-
背景



-
强化学习

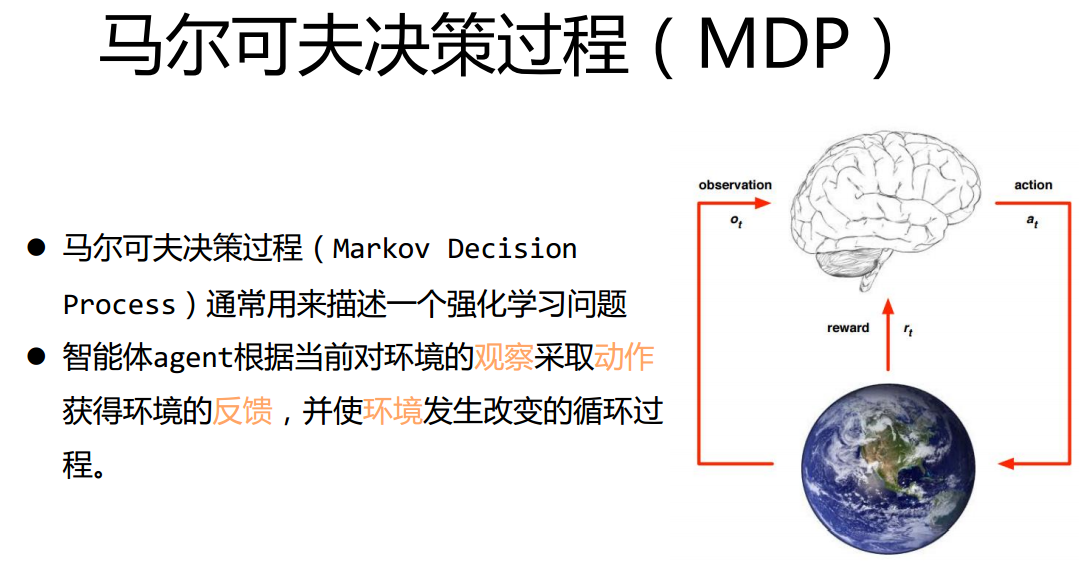
- MDP基本元素



- 这部分比较难懂,没有详细看:最优函数值,最优控制等
-
Q-learning





-
神经网络
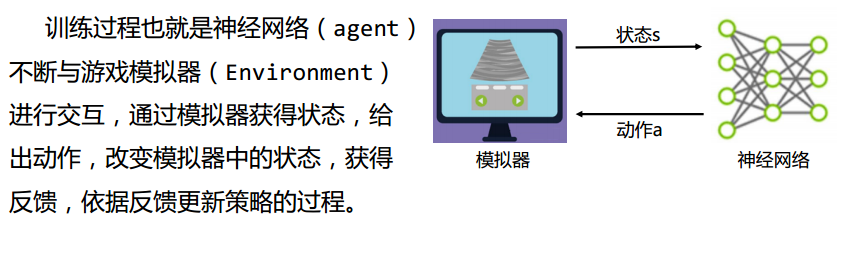

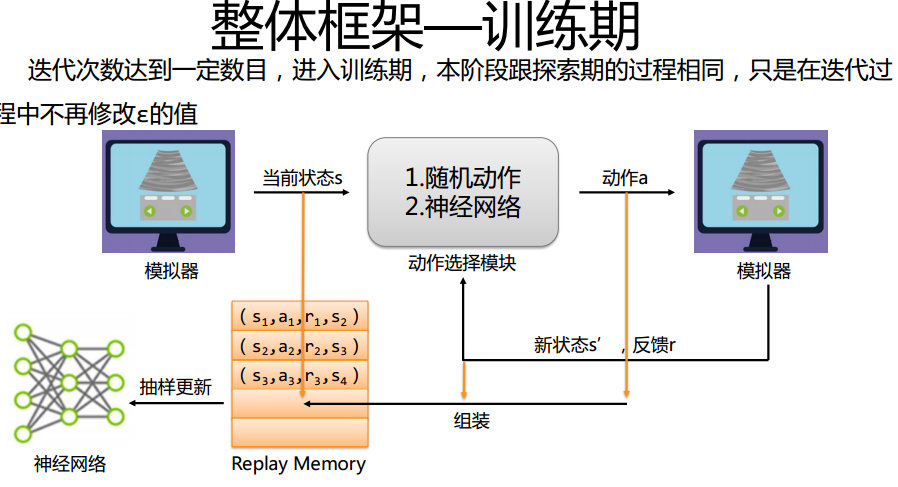
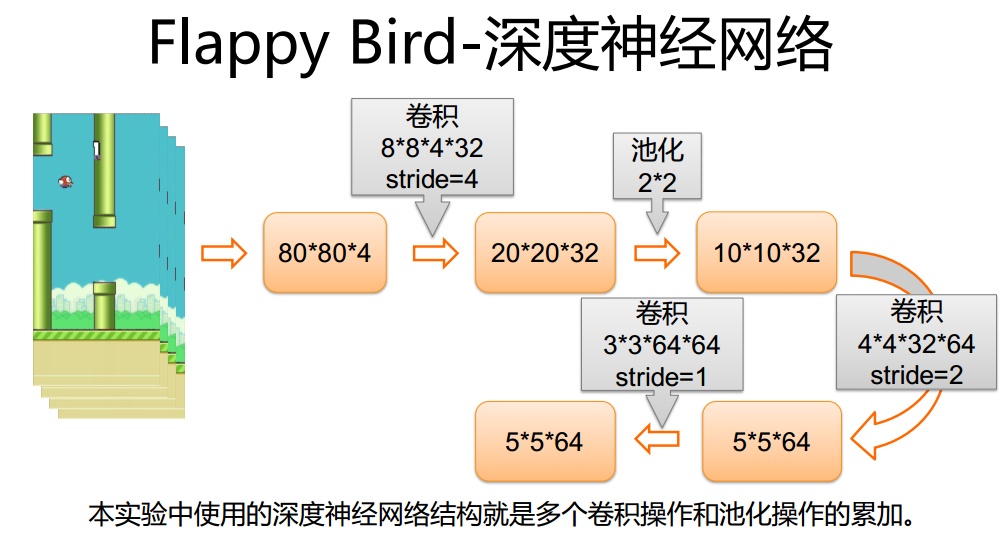
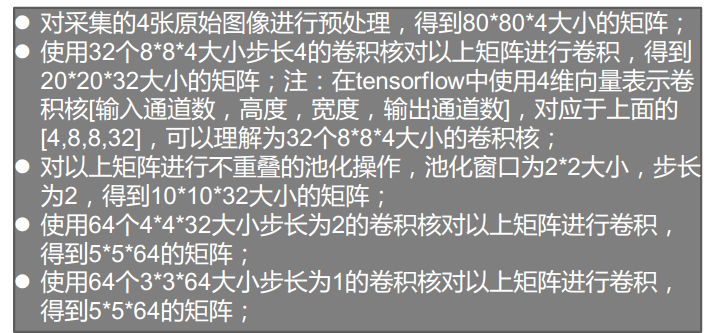
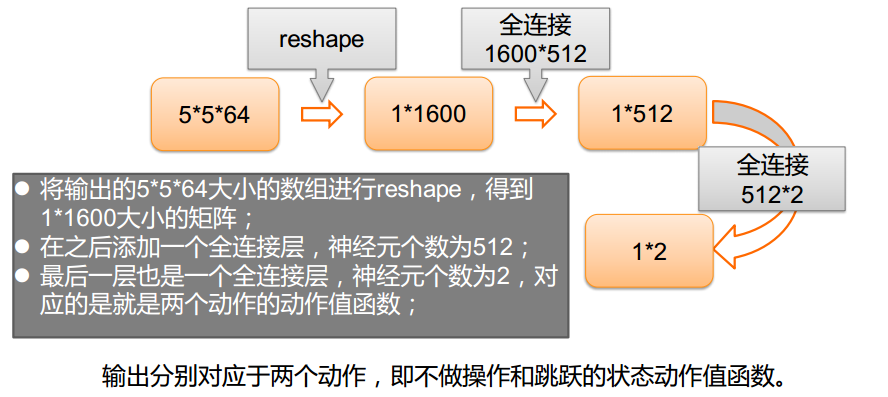
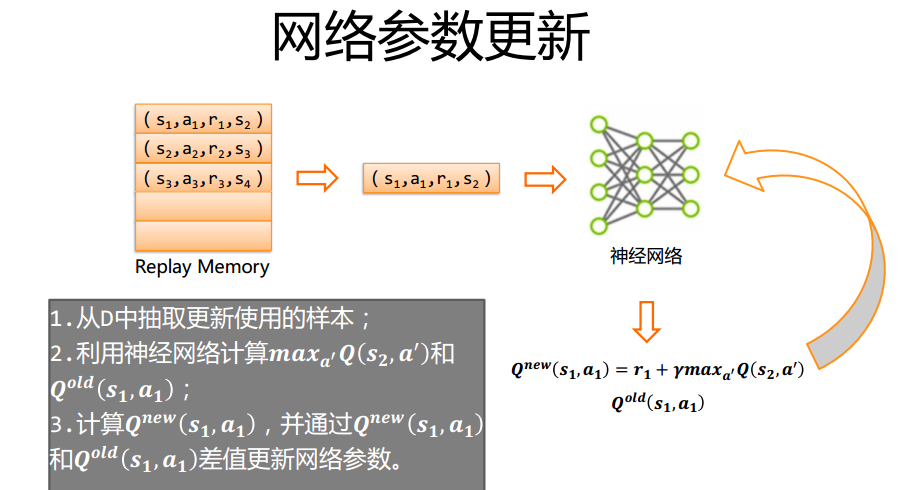
-
环境搭建
- windows下通过pip安装TensorFlow,opencv-python,pygame
-
实验
#!/usr/bin/env python from __future__ import print_function import tensorflow as tf import cv2 import sys sys.path.append("game/") import wrapped_flappy_bird as game import random import numpy as np from collections import deque GAME = 'bird' # the name of the game being played for log files ACTIONS = 2 # number of valid actions GAMMA = 0.99 # decay rate of past observations OBSERVE = 100000. # timesteps to observe before training EXPLORE = 2000000. # frames over which to anneal epsilon FINAL_EPSILON = 0.0001 # final value of epsilon INITIAL_EPSILON = 0.0001 # starting value of epsilon REPLAY_MEMORY = 50000 # number of previous transitions to remember BATCH = 32 # size of minibatch FRAME_PER_ACTION = 1 def weight_variable(shape): initial = tf.truncated_normal(shape, stddev = 0.01) return tf.Variable(initial) def bias_variable(shape): initial = tf.constant(0.01, shape = shape) return tf.Variable(initial) def conv2d(x, W, stride): return tf.nn.conv2d(x, W, strides = [1, stride, stride, 1], padding = "SAME") def max_pool_2x2(x): return tf.nn.max_pool(x, ksize = [1, 2, 2, 1], strides = [1, 2, 2, 1], padding = "SAME") def createNetwork(): # network weights W_conv1 = weight_variable([8, 8, 4, 32]) b_conv1 = bias_variable([32]) W_conv2 = weight_variable([4, 4, 32, 64]) b_conv2 = bias_variable([64]) W_conv3 = weight_variable([3, 3, 64, 64]) b_conv3 = bias_variable([64]) W_fc1 = weight_variable([1600, 512]) b_fc1 = bias_variable([512]) W_fc2 = weight_variable([512, ACTIONS]) b_fc2 = bias_variable([ACTIONS]) # input layer s = tf.placeholder("float", [None, 80, 80, 4]) # hidden layers h_conv1 = tf.nn.relu(conv2d(s, W_conv1, 4) + b_conv1) h_pool1 = max_pool_2x2(h_conv1) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2, 2) + b_conv2) #h_pool2 = max_pool_2x2(h_conv2) h_conv3 = tf.nn.relu(conv2d(h_conv2, W_conv3, 1) + b_conv3) #h_pool3 = max_pool_2x2(h_conv3) #h_pool3_flat = tf.reshape(h_pool3, [-1, 256]) h_conv3_flat = tf.reshape(h_conv3, [-1, 1600]) h_fc1 = tf.nn.relu(tf.matmul(h_conv3_flat, W_fc1) + b_fc1) # readout layer readout = tf.matmul(h_fc1, W_fc2) + b_fc2 return s, readout, h_fc1 def trainNetwork(s, readout, h_fc1, sess): # define the cost function a = tf.placeholder("float", [None, ACTIONS]) y = tf.placeholder("float", [None]) readout_action = tf.reduce_sum(tf.multiply(readout, a), reduction_indices=1) cost = tf.reduce_mean(tf.square(y - readout_action)) train_step = tf.train.AdamOptimizer(1e-6).minimize(cost) # open up a game state to communicate with emulator game_state = game.GameState() # store the previous observations in replay memory D = deque() # printing a_file = open("logs_" + GAME + "/readout.txt", 'w') h_file = open("logs_" + GAME + "/hidden.txt", 'w') # get the first state by doing nothing and preprocess the image to 80x80x4 do_nothing = np.zeros(ACTIONS) do_nothing[0] = 1 x_t, r_0, terminal = game_state.frame_step(do_nothing) x_t = cv2.cvtColor(cv2.resize(x_t, (80, 80)), cv2.COLOR_BGR2GRAY) ret, x_t = cv2.threshold(x_t,1,255,cv2.THRESH_BINARY) s_t = np.stack((x_t, x_t, x_t, x_t), axis=2) # saving and loading networks saver = tf.train.Saver() sess.run(tf.initialize_all_variables()) checkpoint = tf.train.get_checkpoint_state("saved_networks") if checkpoint and checkpoint.model_checkpoint_path: saver.restore(sess, checkpoint.model_checkpoint_path) print("Successfully loaded:", checkpoint.model_checkpoint_path) else: print("Could not find old network weights") # start training epsilon = INITIAL_EPSILON t = 0 while "flappy bird" != "angry bird": # choose an action epsilon greedily readout_t = readout.eval(feed_dict={s : [s_t]})[0] a_t = np.zeros([ACTIONS]) action_index = 0 if t % FRAME_PER_ACTION == 0: if random.random() <= epsilon: print("----------Random Action----------") action_index = random.randrange(ACTIONS) a_t[random.randrange(ACTIONS)] = 1 else: action_index = np.argmax(readout_t) a_t[action_index] = 1 else: a_t[0] = 1 # do nothing # scale down epsilon if epsilon > FINAL_EPSILON and t > OBSERVE: epsilon -= (INITIAL_EPSILON - FINAL_EPSILON) / EXPLORE # run the selected action and observe next state and reward x_t1_colored, r_t, terminal = game_state.frame_step(a_t) x_t1 = cv2.cvtColor(cv2.resize(x_t1_colored, (80, 80)), cv2.COLOR_BGR2GRAY) ret, x_t1 = cv2.threshold(x_t1, 1, 255, cv2.THRESH_BINARY) x_t1 = np.reshape(x_t1, (80, 80, 1)) #s_t1 = np.append(x_t1, s_t[:,:,1:], axis = 2) s_t1 = np.append(x_t1, s_t[:, :, :3], axis=2) # store the transition in D D.append((s_t, a_t, r_t, s_t1, terminal)) if len(D) > REPLAY_MEMORY: D.popleft() # only train if done observing if t > OBSERVE: # sample a minibatch to train on minibatch = random.sample(D, BATCH) # get the batch variables s_j_batch = [d[0] for d in minibatch] a_batch = [d[1] for d in minibatch] r_batch = [d[2] for d in minibatch] s_j1_batch = [d[3] for d in minibatch] y_batch = [] readout_j1_batch = readout.eval(feed_dict = {s : s_j1_batch}) for i in range(0, len(minibatch)): terminal = minibatch[i][4] # if terminal, only equals reward if terminal: y_batch.append(r_batch[i]) else: y_batch.append(r_batch[i] + GAMMA * np.max(readout_j1_batch[i])) # perform gradient step train_step.run(feed_dict = { y : y_batch, a : a_batch, s : s_j_batch} ) # update the old values s_t = s_t1 t += 1 # save progress every 10000 iterations if t % 10000 == 0: saver.save(sess, 'saved_networks/' + GAME + '-dqn', global_step = t) # print info state = "" if t <= OBSERVE: state = "observe" elif t > OBSERVE and t <= OBSERVE + EXPLORE: state = "explore" else: state = "train" print("TIMESTEP", t, "/ STATE", state, "/ EPSILON", epsilon, "/ ACTION", action_index, "/ REWARD", r_t, "/ Q_MAX %e" % np.max(readout_t)) # write info to files ''' if t % 10000 <= 100: a_file.write(",".join([str(x) for x in readout_t]) + ' ') h_file.write(",".join([str(x) for x in h_fc1.eval(feed_dict={s:[s_t]})[0]]) + ' ') cv2.imwrite("logs_tetris/frame" + str(t) + ".png", x_t1) ''' def playGame(): sess = tf.InteractiveSession() s, readout, h_fc1 = createNetwork() trainNetwork(s, readout, h_fc1, sess) def main(): playGame() if __name__ == "__main__": main()
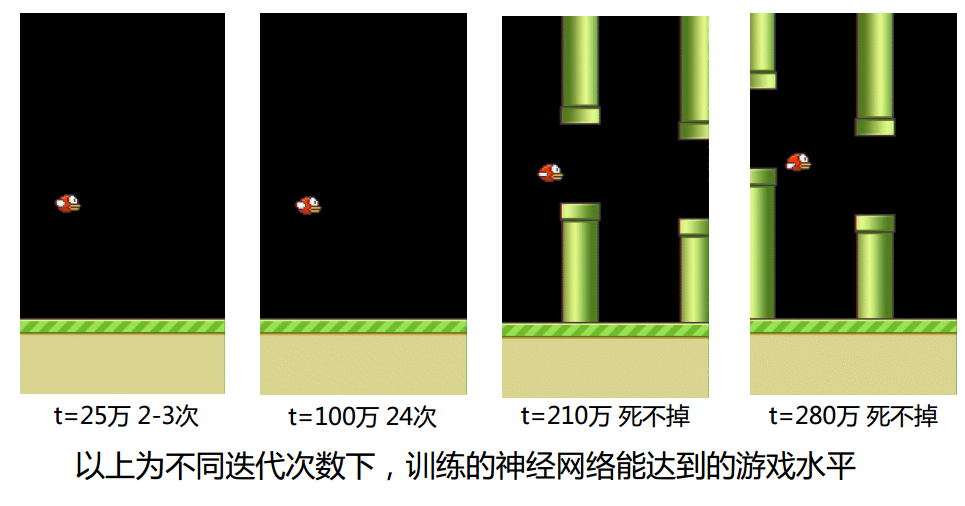
- https://github.com/yenchenlin/DeepLearningFlappyBird