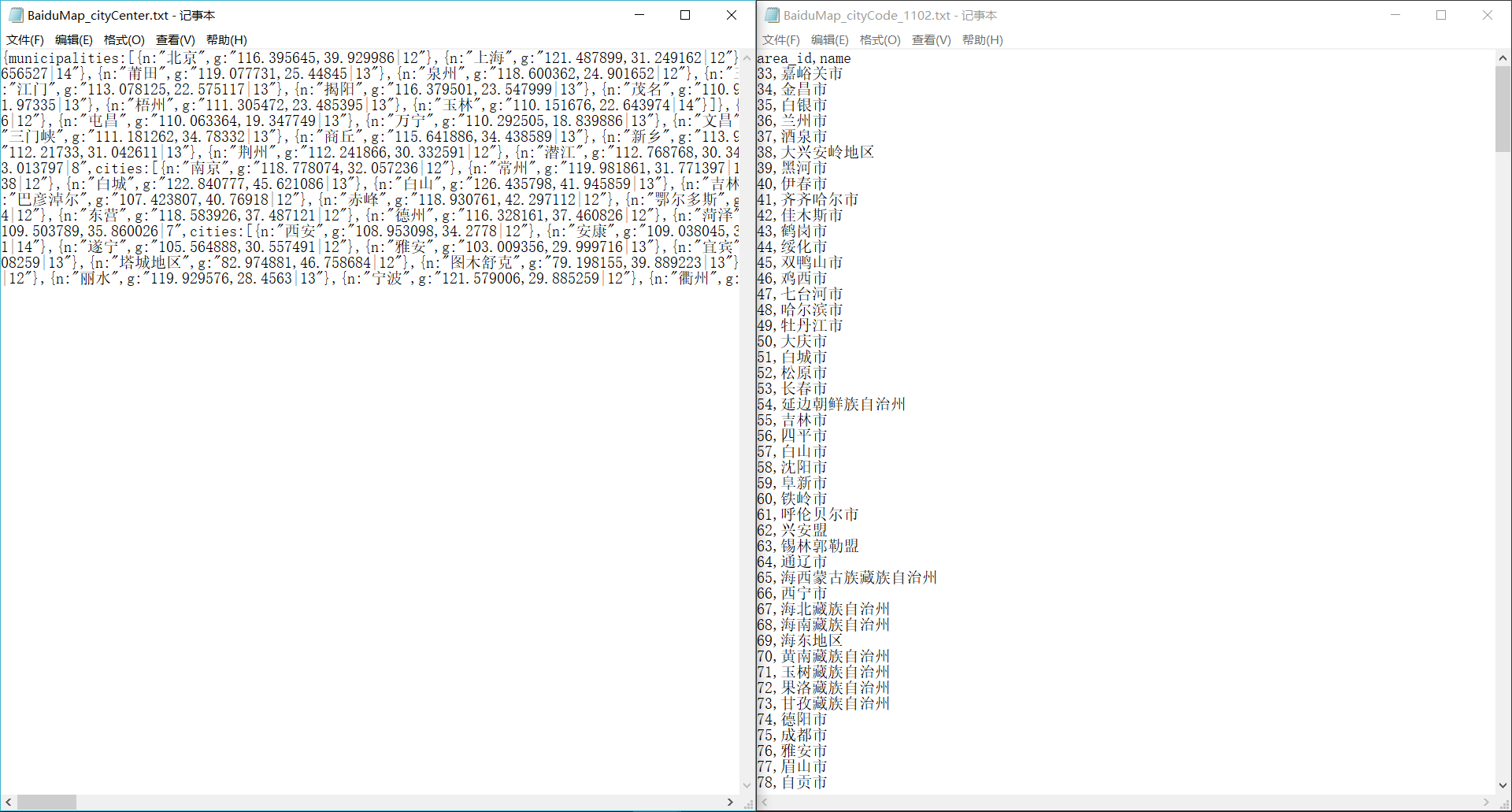
这个实在不好起名字。写这个还不是因为被渣度坑的不要不要的。为什么说他坑呢。参考一下这两个截图的txt文档:
文档资源下载地址: http://lbsyun.baidu.com/index.php?title=open/dev-res
或 http://lbsyun.baidu.com/index.php?title=webapi/place-suggestion-api
不知道是否看出坑的地方在哪里(请参考官方示例 http://echarts.baidu.com/demo.html#map-polygon):
1.js格式的数据不做格式化。这个我勉强可以理解。但是百度地图的demo里面使用的数据可不是这样的。所以这份文件不处理就没*用。至于这个js处理的坑点晚些再说
2.看看右边那个文档。不只是百度,从主要渠道下载的全国行政区划明细列表,都是会对于行政单位加上行政级别——例如北京市,上海市。而不是北京,上海。
3.附上官方示例上的接口API内容:
不多吐槽了。槽点实在太多。
那么进入正题,老样子,先上代码。
代码中有段非re处理的部分,用re的话大概只能写成这样。因为sub模块替换时不支持通配。

完整代码如下:
import re
f = open('D:\Users\50255\Desktop\maplist.txt', encoding='utf-8')
txt = f.read()
# pattern = re.compile(r'"w{2,6}"|d+Wd+Wd+Wd+')
# result = re.findall(pattern, txt)
def test_split(txt, string):
if type(txt) is not str:
txt = ''.join(txt)
txt = re.split(string, txt)
txt = ''.join(txt)
return txt
def test_replace(txt, r, f):
if type(txt) is not str:
txt = ''.join(txt)
txt = re.sub(r, f, txt)
txt = ''.join(txt)
return txt
txt = test_replace(txt, r'{n:"', r'{"')
txt = test_replace(txt, r',g:"', r',"')
txt = test_replace(txt, r'|.{1,2}"}', r'"}')
txt = re.findall(r'{"w+",.{1,30}dd"}', txt)
txt = test_replace(txt, r'{"', r'"')
txt = test_replace(txt, r'","', r'":[')
txt = test_replace(txt, r'"}', r'],
')
txt = test_replace(txt, r'":', r'市":')
txt = test_replace(txt, r'市市', r'市')
txt = test_replace(txt, r'区市', r'区')
txt = test_replace(txt, r'州市', r'州')
_txt = list(txt)
for i in range(len(_txt)):
if _txt[i-1] == '"' and _txt[i+1] == '州':
_txt[i+1] = '州市'
txt = ''.join(_txt)
print(txt)
h = open('D:\Users\50255\Desktop\maplist2.txt', mode='w', encoding='utf-8')
h.write(txt)
因为只是用了一次。所以没有对上面那一堆replace的效率优化。优化的部分只有截图那一块,那个效率实在有点看不下去。
通过内容可以看出需要替换掉的部分。而且为了保证数据的正确处理。按以下步骤执行脚本:
0.初始化
1.去除需要的数据中的键值命名 --- n: g:
2.去除数据中不知道代表什么分类的 |12
3.取出需要的,括号内的数据
4.将数据格式化为目标样式
5.给数据加上行政区划级别
6.对于特殊的城市名称进行处理
7.输出结果
----------------------------------
百度的这份文档,绝对是为了展现程序员的核心价值。
所以你不能用文本编辑器一次性解决这个问题。