最近BI同事反馈说一张表的数据查询非常慢,这个表数据总共不到1W行数据,这么一说我们首先想到的是高水位带来的性能问题,即高水位线下占用过多数据块,而这些数据块其实是部分数据占用,大多数是空闲的数据块。
我们知道高水位线下的数据块在全表扫描时都要做,所以扫描的数据块可能远远多于实际的存数据的数据块。
一、表统计信息收集
要想得到准确的高水位信息,必须先收集统计信息,这样得到的才相对比较准确。
ANALYZE TABLE table_name ESTIMATE STATISTICS; ANALYZE TABLE table_name COMPUTE STATISTICS FOR TABLE FOR ALL INDEXES FOR ALL INDEXED COLUMNS; execute dbms_stats.gather_table_stats(ownname => 'OWNER', tabname => 'TABLE_NAME' , estimate_percent => null ,method_opt => 'for all indexed columns' ,cascade => true);
二、表信息查看
查看表的块、行信息
select t.TABLE_NAME,t.NUM_ROWS,t.BLOCKS,t.empty_blocks,t.LAST_ANALYZED from dba_tables t where table_name in ('TABLE_NAME'); SELECT COUNT(DISTINCT DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)) USED_BLOCK FROM TABLE_NAME;


上述查询结果显示,当前表行数是9651行,有716119个数据块被使用(HWM下的数据块),有0个未使用的数据块(HWM上的数据块)
实际数据占用的数据块数量为:152
综合可以看出,高水位线下其实有716119-152个数据块可以释放,这样每次全表扫描只需要扫描152个数据块即可。
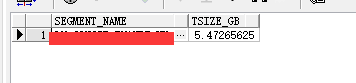
通过查看段大小佐证记录数和表大小关系是否一致,通过下面的查看段大小为5.5G,记录9651行几乎不可能达到这个大小,所以基本可以断定个里面有很多空闲的块。
select segment_name,bytes/1024/1024/1024 TSize_GB from dba_segments where segment_name='table_name' ---5876219904
三、问题原因
什么情况会导致上面的问题呢,即高水位下存在很多未使用的数据块?一般是大表(插入很多记录后),经过批量删除delete操作,未释放高水位导致的。
1.全表扫描要读取高水位线下的所有数据块,无论是否含有数据。
2.如果在插入数据的时候使用了append关键字,即使高水位线下有空闲的数据库,也会从高水位线上面的数据库做分配,也就是高水位线会上升。
四、降低高水位方法
1. alter table table_name move;
此方法可释放高水位,但需要重建索引
2.alter table table_name shrink space;
此方法可释放高水位,但执行前需要开启行移动,alter table table_name enable row movement;
3.emp/imp的方式重建表数据
4.drop/create方式重建表
5.truncate表
6.alter table table_name deallocate unused
DEALLOCATE UNUSED为释放HWM上面的未使用空间,但是并不会释放HWM下面的自由空间,也不会移动HWM的位置.
五、高水位调整实施
1.统计信息收集(如上)
2.执行计划查看
SQL> set autotrace trace ; SQL> set timing on; SQL> SELECT count(*) FROM TABLE_NAME;

3.表移动
alter table table_name move;
报错:ORA-00054: resource busy and acquire with NOWAIT specified or timeout expired 查看被锁对象: select object_name,machine,s.sid,s.serial# from v$locked_object l,dba_objects o ,v$session s where l.object_id = o.object_id and l.session_id=s.sid;
执行后再查看执行计划统计信息
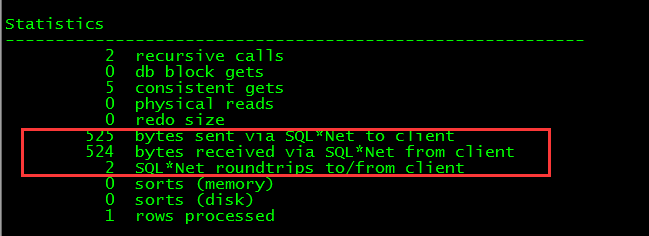
看到统计信息访问的数据块已经降下来了,然后执行全表扫描,速度也是飞快。
4.索引重建
alter index index_name rebuild online;
六、库高水位对象统计
①比较表的行数和表的大小关系。如果行数为0,而表的当前占用大小减去初始化时的大小(INITIAL_EXTENT)后依然很大,那么说明该表有高水位。
②行数和块数的比率,即查看一个块可以存储多少行数据。如果一个块存储的行数少于5行甚至更少,那么说明有高水位。注意,这两种方法都不是十分准确,需要再对查询结果进行筛选。需要注意的是,在查询表的高水位时,首先需要分析表,以得到最准确的统计信息。
SELECT D.OWNER, ROUND(D.NUM_ROWS / D.BLOCKS, 2), D.NUM_ROWS, D.BLOCKS, D.TABLE_NAME, ROUND((d.BLOCKS*8-D.INITIAL_EXTENT/1024)/1024) t_size FROM DBA_TABLES D WHERE D.BLOCKS > 10 AND ROUND(D.NUM_ROWS / D.BLOCKS, 2) < 5 AND d.OWNER NOT LIKE '%SYS%' ; 或: SELECT OWNER, SEGMENT_NAME TABLE_NAME, SEGMENT_TYPE, GREATEST(ROUND(100 * (NVL(HWM - AVG_USED_BLOCKS, 0) / GREATEST(NVL(HWM, 1), 1)), 2), 0) WASTE_PER FROM (SELECT A.OWNER OWNER, A.SEGMENT_NAME, A.SEGMENT_TYPE, B.LAST_ANALYZED, A.BYTES, B.NUM_ROWS, A.BLOCKS BLOCKS, B.EMPTY_BLOCKS EMPTY_BLOCKS, A.BLOCKS - B.EMPTY_BLOCKS - 1 HWM, DECODE(ROUND((B.AVG_ROW_LEN * NUM_ROWS * (1 + (PCT_FREE / 100))) / C.BLOCKSIZE, 0), 0, 1, ROUND((B.AVG_ROW_LEN * NUM_ROWS * (1 + (PCT_FREE / 100))) / C.BLOCKSIZE, 0)) + 2 AVG_USED_BLOCKS, ROUND(100 * (NVL(B.CHAIN_CNT, 0) / GREATEST(NVL(B.NUM_ROWS, 1), 1)), 2) CHAIN_PER, B.TABLESPACE_NAME O_TABLESPACE_NAME FROM SYS.DBA_SEGMENTS A, SYS.DBA_TABLES B, SYS.TS$ C WHERE A.OWNER = B.OWNER AND SEGMENT_NAME = TABLE_NAME AND SEGMENT_TYPE = 'TABLE' AND B.TABLESPACE_NAME = C.NAME) WHERE GREATEST(ROUND(100 * (NVL(HWM - AVG_USED_BLOCKS, 0) / GREATEST(NVL(HWM, 1), 1)), 2), 0) > 50 AND OWNER NOT LIKE '%SYS%' AND BLOCKS > 100 ORDER BY WASTE_PER DESC;