Tensorflow中之前主要用的数据读取方式主要有:
- 建立placeholder,然后使用feed_dict将数据feed进placeholder进行使用。使用这种方法十分灵活,可以一下子将所有数据读入内存,然后分batch进行feed;也可以建立一个Python的generator,一个batch一个batch的将数据读入,并将其feed进placeholder。这种方法很直观,用起来也比较方便灵活jian,但是这种方法的效率较低,难以满足高速计算的需求。
- 使用TensorFlow的QueueRunner,通过一系列的Tensor操作,将磁盘上的数据分批次读入并送入模型进行使用。这种方法效率很高,但因为其牵涉到Tensor操作,不够直观,也不方便调试,所有有时候会显得比较困难。使用这种方法时,常用的一些操作包括tf.TextLineReader,tf.FixedLengthRecordReader以及tf.decode_raw等等。如果需要循环,条件操作,还需要使用TensorFlow的tf.while_loop,tf.case等操作。
-
Tensorflow API: tf.data.Dataset使用: https://blog.csdn.net/ssmixi/article/details/80572813
---参考:https://github.com/titu1994/neural-image-assessment/blob/master/utils/data_loader.py
https://github.com/arieszhang1994/NIMA/blob/master/train_tf.py

## dataloader实现 - (Pytorch)本身Pytorch数据处理比较规范:先定义Datasets类,初始化时生成list,实现__getitem__进行读取元素,并进行预处理操作,是一个可迭代对象;Dataloader类也是可迭代对象,iter(Dataloader)可实现next()访问,多线程加速batch data的处理,使用yield来使用有限的内存;内部还有queue操作; - (通用)读数据最直接的方法:先准备所有样本list(image_name,image_label),在一个epoch中,shuffle后;依次按照index = (每个epoch进行迭代的次数len(list)/batch_size)*batch_size + j(当前batch的第j个文件),这样来读取一张图,做预处理,收集满一个batch的数据;然后在喂进网络训练;(reference: https://github.com/GeorgeSeif/Semantic-Segmentation-Suite/blob/master/train.py ;https://github.com/joelthchao/tensorflow-finetune-flickr-style/blob/master/dataset.py),https://github.com/dgurkaynak/tensorflow-cnn-finetune/blob/master/utils/preprocessor.py]; 这样读取数据的正本多少呢? - (Caffe)第二步非常慢:可以参考caffe自定义数据层:https://www.cnblogs.com/ranjiewen/p/9903826.html;该方式进行多进程读取数据process; - Tensorflow读取数据方式:
- https://github.com/DrSleep/tensorflow-deeplab-resnet/blob/master/deeplab_resnet/image_reader.py
- Tensorflow学习笔记:CNN篇(10)——Finetuning,猫狗大战,VGGNet的重新针对训练:https://blog.csdn.net/laurenitum0716/article/details/79327156
上面链接的方式是通过tf.train.slice_input_producer()直接读取文件list, tf.train.slice_input_producer()也可以读取tfrecords文件;
self.image_list, self.label_list = read_labeled_image_list(self.data_dir, self.data_list) self.images = tf.convert_to_tensor(self.image_list, dtype=tf.string) self.labels = tf.convert_to_tensor(self.label_list, dtype=tf.string) self.queue = tf.train.slice_input_producer([self.images, self.labels], shuffle=input_size is not None) # not shuffling if it is val self.image, self.label = read_images_from_disk(self.queue, self.input_size, random_scale, random_mirror, ignore_label, img_mean) image_batch, label_batch = tf.train.batch([self.image, self.label], num_elements)
一、tensorflow读取机制图解
首先需要思考的一个问题是,什么是数据读取?以图像数据为例,读取数据的过程可以用下图来表示:
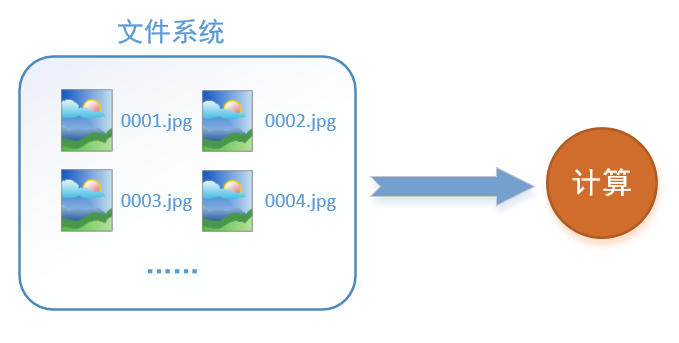
假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg……我们只需要把它们读取到内存中,然后提供给GPU或是CPU进行计算就可以了。这听起来很容易,但事实远没有那么简单。事实上,我们必须要把数据先读入后才能进行计算,假设读入用时0.1s,计算用时0.9s,那么就意味着每过1s,GPU都会有0.1s无事可做,这就大大降低了运算的效率。
如何解决这个问题?方法就是将读入数据和计算分别放在两个线程中,将数据读入内存的一个队列,如下图所示:
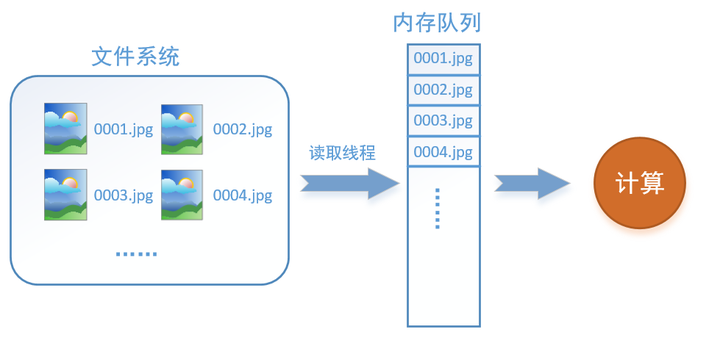
读取线程源源不断地将文件系统中的图片读入到一个内存的队列中,而负责计算的是另一个线程,计算需要数据时,直接从内存队列中取就可以了。这样就可以解决GPU因为IO而空闲的问题!
而在tensorflow中,为了方便管理,在内存队列前又添加了一层所谓的“文件名队列”。
为什么要添加这一层文件名队列?我们首先得了解机器学习中的一个概念:epoch。对于一个数据集来讲,运行一个epoch就是将这个数据集中的图片全部计算一遍。如一个数据集中有三张图片A.jpg、B.jpg、C.jpg,那么跑一个epoch就是指对A、B、C三张图片都计算了一遍。两个epoch就是指先对A、B、C各计算一遍,然后再全部计算一遍,也就是说每张图片都计算了两遍。
tensorflow使用文件名队列+内存队列双队列的形式读入文件,可以很好地管理epoch。下面我们用图片的形式来说明这个机制的运行方式。如下图,还是以数据集A.jpg, B.jpg, C.jpg为例,假定我们要跑一个epoch,那么我们就在文件名队列中把A、B、C各放入一次,并在之后标注队列结束。
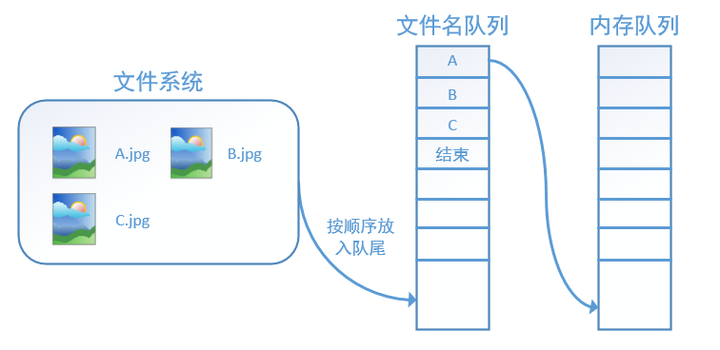
程序运行后,内存队列首先读入A(此时A从文件名队列中出队):再依次读入B和C:
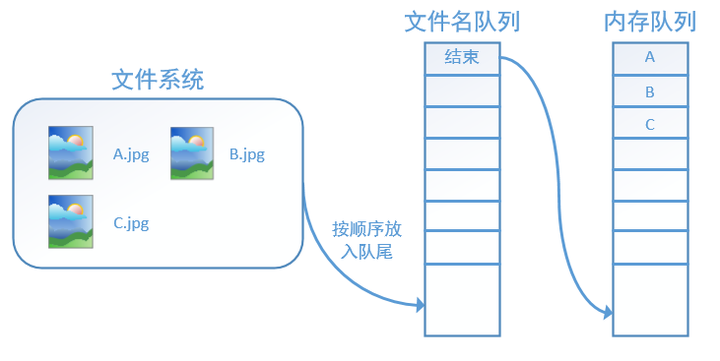
此时,如果再尝试读入,系统由于检测到了“结束”,就会自动抛出一个异常(OutOfRange)。外部捕捉到这个异常后就可以结束程序了。这就是tensorflow中读取数据的基本机制。如果我们要跑2个epoch而不是1个epoch,那只要在文件名队列中将A、B、C依次放入两次再标记结束就可以了。
二、tensorflow读取数据机制的对应函数
如何在tensorflow中创建上述的两个队列呢?
对于文件名队列,我们使用tf.train.string_input_producer函数。这个函数需要传入一个文件名list,系统会自动将它转为一个文件名队列。
此外tf.train.string_input_producer还有两个重要的参数,一个是num_epochs,它就是我们上文中提到的epoch数。另外一个就是shuffle,shuffle是指在一个epoch内文件的顺序是否被打乱。若设置shuffle=False,如下图,每个epoch内,数据还是按照A、B、C的顺序进入文件名队列,这个顺序不会改变:
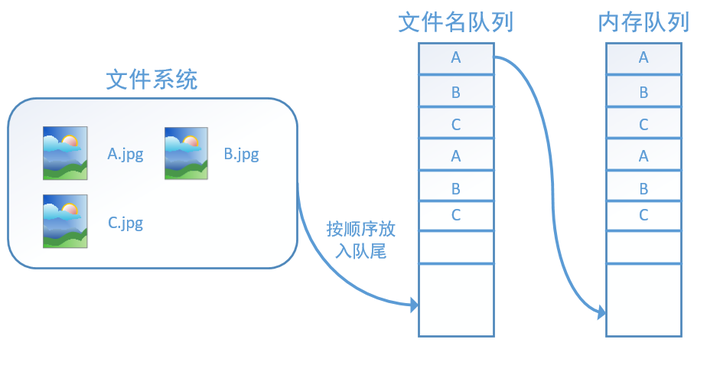
如果设置shuffle=True,那么在一个epoch内,数据的前后顺序就会被打乱,如下图所示:
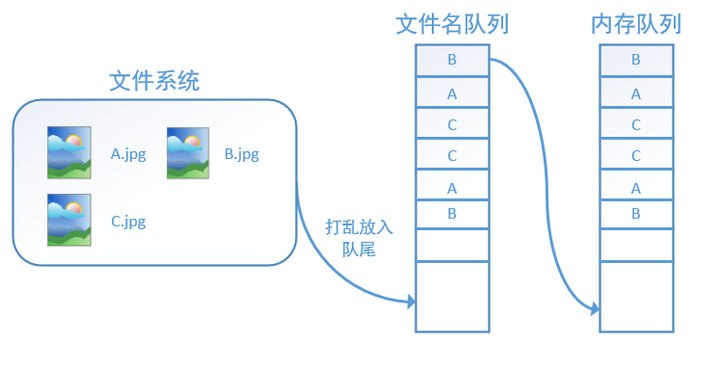
在tensorflow中,内存队列不需要我们自己建立,我们只需要使用reader对象从文件名队列中读取数据就可以了,具体实现可以参考下面的实战代码。
除了tf.train.string_input_producer外,我们还要额外介绍一个函数:tf.train.start_queue_runners。初学者会经常在代码中看到这个函数,但往往很难理解它的用处,在这里,有了上面的铺垫后,我们就可以解释这个函数的作用了。
在我们使用tf.train.string_input_producer创建文件名队列后,整个系统其实还是处于“停滞状态”的,也就是说,我们文件名并没有真正被加入到队列中(如下图所示)。此时如果我们开始计算,因为内存队列中什么也没有,计算单元就会一直等待,导致整个系统被阻塞。
而使用tf.train.start_queue_runners之后,才会启动填充队列的线程,这时系统就不再“停滞”。此后计算单元就可以拿到数据并进行计算,整个程序也就跑起来了,这就是函数tf.train.start_queue_runners的用处。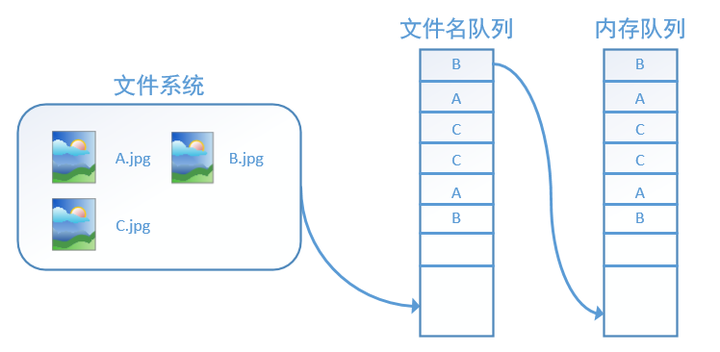
- 主要区别几个函数的使用方法:
- tf.train.slice_input_producer(): slice_input_producer(tensor_list, num_epochs=None, shuffle=True, seed=None,
capacity=32, shared_name=None, name=None)
tf.train.slice_input_producer是一个tensor生成器,作用是按照设定,每次从一个tensor列表中按顺序或者随机抽取出一个tensor放入文件名队列。
第一个参数 tensor_list:包含一系列tensor的列表,表中tensor的第一维度的值必须相等,即个数必须相等,有多少个图像,就应该有多少个对应的标签。 第二个参数num_epochs: 可选参数,是一个整数值,代表迭代的次数,如果设置 num_epochs=None,生成器可以无限次遍历tensor列表,如果设置为 num_epochs=N,生成器只能遍历tensor列表N次。 第三个参数shuffle: bool类型,设置是否打乱样本的顺序。一般情况下,如果shuffle=True,生成的样本顺序就被打乱了,在批处理的时候不需要再次打乱样本,使用 tf.train.batch函数就可以了;如果shuffle=False,就需要在批处理时候使用 tf.train.shuffle_batch函数打乱样本。 第四个参数seed: 可选的整数,是生成随机数的种子,在第三个参数设置为shuffle=True的情况下才有用。 第五个参数capacity:设置tensor列表的容量。 第六个参数shared_name:可选参数,如果设置一个‘shared_name’,则在不同的上下文环境(Session)中可以通过这个名字共享生成的tensor。 第七个参数name:可选,设置操作的名称。
- 使用tf.train.string_input_producer()
"""Output strings (e.g. filenames) to a queue for an input pipeline. Note: if `num_epochs` is not `None`, this function creates local counter `epochs`. Use `local_variables_initializer()` to initialize local variables. Args: string_tensor: A 1-D string tensor with the strings to produce. num_epochs: An integer (optional). If specified, `string_input_producer` produces each string from `string_tensor` `num_epochs` times before generating an `OutOfRange` error. If not specified, `string_input_producer` can cycle through the strings in `string_tensor` an unlimited number of times. shuffle: Boolean. If true, the strings are randomly shuffled within each epoch. seed: An integer (optional). Seed used if shuffle == True. capacity: An integer. Sets the queue capacity. shared_name: (optional). If set, this queue will be shared under the given name across multiple sessions. All sessions open to the device which has this queue will be able to access it via the shared_name. Using this in a distributed setting means each name will only be seen by one of the sessions which has access to this operation. name: A name for the operations (optional). cancel_op: Cancel op for the queue (optional). Returns: A queue with the output strings. A `QueueRunner` for the Queue is added to the current `Graph`'s `QUEUE_RUNNER` collection.
- tf.train.batch(): tf.train.batch是一个tensor队列生成器,作用是按照给定的tensor顺序,把batch_size个tensor推送到文件队列,作为训练一个batch的数据,等待tensor出队执行计算。
batch(tensors, batch_size, num_threads=1, capacity=32, enqueue_many=False, shapes=None, dynamic_pad=False, allow_smaller_final_batch=False, shared_name=None, name=None)
第一个参数tensors:tensor序列或tensor字典,可以是含有单个样本的序列;
第二个参数batch_size: 生成的batch的大小;
第三个参数num_threads:执行tensor入队操作的线程数量,可以设置使用多个线程同时并行执行,提高运行效率,但也不是数量越多越好;
第四个参数capacity: 定义生成的tensor序列的最大容量;
第五个参数enqueue_many: 定义第一个传入参数tensors是多个tensor组成的序列,还是单个tensor;
第六个参数shapes: 可选参数,默认是推测出的传入的tensor的形状;
第七个参数dynamic_pad: 定义是否允许输入的tensors具有不同的形状,设置为True,会把输入的具有不同形状的tensor归一化到相同的形状;
第八个参数allow_smaller_final_batch: 设置为True,表示在tensor队列中剩下的tensor数量不够一个batch_size的情况下,允许最后一个batch的数量少于batch_size, 设置为False,则不管什么情况下,生成的batch都拥有batch_size个样本;
第九个参数shared_name: 可选参数,设置生成的tensor序列在不同的Session中的共享名称;
第十个参数name: 操作的名称;
# -*- coding:utf-8 -*- import tensorflow as tf import numpy as np # 样本个数 sample_num=5 # 设置迭代次数 epoch_num = 2 # 设置一个批次中包含样本个数 batch_size = 3 # 计算每一轮epoch中含有的batch个数 batch_total = int(sample_num/batch_size)+1 # 生成4个数据和标签 def generate_data(sample_num=sample_num): labels = np.asarray(range(0, sample_num)) images = np.random.random([sample_num, 224, 224, 3]) print('image size {},label size :{}'.format(images.shape, labels.shape)) return images,labels def get_batch_data(batch_size=batch_size): images, label = generate_data() # 数据类型转换为tf.float32 images = tf.cast(images, tf.float32) label = tf.cast(label, tf.int32) #从tensor列表中按顺序或随机抽取一个tensor input_queue = tf.train.slice_input_producer([images, label], shuffle=False) image_batch, label_batch = tf.train.batch(input_queue, batch_size=batch_size, num_threads=1, capacity=64) return image_batch, label_batch image_batch, label_batch = get_batch_data(batch_size=batch_size) with tf.Session() as sess: coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess, coord) try: for i in range(epoch_num): # 每一轮迭代 print '************' for j in range(batch_total): #每一个batch print '--------' # 获取每一个batch中batch_size个样本和标签 image_batch_v, label_batch_v = sess.run([image_batch, label_batch]) # for k in print(image_batch_v.shape, label_batch_v) except tf.errors.OutOfRangeError: print("done") finally: coord.request_stop() coord.join(threads)