在微服务、云计算和无服务架构时代,理解Kubernetes并且知道如何使用它是十分有用的。然而,官方的Kubernetes文档对于刚开始接触云计算的用户来说有些难以理解。在本文中,我们将了解在Kubernetes中的重要概念。在之后的系列文章中,我们还将了解如何写配置文件、使用Helm作为软件包管理器、创建一个云基础架构、使用Kubernetes轻松编排服务并且创建一个CI/CD流水线来自动化整个工作流。有了这些信息,你可以启动任意种类的项目,并且创建一个强大的基础架构。
首先,我们知道使用容器有多种好处,从部署速度的提升到大规模一致性交付等。即使如此,容器也并非一切问题的解决之道,因为使用容器会带来一定的开销,比如维护一个容器编排层。所以,你需要在项目开始的时候分析成本/效益。
现在,让我们开启Kubernetes世界之旅吧!
Kubernetes硬件结构
节点
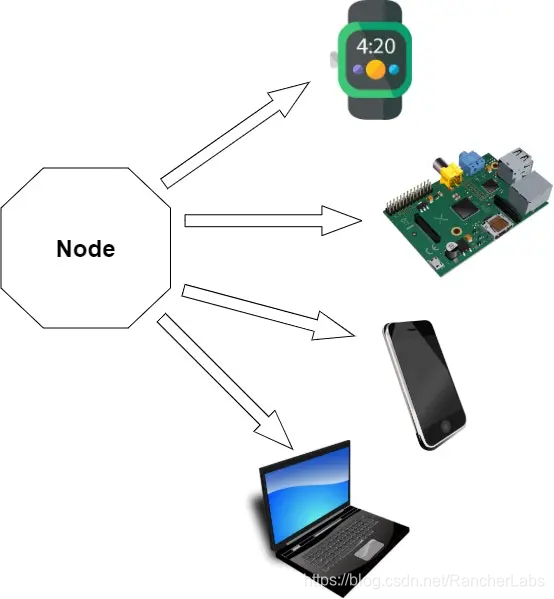
节点是Kubernetes中的worker机器,可以是任何具有CPU和RAM的设备。例如,智能手表、智能手机或者笔记本,甚至是树莓派都可以成为一个节点。当我们使用云时,节点就是一个虚拟机(VM)。所以,简单来说,节点是单一设备的抽象概念。这种抽象的好处是,我们不需要知道底层的硬件结构。我们只使用节点,这样一来,我们的基础设施就独立于平台。
集群
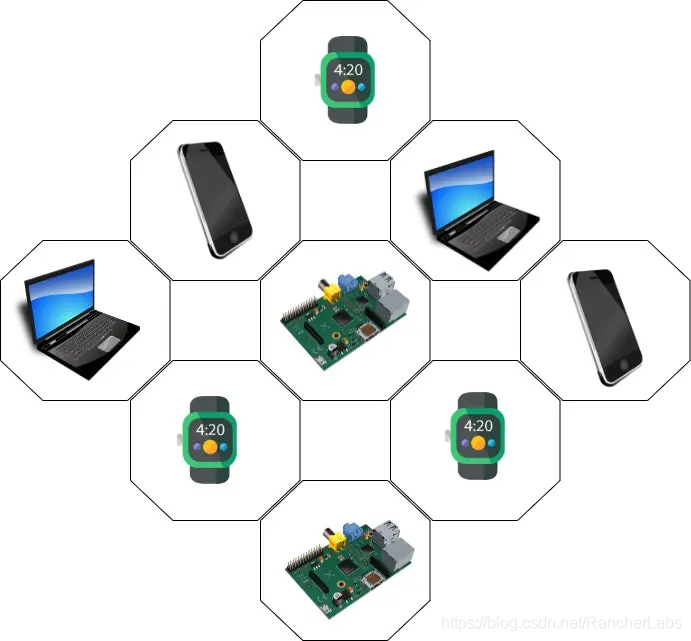
一个集群是一组节点。当你将程序部署到集群上时,它会自动将工作分配到各个节点。如果需要更多的资源(简单来讲,我们需要更多钱),那么集群中将会加入新的节点并且将会自动重新分配工作。
我们在集群上运行我们的代码,但我们不需要关心具体在哪个节点上运行了哪部分的代码。工作的分配是自动的。
持久卷(persistent volumes)
因为我们的代码可以从一个节点转移到另一个节点(例如,某个节点没有足够的内存,那么工作将会被重新调度到另一个拥有充足内存的节点上),所以在节点上保存数据容易丢失。如果我们想要永久保存我们的数据,我们应该使用持久卷。持久卷有点类似外部的硬盘,你可以将它插入并在上面保存你的数据。
Google开发的Kubernetes是一个无状态应用程序的平台,其持久性数据存储在其他地方。当这一项目发展成熟之后,许多企业想要在有状态应用程序中使用它,所以开发人员需要添加持久卷管理。如同早期的虚拟化技术,数据库server通常情况下并不是首要迁移到新架构上去的server。这是因为数据库是许多应用程序的核心,并且可能包含很多重要信息,所以本地数据库系统在虚拟机或物理机中通常规模很大。
所以,问题是,我们应该什么时候开始使用持久卷?要回答这个问题,首先,我们应该理解数据库应用的不同类型。
我们将数据管理解决方案分为以下两类:
- 垂直伸缩——包括传统的RDMS解决方案,例如MySQL、PostgreSQL以及SQL Server
- 水平伸缩——包括“NoSQL”解决方案,例如ElasticSearch或基于Hadoop的解决方案
垂直伸缩解决方案(如MySQL、PostgreSQL以及Microsoft SQL)不应该应用在容器内。这些数据库平台要求高I/O、共享磁盘以及block存储等,并且无法处理集群内的节点丢失,但这一情况常常会发生在基于容器的生态系统内。
对于水平伸缩应用程序(如Elastic、Cassanda、Kafka等)可以使用容器。他们能够承受数据库集群内的节点丢失以及数据库应用可以自行恢复均衡。
通常情况下,你应该容器化分布式数据库,从而利用冗余的存储技术并且能够处理数据库集群内的节点丢失(ElasticSearch是一个很好的例子)。
Kubernetes软件组件
容器
现代软件开发的目标之一是保证各类应用程序在相同的主机或集群上可以彼此隔离。虚拟机是解决该问题的一个方案。但虚拟机需要他们自己的操作系统,所以他们的规模通常是千兆字节。
容器则恰恰相反,它可以隔离应用程序的执行环境但共享底层操作系统。所以,容器就像一个盒子,我们可以在其中保存一切运行应用程序所需要的:代码、运行时、系统工具、系统仓库、设置等。它们通常仅需要几兆字节即可运行,远远少于虚拟机所需资源,并且可以立即启动。
Pods
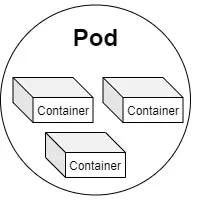
Pod是一组容器。在Kubernetes中,最小的单位是Pod。一个pod可以包含多个容器,但通常情况下我们在每个pod中仅使用一个容器,因为在Kubernetes中最小复制单位是pod。如果我们想要为每个容器单独扩容,我们添加一个容器到Pod中即可。
Deployments
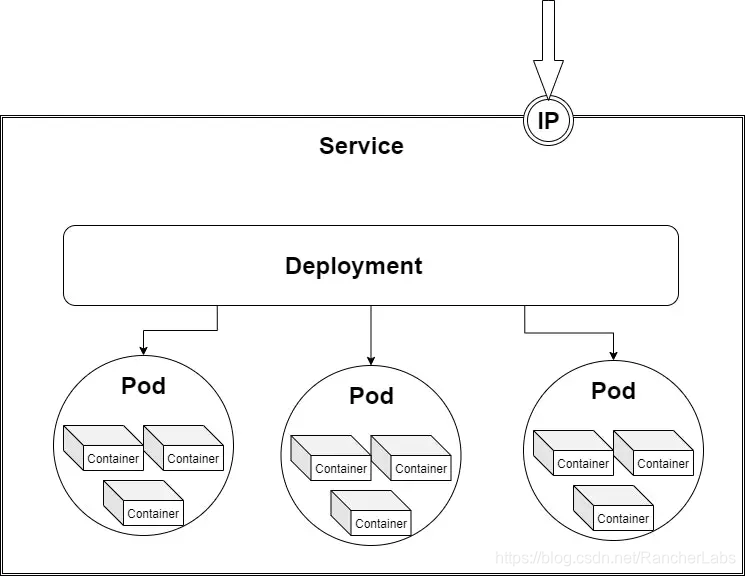
Deployment的最初功能是为pod和ReplicaSet(相同Pod在其中会被复制很多次)提供声明式更新。使用deployment,我们可以指定有多少相同pod的副本应该随时运行。Deployment类似于pod的管理器,它可以自动启动所需数量的pod、监控pod并在出现故障时重新创建Pod。Deployment极其有用,因为你不需要单独创建和管理每个pod。
我们通常为无状态应用程序使用deployment。然而,你可以通过给他附加一个持久卷来残存deployment的状态并使其变得有状态。
Stateful Sets
StatefulSet 是Kubernetes中的一个新概念并且它是用于管理有状态应用的资源。它管理deployment和一组pod的扩展,并且确保这些pod的顺序以及独特性。它与deployment类似,唯一的区别是deployment创建一组任意名称的pod,并且pod的顺序对它来说并不重要,而StatefulSet创建的pod都有独一无二的名称以及顺序。所以,如果你想为名为example的pod创建3个副本,那么StatefulSet将会创建为:example-0、example-1、example-2。因此,这一创建方式最重要的好处就是你可以通过pod的名称就了解大致的情况。
DaemonSets
DaemonSet可以确保pod运行在集群的所有节点上。如果从集群中添加/移除了一个节点,DaemonSet会自动添加/删除该pod。这对于监控以及日志十分重要,因为你可以监控每个节点并且不需要手动监控集群。
Services
Deployment负责保持一组Pod处于运行状态,那么Service负责为一组Pod启动网络访问。Services可以跨集群提供标准化的特性:负载均衡、应用间的服务发现以及零宕机应用程序deployment。每个服务都有独一无二的IP地址以及DNS主机名称。可以为需要使用服务的应用程序手动配置相应的IP地址或主机名称,然后流量将会被负载均衡到正确的pod。在外部流量的部分,我们会了解到更多的服务类型以及我们如何在内部服务和外部世界间进行通信。
ConfigMaps
如果你想部署到多个环境中,如staging、开发环境和生产环境,bake配置到应用程序中并不是一个好的操作,因为环境之间存在差异性。理想状况下,你会希望每个部署环境对应不同的配置。于是,ConfigMap应运而生。ConfigMaps可以让你从镜像中解耦配置工件以保持容器化应用程序的便携性。
外部流量
既然你已经了解运行在集群中的服务,那么你如何获取外部流量到你的集群中呢?有三种服务类型可以处理外部流量:ClusterIP、NodePort以及LoadBalancer。还有第4种解决方案:再添加一个抽象层,称为Ingress Controller。
ClusterIP
ClusterIP是Kubernetes中默认的服务类型,它可以让你在集群内部与其他服务进行通信。虽然ClusterIP不是为外部访问而设计的,但只要使用代理进行了一些改动,外部流量就可以访问我们的服务。不要在生产环境中采用这一解决方案,但可以用其来进行调试。声明为ClusterIP的服务不应该可以从外部直接可见。
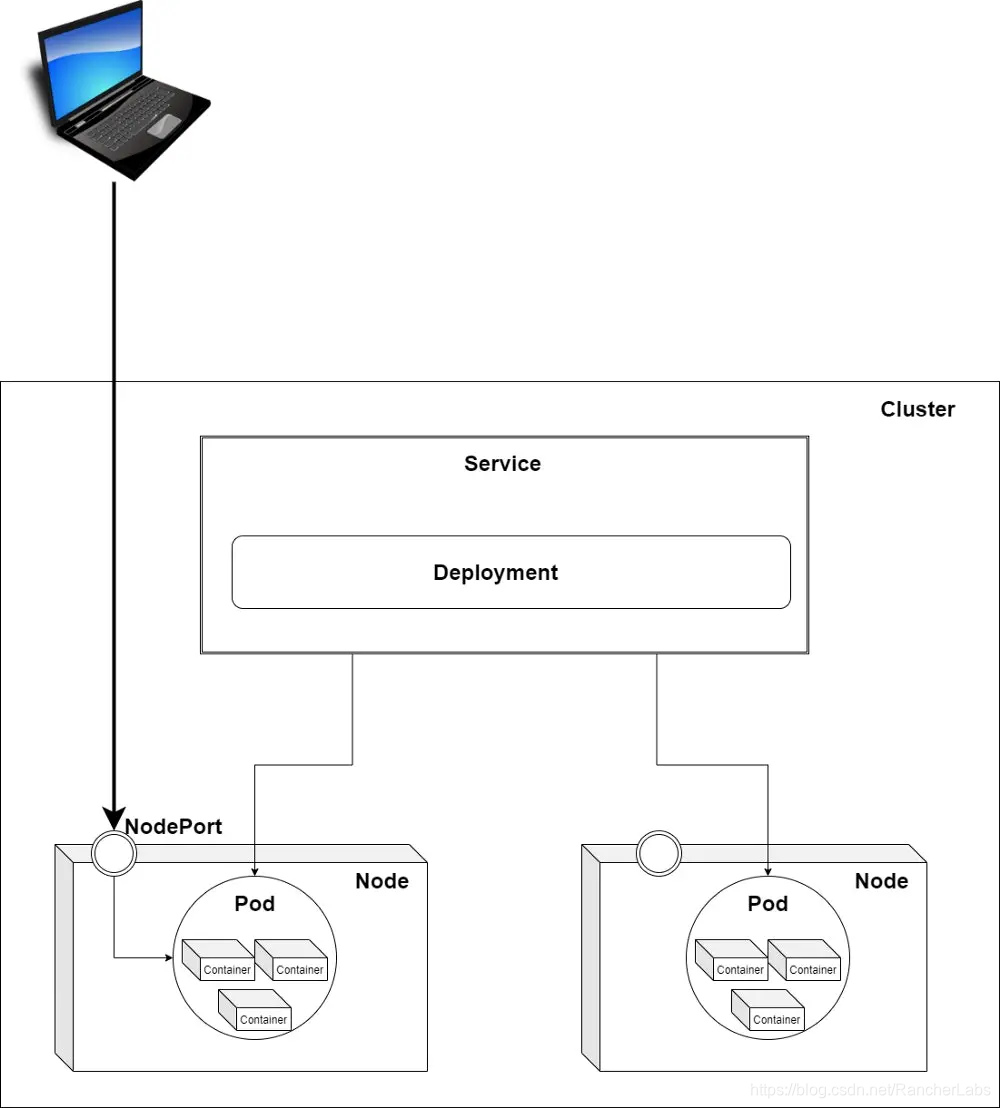
NodePort
正如我们在本文第一部分中所看到的那样,pod正在节点上运行。节点可以是各种不同的设备,如笔记本电脑或虚拟机(但在云端运行时)。每个节点有一个固定的IP地址。通过将一个服务声明为NodePort,服务将会暴露节点IP地址,以便你可以从外部访问它。你可以在生产环境中使用NodePort,但对于拥有许多服务的大型应用程序来说,手动管理所有不同的IP地址十分麻烦。
LoadBalancer
声明一个LoadBalancer类型的服务,就可以使用云提供商的LoadBalancer向外部公开。外部load balancer如何将流量路由到服务Pod取决于集群提供程序。有了这个解决方案,你不必管理集群中每个节点的所有IP地址,但你将为每个服务配备一个load balancer。缺点是,每个服务都有一个单独的load balancer,你将按照load balancer实例付费。
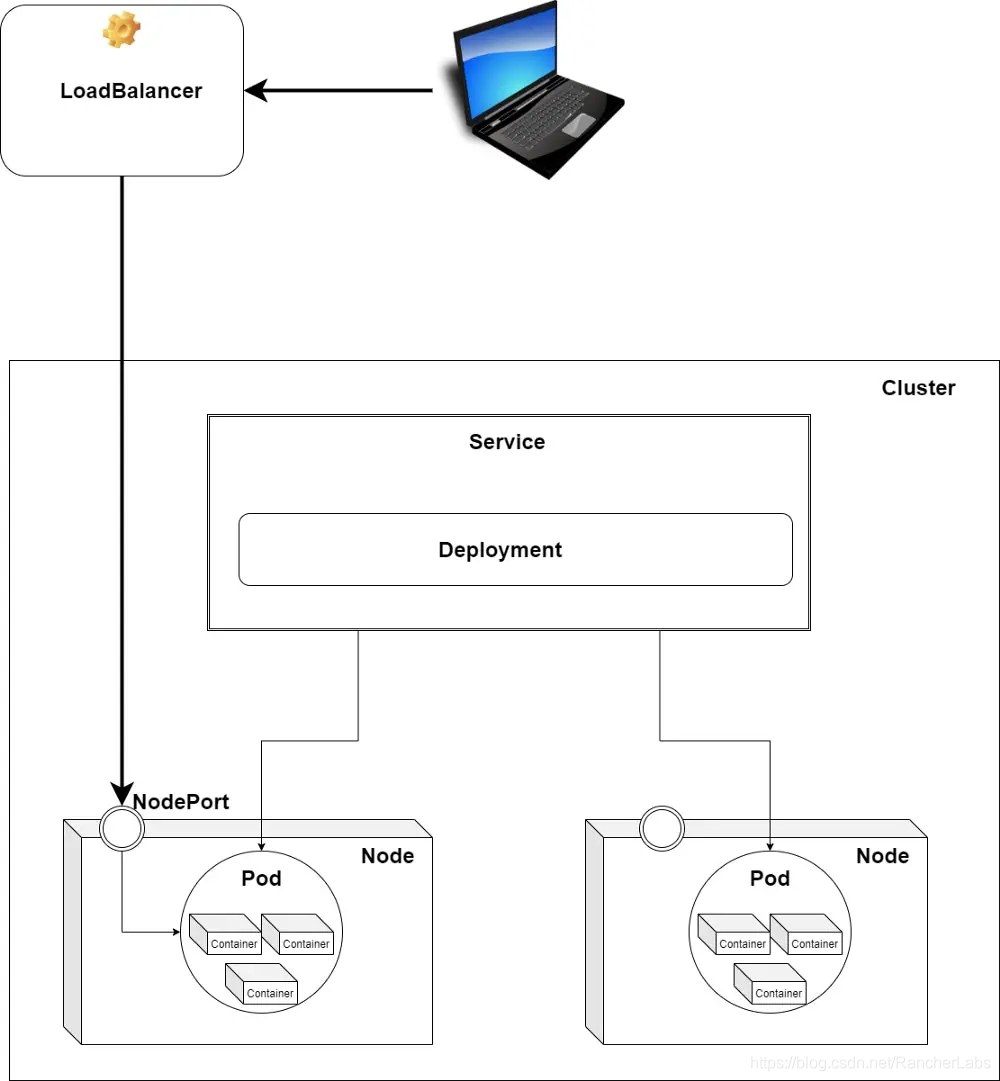
这一解决方案适用于生产环境,但它有些昂贵。接下来,我们来看看稍微便宜一些的解决方案。
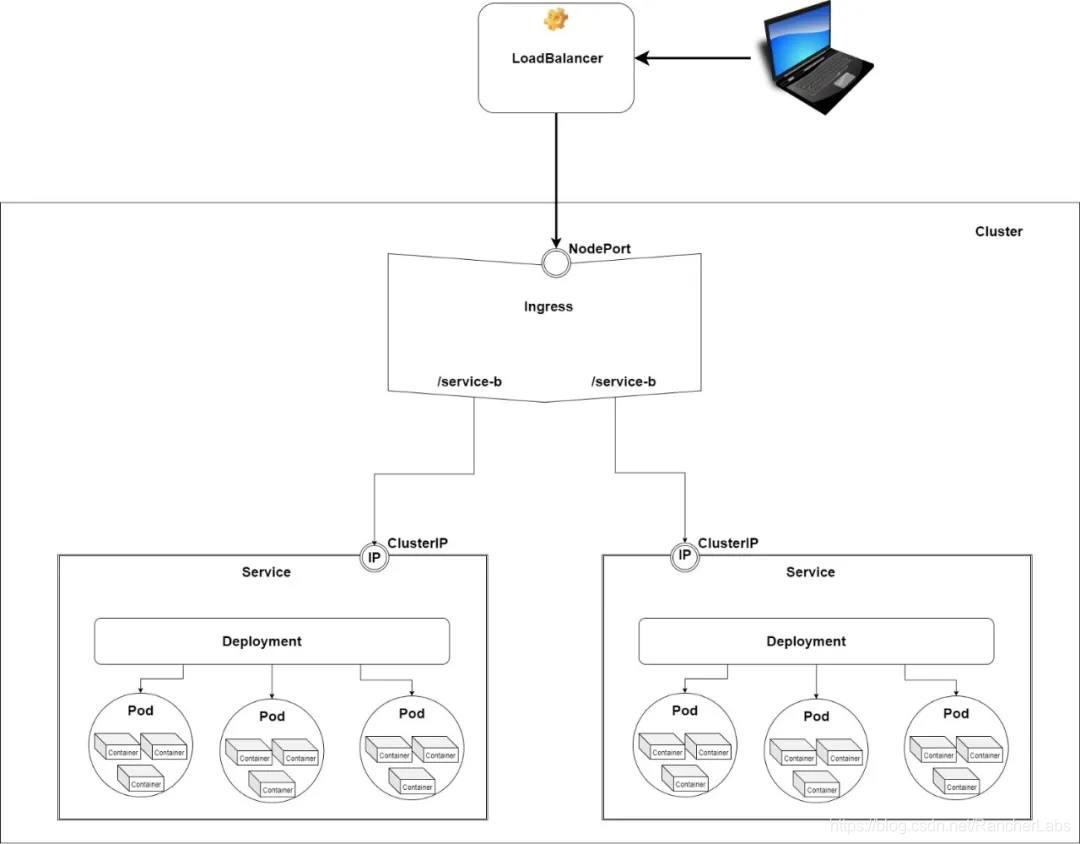
Ingress
Ingress不是一个服务,而是一个API对象,它可以管理外部对集群服务的访问。它作为反向代理和单一入口点(entry point)进入你的集群,将请求路由到不同的服务。我通常使用NGINX Ingress Controller,它承担了反向代理,同时也作为SSL发挥作用。暴露ingress的最佳生产方案是使用一个load balancer。
借助这一解决方案,你可以使用单个load balancer暴露任意数量的服务,所以你可以让费用保持在最低水平。
总结
在本文中,我们了解了Kubernetes中的基本概念及其硬件架构。我们还讨论了不同的软件组件,如Pod、Deployment、StatefulSets以及Services,并且了解了服务与外部世界之间如何进行通信。希望可以帮助你再次梳理Kubernetes里错综复杂的组件架构。