一、第一种初始化簇中心的方法:随机产生k个簇中心,保证簇中心的每个维度的取值都在这个纬度所有值的最小值与最大值的左闭右开区间内
import numpy as np class KMeans_1: def __init__(self,k_clusters,tol=1e-4,max_iter=300): self.k_clusters=k_clusters self.tol=tol self.max_iter=max_iter #生成随机的k个聚类中心,每个维度都在最小最大值范围内 def _init_centers_random(self,X,k_clusters): _,n=X.shape xmin=np.min(X,axis=0) xmax=np.max(X,axis=0) return xmin+(xmax-xmin)*np.random.rand(k_clusters,n) def _kmeans(self,X): '''K-Means核心算法''' m,n=X.shape #label存储对每一个实例的划分标记 labels=np.zeros(m,dtype=np.int) #distance为m*k的矩阵,表示每个样本到每个簇中心的距离 distances = np.empty((m,self.k_clusters)) #centers_old存储之前的质心点 centers_old = np.empty((self.k_clusters,n)) #初始化簇中心 centers=self._init_centers_random(X,self.k_clusters) for _ in range(self.max_iters): #1、分类标签 for i in range(self.k_clusters): #计算m个实例到质心点的距离 np.sum((X-centers[i])**2,axis=1,out=distances[:,i]) #将m个实例划分到距离最小的那个类中 np.argmin(distances,axis=1,out=labels) #2、计算质心点 #保存之前的质心点 np.copyto(centers_old,centers) for i in range(self.k_clusters): cluster = X[labels==i] if cluster.size==0: return None #计算新的簇中心 np.mean(cluster,axis=0,out=centers[i]) #3、判断是否收敛,求每个簇中心与原来的位置的距离和 delta_centers = np.sqrt(np.sum((centers-centers_old)**2,axis=1)) #每个簇中心点的变化都小于阈值 if np.all(delta_centers < self.tol): break #计算簇内误差平方和 sse=np.sum(distances[range(m),labels]) return labels,centers def predict(self,X): res = None while not res: res=self._kmeans(X) labels,self.centers_= res return labels
二、第二种K-Means算法,初始化簇中心的时候使用了概率模型,能够选出k个相聚较远的点。在这个算法中,我们通过十次有效的划分,计算出最少的损失函数SSE的值,将这个值对应的分类返回
import numpy as np class KMeans_2: def __init__(self,k_clusters,tol=1e-4,max_iter=300,n_init=10): self.k_clusters=k_clusters self.tol=tol self.max_iter=max_iter self.n_init = n_init def _init_centers_kpp(self,X,n_clusters): '''k-means++核心初始化算法''' m,n=X.shape #第一个点是随机产生的,所以只需要计算n_clusters-1个点 distances = np.empty((m,n_clusters-1)) centers=np.empty((n_clusters,n)) #随机产生一个[0,m-1]的下标,将这个样本作为第一个聚类中心点 np.copyto(centers[0],X[np.random.randint(m)]) for j in range(1,n_clusters): for i in range(j): np.sum((X-centers[j])**2,axis=1,out=distances[:,i]) #计算各点到最近质心点的距离平方 nds=np.min(distances[:,:j],axis=1) #1、以各点到最近质心的距离平方构成的加权概率进行分布,产生下一簇质心点 r=np.sum(nds)*np.random.random() #2、判断概率点落入那个区域,对应的样本就是簇中心 for k in range(m): r-=nds[k] if r < 0: break np.copyto(centers[j],X[k]) return centers def _kmeans(self,X): '''K-Means++核心算法''' m,n=X.shape #label存储对每一个实例的划分标记 labels=np.zeros(m,dtype=np.int) #distance为m*k的矩阵,表示每个样本到每个簇中心的距离 distances = np.empty((m,self.k_clusters)) #centers_old存储之前的质心点 centers_old = np.empty((self.k_clusters,n)) #初始化簇中心 centers=self._init_centers_kpp(X,self.k_clusters) for _ in range(self.max_iter): #1、分类标签 for i in range(self.k_clusters): #计算m个实例到质心点的距离 np.sum((X-centers[i])**2,axis=1,out=distances[:,i]) #将m个实例划分到距离最小的那个类中 np.argmin(distances,axis=1,out=labels) #2、计算质心点 #保存之前的质心点 np.copyto(centers_old,centers) for i in range(self.k_clusters): cluster = X[labels==i] if cluster.size==0: return None #计算新的簇中心 np.mean(cluster,axis=0,out=centers[i]) #3、判断是否收敛,求每个簇中心与原来的位置的距离和 delta_centers = np.sqrt(np.sum((centers-centers_old)**2,axis=1)) #每个簇中心点的变化都小于阈值 if np.all(delta_centers < self.tol): break #计算簇内误差平方和 sse=np.sum(distances[range(m),labels]) return labels,centers,sse def predict(self,X): result = np.empty((self.n_init,3),dtype=np.object) #运行self.n_init次 for i in range(self.n_init): #调用self.k_means直到成功 res = None while res is None: res=self._kmeans(X) result[i]=res #选出sse最小的分类结果 k=np.argmin(result[:,-1]) labels,self.centers_,sse_ = result[k] return labels
三、加载数据
数据来源
http://archive.ics.uci.edu/ml/machine-learning-databases/00236/
import numpy as np X=np.genfromtxt('F:/python_test/data/seeds_dataset.txt',usecols=range(7)) print(X) labels=np.genfromtxt('F:/python_test/data/seeds_dataset.txt',usecols=7,dtype=np.int) print(labels)

三类标签分别有七十个
print(labels[:70]) print(labels[70:140]) print(labels[140:210])

kmeans=KMeans_2(3) label_pred=kmeans.predict(X) print(label_pred)
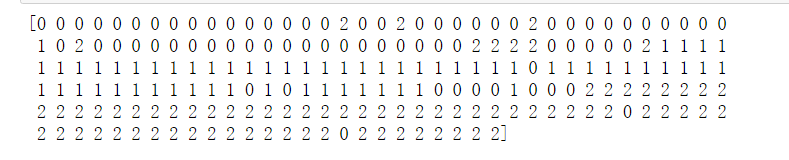
大体上分成了三类,但是效果怎么样还有待评估,使用ARI指标进行评估,
from sklearn.metrics import adjusted_rand_score ari=adjusted_rand_score(labels,label_pred) print(ari)
得到ARI=0.7166198557361053
再考察外部指标FM
from sklearn.metrics import fowlkes_mallows_score fm=fowlkes_mallows_score(labels,label_pred) print(fm)

性能可以说还不错,我们紧接着对每个属性的取值都标准化再使用K-means算法
from sklearn .preprocessing import StandardScaler ss=StandardScaler() X_std=ss.fit_transform(X) kmeans = KMeans_2(3) label_pred=kmeans.predict(X_std) ari=adjusted_rand_score(labels,label_pred) print(ari) fm=fowlkes_mallows_score(labels,label_pred) print(fm)

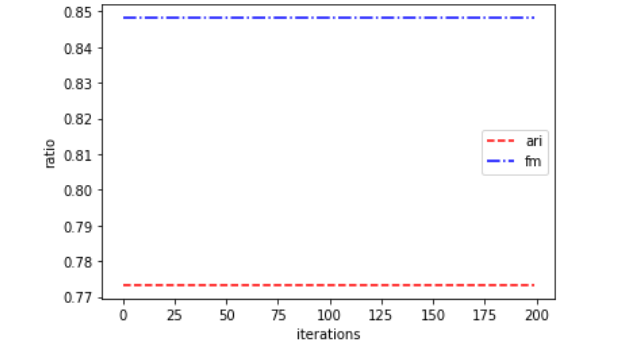
可见ARI指标和FM指标分别提高到了77.3%和84.8%
下面测试一下上述两种算法的能力
第一种:
w=range(200) ari_arr=[] fm_arr=[] import matplotlib matplotlib.use('TkAgg') import matplotlib.pyplot as plt for i in w: ss=StandardScaler() X_std=ss.fit_transform(X) kmeans = KMeans_1(3) label_pred=kmeans.predict(X_std) ari=adjusted_rand_score(labels,label_pred) ari_arr.append(ari) fm=fowlkes_mallows_score(labels,label_pred) fm_arr.append(fm) plt.plot(w,ari_arr,label='ari',linestyle='--',color='red') plt.plot(w,fm_arr,label='fm',linestyle='-.',color='blue') plt.show()
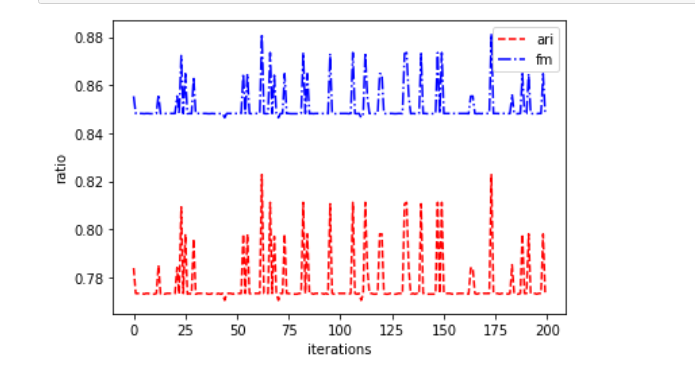
可以发现平均下来还是很不错的
第二种:(非常稳定,但是好像没有上面第一种方法好)
w=range(200) ari_arr=[] fm_arr=[] import matplotlib matplotlib.use('TkAgg') import matplotlib.pyplot as plt for i in w: ss=StandardScaler() X_std=ss.fit_transform(X) kmeans = KMeans_2(3) label_pred=kmeans.predict(X_std) ari=adjusted_rand_score(labels,label_pred) ari_arr.append(ari) fm=fowlkes_mallows_score(labels,label_pred) fm_arr.append(fm) plt.plot(w,ari_arr,label='ari',linestyle='--',color='red') plt.plot(w,fm_arr,label='fm',linestyle='-.',color='blue') plt.xlabel('iterations') plt.ylabel('ratio') plt.legend() plt.show()