本文是跟安信证券容器云技术团队共同进行问题排查的最佳实践。
问题背景
我们发现客户的Kubernetes集群环境中所有的worker节点的Kubelet进程的CPU使用率长时间占用过高,通过pidstat可以看到CPU使用率高达100%。本文记录下了本次问题排查的过程。

集群环境

排查过程
使用strace工具对kubelet进程进行跟踪
1、由于Kubelet进程CPU使用率异常,可以使用strace工具对kubelet进程动态跟踪进程的调用情况,首先使用strace -cp

从上图可以看到,执行系统调用过程中,futex抛出了五千多个errors,这并不是一个正常的数量,而且该函数占用的时间达到了99%,所以需要进一步查看kubelet进程相关的调用。
2、由于strace -cp命令只能查看进程的整体调用情况,所以我们可以通过strace -tt -p

从strace输出的结果来看,在执行futex相关的系统调用时,有大量的Connect timed out,并返回了-1和ETIMEDOUT的error,所以才会在strace -cp中看到了那么多的error。
futex是一种用户态和内核态混合的同步机制,当futex变量告诉进程有竞争发生时,会执行系统调用去完成相应的处理,例如wait或者wake up,从官方的文档了解到,futex有这么几个参数:
futex(uint32_t *uaddr, int futex_op, uint32_t val,
const struct timespec *timeout, /* or: uint32_t val2 */
uint32_t *uaddr2, uint32_t val3);
官方文档给出ETIMEDOUT的解释:
ETIMEDOUT
The operation in futex_op employed the timeout specified in
timeout, and the timeout expired before the operation
completed.
意思就是在指定的timeout时间中,未能完成相应的操作,其中futex_op对应上述输出结果的FUTEX_WAIT_PRIVATE和FUTEX_WAIT_PRIVATE,可以看到基本都是发生在FUTEX_WAIT_PRIVATE时发生的超时。
从目前的系统调用层面可以判断,futex无法顺利进入睡眠状态,但是futex进行了哪些操作还是不清楚,因此仍无法判断kubeletCPU飙高的原因,所以我们需要进一步从kubelet的函数调用中去看到底是执行卡在了哪个地方。
FUTEX_PRIVATE_FLAG:这个参数告诉内核futex是进程专用的,不与其他进程共享,这里的FUTEX_WAIT_PRIVATE和FUTEX_WAKE_PRIVATE就是其中的两种FLAG;
futex相关说明1: https://man7.org/linux/man-pages/man7/futex.7.html
fuex相关说明2: https://man7.org/linux/man-pages/man2/futex.2.html
使用go pprof工具对kubelet函数调用进行分析
早期的Kubernetes版本,可以直接通过debug/pprof 接口获取debug数据,后面考虑到相关安全性的问题,取消了这个接口,具体信息可以参考CVE-2019-11248(https://github.com/kubernetes/kubernetes/issues/81023)。因此我们将通过kubectl开启proxy进行相关数据指标的获取:
1、首先使用kubectl proxy命令启动API server代理
kubectl proxy --address='0.0.0.0' --accept-hosts='^*$'
这里需要注意,如果使用的是Rancher UI上复制的kubeconfig文件,则需要使用指定了master IP的context,如果是RKE或者其他工具安装则可以忽略。
2、构建Golang环境。go pprof需要在golang环境下使用,本地如果没有安装golang,则可以通过Docker快速构建Golang环境
docker run -itd --name golang-env --net host golang bash
3、使用go pprof工具导出采集的指标,这里替换127.0.0.1为apiserver节点的IP,默认端口是8001,如果docker run的环境跑在apiserver所在的节点上,可以使用127.0.0.1。另外,还要替换NODENAME为对应的节点名称。
docker exec -it golang-env bash
go tool pprof -seconds=60 -raw -output=kubelet.pprof http://127.0.0.1:8001/api/v1/nodes/${NODENAME}/proxy/debug/pprof/profile
4、输出好的pprof文件不方便查看,需要转换成火焰图,推荐使用FlameGraph工具生成svg图
git clone https://github.com/brendangregg/FlameGraph.git
cd FlameGraph/
./stackcollapse-go.pl kubelet.pprof > kubelet.out
./flamegraph.pl kubelet.out > kubelet.svg
转换成火焰图后,就可以在浏览器直观地看到函数相关调用和具体调用时间比了。
5、分析火焰图
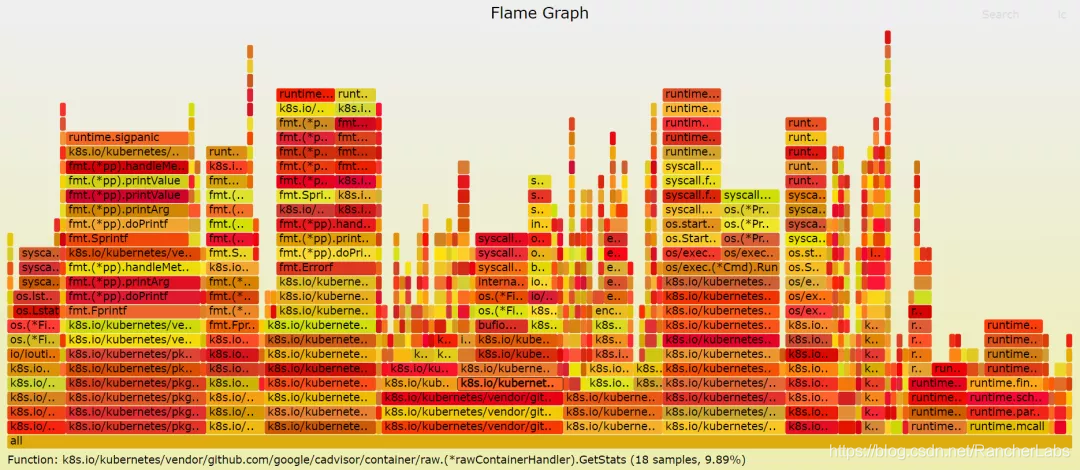
从kubelet的火焰图可以看到,调用时间最长的函数是k8s.io/kubernetes/vendor/github.com/google/cadvisor/manager.(*containerData).housekeeping,其中cAdvisor是kubelet内置的指标采集工具,主要是负责对节点机器上的资源及容器进行实时监控和性能数据采集,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况。
深入函数调用可以发现k8s.io/kubernetes/vendor/github.com/opencontainers/runc/libcontainer/cgroups/fs.(*Manager).GetStats这个函数占用k8s.io/kubernetes/vendor/github.com/google/cadvisor/manager.(*containerData).housekeeping这个函数的时间是最长的,说明在获取容器CGroup相关状态时占用了较多的时间。
6、既然这个函数占用时间长,那么我们就分析一下这个函数具体干了什么。
func (s *MemoryGroup) GetStats(path string, stats *cgroups.Stats) error {
// Set stats from memory.stat.
statsFile, err := os.Open(filepath.Join(path, "memory.stat"))
if err != nil {
if os.IsNotExist(err) {
return nil
}
return err
}
defer statsFile.Close()
sc := bufio.NewScanner(statsFile)
for sc.Scan() {
t, v, err := fscommon.GetCgroupParamKeyValue(sc.Text())
if err != nil {
return fmt.Errorf("failed to parse memory.stat (%q) - %v", sc.Text(), err)
}
stats.MemoryStats.Stats[t] = v
}
stats.MemoryStats.Cache = stats.MemoryStats.Stats["cache"]
memoryUsage, err := getMemoryData(path, "")
if err != nil {
return err
}
stats.MemoryStats.Usage = memoryUsage
swapUsage, err := getMemoryData(path, "memsw")
if err != nil {
return err
}
stats.MemoryStats.SwapUsage = swapUsage
kernelUsage, err := getMemoryData(path, "kmem")
if err != nil {
return err
}
stats.MemoryStats.KernelUsage = kernelUsage
kernelTCPUsage, err := getMemoryData(path, "kmem.tcp")
if err != nil {
return err
}
stats.MemoryStats.KernelTCPUsage = kernelTCPUsage
useHierarchy := strings.Join([]string{"memory", "use_hierarchy"}, ".")
value, err := fscommon.GetCgroupParamUint(path, useHierarchy)
if err != nil {
return err
}
if value == 1 {
stats.MemoryStats.UseHierarchy = true
}
pagesByNUMA, err := getPageUsageByNUMA(path)
if err != nil {
return err
}
stats.MemoryStats.PageUsageByNUMA = pagesByNUMA
return nil
}
从代码中可以看到,进程会去读取memory.stat这个文件,这个文件存放了cgroup内存使用情况。也就是说,在读取这个文件花费了大量的时间。这时候,如果我们手动去查看这个文件,会是什么效果?
# time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
real 0m9.065s
user 0m0.000s
sys 0m9.064s
从这里可以看出端倪了,读取这个文件花费了9s,显然是不正常的。
基于上述结果,我们在cAdvisor的GitHub上查找到一个issue(https://github.com/google/cadvisor/issues/1774),从该issue中可以得知,该问题跟slab memory 缓存有一定的关系。从该issue中得知,受影响的机器的内存会逐渐被使用,通过/proc/meminfo看到使用的内存是slab memory,该内存是内核缓存的内存页,并且其中绝大部分都是dentry缓存。从这里我们可以判断出,当CGroup中的进程生命周期结束后,由于缓存的原因,还存留在slab memory中,导致其类似僵尸CGroup一样无法被释放。
也就是每当创建一个memory CGroup,在内核内存空间中,就会为其创建分配一份内存空间,该内存包含当前CGroup相关的cache(dentry、inode),也就是目录和文件索引的缓存,该缓存本质上是为了提高读取的效率。但是当CGroup中的所有进程都退出时,存在内核内存空间的缓存并没有清理掉。
内核通过伙伴算法进行内存分配,每当有进程申请内存空间时,会为其分配至少一个内存页面,也就是最少会分配4k内存,每次释放内存,也是按照最少一个页面来进行释放。当请求分配的内存大小为几十个字节或几百个字节时,4k对其来说是一个巨大的内存空间,在Linux中,为了解决这个问题,引入了slab内存分配管理机制,用来处理这种小量的内存请求,这就会导致,当CGroup中的所有进程都退出时,不会轻易回收这部分的内存,而这部分内存中的缓存数据,还会被读取到stats中,从而导致影响读取的性能。
解决方法
1、清理节点缓存,这是一个临时的解决方法,暂时清空节点内存缓存,能够缓解kubelet CPU使用率,但是后面缓存上来了,CPU使用率又会升上来。
echo 2 > /proc/sys/vm/drop_caches
2、升级内核版本
其实这个主要还是内核的问题,在GitHub上这个commit(https://github.com/torvalds/linux/commit/205b20cc5a99cdf197c32f4dbee2b09c699477f0)中有提到,在5.2+以上的内核版本中,优化了CGroup stats相关的查询性能,如果想要更好的解决该问题,建议可以参考自己操作系统和环境,合理的升级内核版本。
另外Redhat在kernel-4.18.0-176(https://bugzilla.redhat.com/show_bug.cgi?id=1795049)版本中也优化了相关CGroup的性能问题,而CentOS 8/RHEL 8默认使用的内核版本就是4.18,如果目前您使用的操作系统是RHEL7/CentOS7,则可以尝试逐渐替换新的操作系统,使用这个4.18.0-176版本以上的内核,毕竟新版本内核总归是对容器相关的体验会好很多。
kernel相关commit:
https://github.com/torvalds/linux/commit/205b20cc5a99cdf197c32f4dbee2b09c699477f0
redhat kernel bug fix:
https://bugzilla.redhat.com/show_bug.cgi?id=1795049