目标检测(NN)
白嫖Colab的GPU,以resnet50作为backbone来完成目标检测任务。(可通过迁移学习,训练速度快,但精度不高)
1. 利用Colab搭建训练环境
1.1 加载google硬盘
from google.colab import drive
drive.mount('/content/drive')
1.2 修改工作目录
import os
os.chdir("/content/drive/MyDrive")
修改后工作目录会转到MyDrive目录下

新建一个data目录,作为存储数据的文件夹。!mkdir data
1.3 下载数据文件到工作目录下(支持git, wget)
!cd data && wget http://xinggangw.info/data/tiny_vid.zip
1.4 解压到data文件夹
!unzip data/tiny_vid -d ./data
1.5 删除安装包
!rm -rf data/tiny_vid.zip
至此数据加载到环境基本完成。
2. 导入所需库
import torch
import torch.nn as nn
import torch.utils.data as data
import torchvision
import torchvision.transforms as transforms
from tqdm import tqdm
import numpy as np
from PIL import Image
import os
3. 自定义dataset
class TvidDataset(data.Dataset):
CLASSES = ['bird', 'car', 'dog', 'lizard', 'turtle']
def __init__(self, root, mode):
assert mode in ['train', 'test']
if not os.path.isabs(root):
root = os.path.expanduser(root) if root[0] == '~' else os.path.abspath(root)
self.images = []
self.transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
]) # 图片处理工具
for c, cls in enumerate(self.CLASSES):
dir = os.path.join(root, cls) # 图片所在文件目录
ann = os.path.join(root, cls + '_gt.txt') # 加载标注文件
with open(ann) as f:
for i, line in enumerate(f):
if (mode == 'train' and i >= 150) or i >= 180:
break # 180之后的图片存在瑕疵不适合训练
if mode == 'test' and i < 150: # 后30个作为验证集
continue
idx, *xyxy = line.strip().split(' ') # 解析每一行数据
self.images.append({
'path': os.path.join(dir, '%06d.JPEG' % int(idx)),
'cls': c,
'bbox': [int(c) for c in xyxy]}) # 通过mode不同返回不同的数据集
def __len__(self): # 自定义数据集需要重写下面两个函数
return len(self.images)
def __getitem__(self, idx):
img_info = self.images[idx]
img = Image.open(img_info['path'])
img, bbox = self.transforms(img), torch.tensor(img_info['bbox'])/128 #bbox归一化
return img, {'cls': img_info['cls'], 'bbox': bbox}
4. 构建Detector模型
class BoxHead(nn.Module):
def __init__(self, lengths, num_classes):
super(BoxHead, self).__init__()
self.cls_score = nn.Sequential(*tuple([
module for i in range(len(lengths) - 1)
for module in (nn.Linear(lengths[i], lengths[i + 1]), nn.ReLU())]
+ [nn.Linear(lengths[-1], num_classes)]))
self.bbox_pred = nn.Sequential(*tuple([
module for i in range(len(lengths) - 1)
for module in (nn.Linear(lengths[i], lengths[i + 1]), nn.ReLU())]
+ [nn.Linear(lengths[-1], 4)]))
def forward(self, x):
logits = self.cls_score(x)
bbox = self.bbox_pred(x)
return logits, bbox
class Detector(nn.Module):
def __init__(self, lengths, num_classes):
super(Detector, self).__init__()
resnet = torchvision.models.resnet50(pretrained=True)
# for param in resnet.parameters():
# param.requires_grad = False # 这一步能固定resnet的参数,用来迁移学习,训练速度也会更快
# 输入in_channel=3, out_features=1000,去掉后面两层后输出为2048*4*4长度的数据
resnet.avgpool = nn.Identity()
resnet.fc = nn.Identity() # 去除最后两层,这里把最后两层用单位层替代,起到同样的效果
self.backbone = resnet
self.box_head = BoxHead(lengths, num_classes)
def forward(self, x):
x = self.backbone(x) # B, 2048*4*4
# x = x.flatten(1)
logits, bbox = self.box_head(x)
return logits, bbox
5. iou计算
def compute_iou(bbox1, bbox2):
if isinstance(bbox1, torch.Tensor):
bbox1 = bbox1.detach().numpy()
if isinstance(bbox2, torch.Tensor):
bbox2 = bbox2.detach().numpy()
area1 = (bbox1[:, 2] - bbox1[:, 0]) * (bbox1[:, 3] - bbox1[:, 1])
area2 = (bbox2[:, 2] - bbox2[:, 0]) * (bbox2[:, 3] - bbox2[:, 1])
ix1 = np.maximum(bbox1[:, 0], bbox2[:, 0])
ix2 = np.minimum(bbox1[:, 2], bbox2[:, 2])
iy1 = np.maximum(bbox1[:, 1], bbox2[:, 1])
iy2 = np.minimum(bbox1[:, 3], bbox2[:, 3])
inter = np.maximum(ix2 - ix1, 0) * np.maximum(iy2 - iy1, 0)
union = area1 + area2 - inter
return inter / union
6. 编写训练和测试标准代码
# 训练代码,输入模型,trainloader, criterion, optimizer, scheduler, epoch, device
def train_epoch(model, dataloader, criterion: dict, optimizer,
scheduler, epoch, device):
model.train()
bar = tqdm(dataloader)
bar.set_description(f'epoch {epoch:2}')
correct, total = 0, 0
for X, y in bar:
X, gt_cls, gt_bbox = X.to(device), y['cls'].to(device), y['bbox'].to(device) # 数据转化
logits, bbox = model(X)
loss = criterion['cls'](logits, gt_cls) + 10 * criterion['box'](bbox, gt_bbox)
optimizer.zero_grad()
loss.backward()
optimizer.step() # 更新weight
correct += sum((torch.argmax(logits, axis=1) == gt_cls).cpu().detach().numpy() &
(compute_iou(bbox.cpu(), gt_bbox.cpu()) > iou_thr))
total += len(X)
bar.set_postfix_str(f'lr={scheduler.get_last_lr()[0]:.4f}'
f' acc={correct / total * 100:.2f}'
f' loss={loss.item():.2f}')
scheduler.step() # 更新lr
# 测试代码,输入模型,testloader, device,输出结果
def test_epoch(model, dataloader, device):
model.eval()
with torch.no_grad():
correct, correct_cls, total = 0, 0, 0
for X, y in dataloader:
X, gt_cls, gt_bbox = X.to(device), y['cls'].to(device), y['bbox'].to(device)
logits, bbox = model(X)
correct += sum((torch.argmax(logits, axis=1) == gt_cls).cpu().detach().numpy() &
(compute_iou(bbox.cpu(), gt_bbox.cpu()) > iou_thr))
correct_cls += sum((torch.argmax(logits, axis=1) == gt_cls))
total += len(X)
print(f' val acc: {correct / total * 100:.2f}')
7. 编写主训练程序
lr = 5e-3
batch = 32
epochs = 100
device = "cuda" if torch.cuda.is_available() else "cpu"
# device = "cpu" # cpu训练比gpu训练慢很多,不要轻易尝试
iou_thr = 0.5
seed=310
torch.manual_seed(seed) # 用来指定随机种子,以免不能复现结果
trainloader = data.DataLoader(TvidDataset(root='./data/tiny_vid', mode='train'),
batch_size=batch, shuffle=True, num_workers=0)
testloader = data.DataLoader(TvidDataset(root='./data/tiny_vid', mode='test'),
batch_size=batch, shuffle=True, num_workers=0)
model = Detector(lengths=(2048*4*4,2048,512),
num_classes=5).to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=0.9,
weight_decay=1e-4)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.95,
last_epoch=-1)
# 用来调整lr,lr随着epoch增加而逐渐减小
criterion = {'cls': nn.CrossEntropyLoss(), 'box': nn.L1Loss()}
for epoch in range(epochs):
train_epoch(model, trainloader, criterion, optimizer,
scheduler, epoch, device) # 传入训练所需要的模型,数据加载器,评价函数,优化器,训练组数,设备型号
test_epoch(model, testloader, device) # 传入测试所需要的模型,数据加载器,设备型号
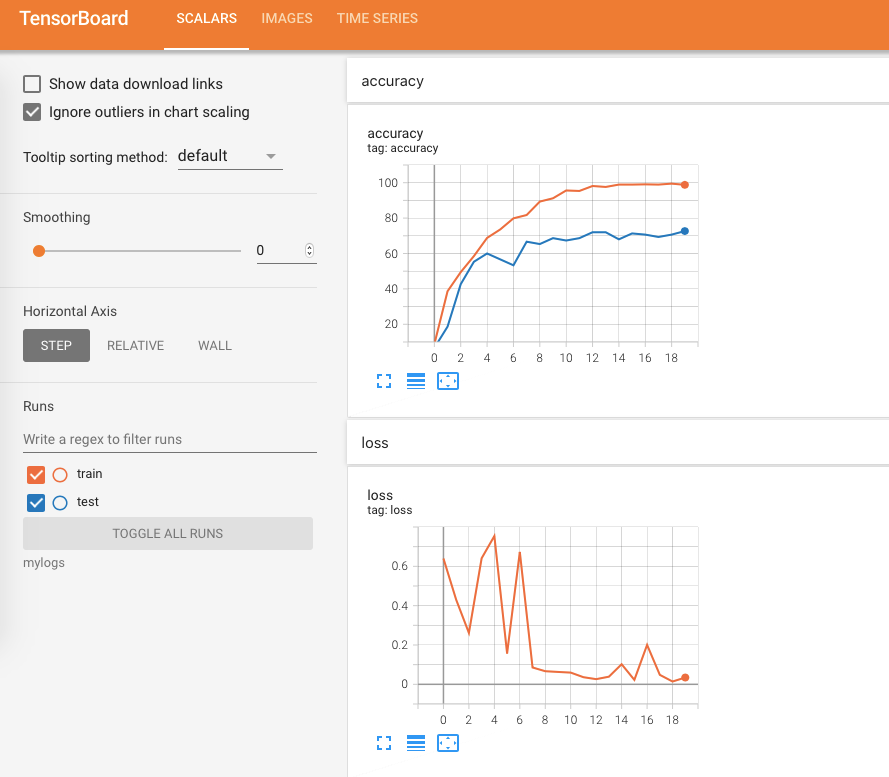
训练结果如下(部分):

8. 利用tensorboard直观的显示训练结果
这里只需要更改train_epoch和test_epoch以及主训练程序:
- train_epoch 和 test_epoch:
def train_epoch(model, dataloader, criterion: dict, optimizer,
scheduler, epoch, device, writer): # 需要输入trainwriter
model.train()
bar = tqdm(dataloader)
bar.set_description(f'epoch {epoch:2}')
correct, total = 0, 0
for X, y in bar:
X, gt_cls, gt_bbox = X.to(device), y['cls'].to(device), y['bbox'].to(device)
logits, bbox = model(X)
loss = criterion['cls'](logits, gt_cls) + 10 * criterion['box'](bbox, gt_bbox)
optimizer.zero_grad()
loss.backward()
optimizer.step()
correct += sum((torch.argmax(logits, axis=1) == gt_cls).cpu().detach().numpy() &
(compute_iou(bbox.cpu(), gt_bbox.cpu()) > iou_thr))
total += len(X)
bar.set_postfix_str(f'lr={scheduler.get_last_lr()[0]:.4f}'
f' acc={correct / total * 100:.2f}'
f' loss={loss.item():.2f}')
scheduler.step()
writer.add_scalar("accuracy", correct/total*100, epoch)
writer.add_scalar("loss", loss.item(), epoch)
def test_epoch(model, dataloader, device, epoch, writer): # 需要输入testwriter以及epoch
model.eval()
with torch.no_grad():
correct, correct_cls, total = 0, 0, 0
for X, y in dataloader:
X, gt_cls, gt_bbox = X.to(device), y['cls'].to(device), y['bbox'].to(device)
logits, bbox = model(X)
correct += sum((torch.argmax(logits, axis=1) == gt_cls).cpu().detach().numpy() &
(compute_iou(bbox.cpu(), gt_bbox.cpu()) > iou_thr))
correct_cls += sum((torch.argmax(logits, axis=1) == gt_cls))
total += len(X)
acc = correct / total * 100
print(f' val acc: {acc:.2f}')
writer.add_scalar("accuracy", acc, epoch)
- 训练主程序:
lr = 5e-3
batch = 32
epochs = 20
device = "cuda" if torch.cuda.is_available() else "cpu"
# device = "cpu" # cpu训练比gpu训练慢很多,不要轻易尝试
iou_thr = 0.5
seed=310
torch.manual_seed(seed) # 用来指定随机种子,以免不能复现结果
from torch.utils.tensorboard import SummaryWriter
!rm -rf ./mylogs/* # 每次训练前清空历史日志
trainwriter = SummaryWriter("mylogs/train")
testwriter = SummaryWriter("mylogs/test")
trainloader = data.DataLoader(TvidDataset(root='./data/tiny_vid', mode='train'),
batch_size=batch, shuffle=True, num_workers=8)
testloader = data.DataLoader(TvidDataset(root='./data/tiny_vid', mode='test'),
batch_size=batch, shuffle=False, num_workers=8) # 如果线程报错,则改小一点这个数字,这个数字越大,图片加载得越快。
model = Detector(lengths=(2048*4*4,2048,512),
num_classes=5).to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=0.9,
weight_decay=1e-4)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.95,
last_epoch=-1)
# 用来调整lr,lr随着epoch增加而逐渐减小
criterion = {'cls': nn.CrossEntropyLoss(), 'box': nn.L1Loss()}
for epoch in range(epochs):
train_epoch(model, trainloader, criterion, optimizer,
scheduler, epoch, device, trainwriter) # 传入训练所需要的模型,数据加载器,评价函数,优化器,训练组数,设备型号
test_epoch(model, testloader, device, epoch, testwriter) # 传入测试所需要的模型,数据加载器,设备型号
trainwriter.close()
testwriter.close()
然后通过:
# 开启Colab的tensorboard
%load_ext tensorboard #使用tensorboard 扩展
%tensorboard --logdir=logs #定位tensorboard读取的文件目录
结果如下:
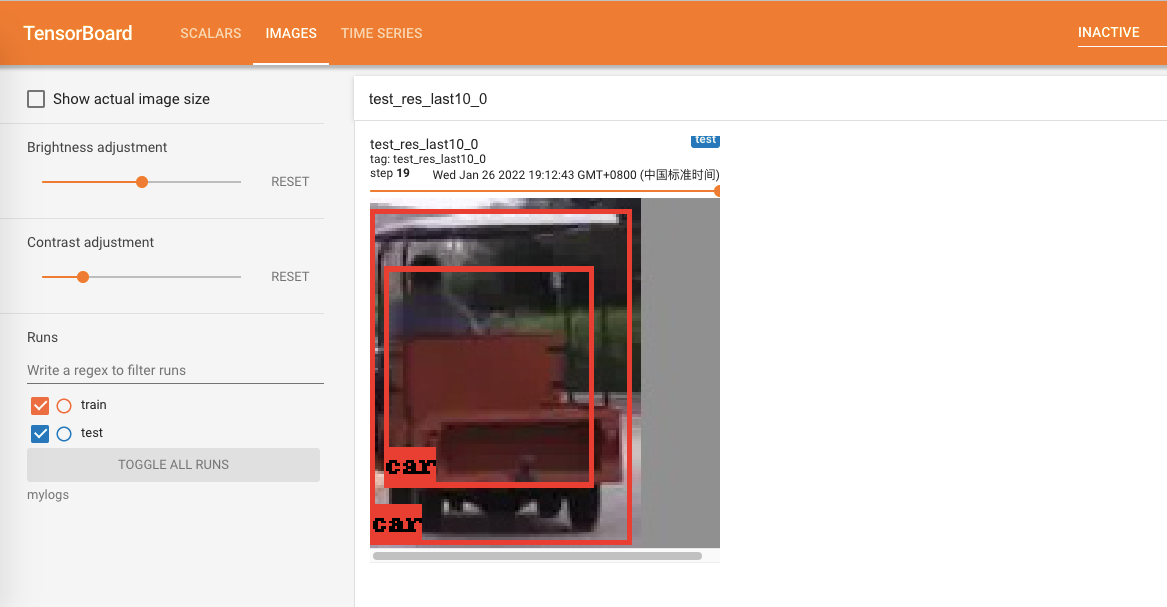
9. 利用tensorboard显示目标检测结果图片
这里主要选择测试集的最后10个图片来展示结果,利用writer.add_image_with_boxes()。
9.1 对自定义dataset做一点修改
class TvidDataset(data.Dataset):
CLASSES = ['bird', 'car', 'dog', 'lizard', 'turtle']
def __init__(self, root, mode):
assert mode in ['train', 'test']
self.mode = mode
if not os.path.isabs(root):
root = os.path.expanduser(root) if root[0] == '~' else os.path.abspath(root)
self.images = []
self.transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
]) # 图片处理工具
for c, cls in enumerate(self.CLASSES):
dir = os.path.join(root, cls) # 图片所在文件目录
ann = os.path.join(root, cls + '_gt.txt') # 加载标注文件
with open(ann) as f:
for i, line in enumerate(f):
if (mode == 'train' and i >= 150) or i >= 180:
break # 180之后的图片存在瑕疵不适合训练
if mode == 'test' and i < 150: # 后30个作为验证集
continue
idx, *xyxy = line.strip().split(' ') # 解析每一行数据
self.images.append({
'path': os.path.join(dir, '%06d.JPEG' % int(idx)),
'cls': c,
'bbox': [int(c) for c in xyxy]}) # 通过mode不同返回不同的数据集
if mode == 'test':
np.random.shuffle(self.images)
# 测试集 shuffle = False 但这里只在初始化时候做一次shuffle, 为了让tensorboard上能显示不同类别的图片
def __len__(self): # 自定义数据集需要重写下面两个函数
return len(self.images)
def __getitem__(self, idx):
img_info = self.images[idx]
img = Image.open(img_info['path'])
img, bbox = self.transforms(img), torch.tensor(img_info['bbox'])/128 #bbox归一化
if self.mode == 'test':
return img, {'cls': img_info['cls'], 'bbox': bbox, 'img_path':img_info['path']}
return img, {'cls': img_info['cls'], 'bbox': bbox}
# 如果是测试集,则会返回文件的路径,用来给图片显示,否则tensorboard上的图片是标准化后的图片
9.2 对测试过程代码做一点修改
def test_epoch(model, dataloader, device, epoch, writer): # 需要输入testwriter以及epoch
CLASSES = ['bird', 'car', 'dog', 'lizard', 'turtle']
model.eval()
with torch.no_grad():
correct, correct_cls, total = 0, 0, 0
idx = 0
for X, y in dataloader:
X, gt_cls, gt_bbox = X.to(device), y['cls'].to(device), y['bbox'].to(device)
logits, bbox = model(X)
predict = torch.argmax(logits, axis=1)
correct += sum((predict == gt_cls).cpu().detach().numpy() &
(compute_iou(bbox.cpu(), gt_bbox.cpu()) > iou_thr))
correct_cls += sum((torch.argmax(logits, axis=1) == gt_cls))
total += len(X)
idx += 1
if idx == len(dataloader)-1: # 如果是最后一个batch,则写入log文件
for i in range(len(X)):
img_ = transforms.ToTensor()(Image.open(y['img_path'][i]))
labels = [predict[i], gt_cls[i]]
labels = [CLASSES[l] for l in labels]
box1 = bbox[i].cpu().numpy()*128
box2 = gt_bbox[i].cpu().numpy()*128 # 之前归一化了,现在恢复成正常值
boxs = torch.tensor([box1, box2])
writer.add_image_with_boxes("test_res_last10_"+str(i),img_, boxs, epoch, labels = labels)
acc = correct / total * 100
print(f' val acc: {acc:.2f}')
writer.add_scalar("accuracy", acc, epoch)
9.3 对主训练程序做一点修改
lr = 5e-3
batch = 32
epochs = 20
device = "cuda" if torch.cuda.is_available() else "cpu"
# device = "cpu" # cpu训练比gpu训练慢很多,不要轻易尝试
iou_thr = 0.5
seed=310
torch.manual_seed(seed) # 用来指定随机种子,以免不能复现结果
from torch.utils.tensorboard import SummaryWriter
!rm -rf ./mylogs/* # 每次前训练清空日志
trainwriter = SummaryWriter("mylogs/train")
testwriter = SummaryWriter("mylogs/test")
trainloader = data.DataLoader(TvidDataset(root='./data/tiny_vid', mode='train'),
batch_size=batch, shuffle=True, num_workers=8)
testloader = data.DataLoader(TvidDataset(root='./data/tiny_vid', mode='test'),
batch_size=10, shuffle=False, num_workers=8)
# batch改成10,让最后一个batch(一共十个图片)用来展示结果。
model = Detector(lengths=(2048*4*4,2048,512),
num_classes=5).to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=0.9,
weight_decay=1e-4)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.95,
last_epoch=-1)
# 用来调整lr,lr随着epoch增加而逐渐减小
criterion = {'cls': nn.CrossEntropyLoss(), 'box': nn.MSELoss()}
for epoch in range(epochs):
train_epoch(model, trainloader, criterion, optimizer,
scheduler, epoch, device, trainwriter) # 传入训练所需要的模型,数据加载器,评价函数,优化器,训练组数,设备型号
test_epoch(model, testloader, device, epoch, testwriter) # 传入测试所需要的模型,数据加载器,设备型号
trainwriter.close()
testwriter.close()
结果如下:
综上,目标检测基础实验完成,主要利用resnet50+NN实现。