、更容易获得的真值标注,替代逐像素的真值标注,从而在降低标注成本的基础上,维持较高水平的分割。
目前,随着分割领域的不断发展,语义分割与实例分割逐渐融合,全景分割正在成为新的主流趋势。至于如何用好弱监督标签,怎么实现高精度的全景分割,就靠各位了。
参考文献
[1] A. Bansal, X. Chen, B. C. Russell, et al. Pixelnet: Representation of the pixels, by the pixels, and for the pixels[C].CoRR, 2017.
[2] Saleh F., Aliakbarian M.S., Salzmann M., et al. Built-in Foreground/Background Prior for Weakly-Supervised Semantic Segmentation[C]. ECCV, 2016, vol 9912.
[3] S. J. Oh, R. Benenson, A. Khoreva, et al. Exploiting saliency for object segmentation from image level labels[C]. CVPR, 2017.
[4] V. S. Lempitsky, P. Kohli, C. Rother, et al. Image
segmentation with a bounding box prior[C]. ICCV 2009: 277–284.
[5] M. Rajchl, M. C. H. Lee, O. Oktay, et al. Deepcut: Object segmentation from bounding box annotations using convolutional neural networks[J]. IEEE transactions on Medical Imaging, 2017, 36(2): 674–683.
[6] Q. Li, A. Arnab, and P. H. S. Torr. Weakly- and semi-supervised panoptic segmentation[C]. ECCV, 2018: 106–124.
[7] C. Rother, V. Kolmogorov, and A. Blake. Grabcut: interactive foreground extraction using iterated graph cuts[J]. ACM Transactions on Graphics, 2004, 23(3): 309–314.

更多资源获取,请关注公总号RaoRao1994