环境部署
环境部署需要安装python,这里已经配置好,略过
首先登陆kaggle 下载titanic数据
https://www.kaggle.com/c/titanic/data
点击Download ALL

查看数据
- gender

- test.csv

- train.csv
开始建模
import pandas as pd
import os
from sklearn.feature_extraction import DictVectorizer
#导入随机森林
from sklearn.ensemble import RandomForestClassifier
#导入xgboost并初始化
from xgboost import XGBClassifier
#使用网格搜寻的方法寻找更好的超参数
from sklearn.model_selection import GridSearchCV
os.chdir("/media/sdc/yueyao/Test/jupyter")
#读入数据
train = pd.read_csv("Datasets/train.csv")
test = pd.read_csv("Datasets/test.csv")
#选择预测有效的特征
selected_features = ['Pclass','Sex','Age','Embarked','SibSp','Parch','Fare']
X_train = train[selected_features]
X_test = test[selected_features]
y_train = train['Survived']
# Embarked 存在缺失,选择出现频率最高的进行填充
X_train['Embarked'].fillna('S',inplace=True)
X_test['Embarked'].fillna('S',inplace=True)
# 对于Age使用平均值或者中位数进行填充NA
X_train['Age'].fillna(X_train['Age'].mean(),inplace=True)
X_test['Age'].fillna(X_test['Age'].mean(),inplace=True)
X_test['Fare'].fillna(X_test['Fare'].mean(),inplace=True)
#对特征进行向量化
dict_vec = DictVectorizer(sparse = False)
X_train = dict_vec.fit_transform(X_train.to_dict(orient='record'))
X_test = dict_vec.fit_transform(X_test.to_dict(orient='record'))
#初始化
rfc = RandomForestClassifier()
xgbc = XGBClassifier()
#使用5折交叉验证的方法
from sklearn.model_selection import cross_val_score
cross_val_score(rfc,X_train,y_train,cv=5).mean()
cross_val_score(xgbc,X_train,y_train,cv=5).mean()
#使用RandomForestClassifier进行预测
rfc.fit(X_train,y_train)
#使用训练的模型进行预测
rfc_y_predict = rfc.predict(X_test)
#rfc预测的结果转化成数据框
rfc_submission = pd.DataFrame({'PassengerId':test['PassengerId'],'Survived':rfc_y_predict})
#保存数据
rfc_submission.to_csv("Datasets/rfc_submission.csv",index=False)
xgbc.fit(X_train,y_train)
#使用XGBC进行预测
xgbc_predict = xgbc.predict(X_test)
#生成数据框
xgbc_submission = pd.DataFrame({'PassengerId':test['PassengerId'],'Survived':xgbc_predict})
#保存数据
xgbc_submission.to_csv("Datasets/xgbc_submission.csv",index=False)
params={
'max_depth':range(2,7),
'n_estimators':range(100,1100,200),
'learning_rate':[0.05,0.1,0.25,0.5,1.0]
}
xgbc_best = XGBClassifier()
gs = GridSearchCV(xgbc_best,params,n_jobs=-1,cv=5,verbose=1)
gs.fit(X_train,y_train)
#检查优化后的超参数配置
gs.best_score_
gs.best_params_
xgbc_best_y_predict = gs.predict(X_test)
xgbc_best_submission = pd.DataFrame({
'PassengerId':test['PassengerId'],
'Survived':xgbc_best_y_predict
})
xgbc_best_submission.to_csv("Datasets/xgbc_best_submission.csv",index=False)结果的提交

- 使用api进行提交,首先需要下载一个json格式的钥匙,放在家目录.kaggle/
mv kaggle.json /home/yueyao/.kaggle/
#安装kaggle
python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple kaggle
#使用kaggle提交
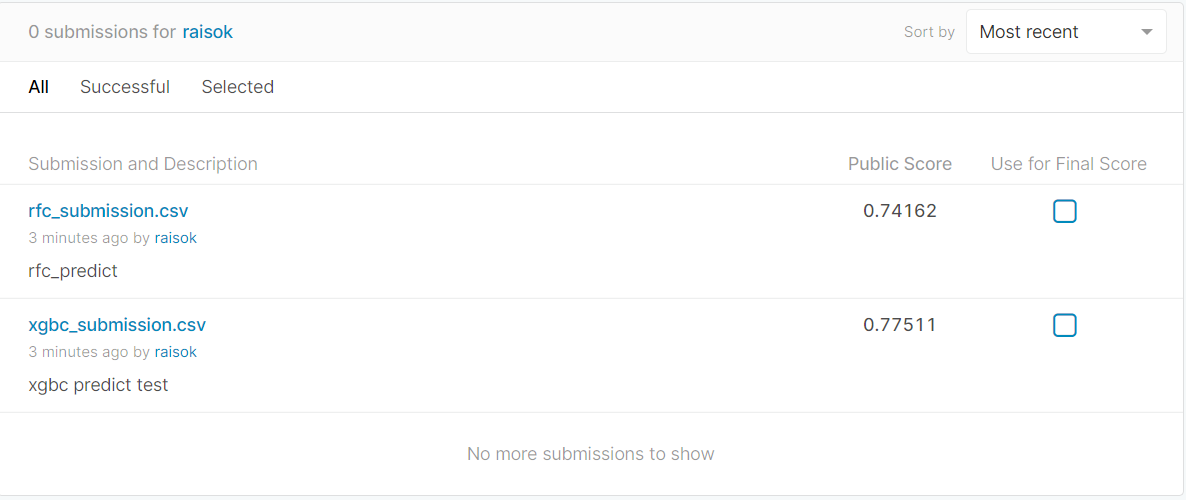
kaggle competitions submit -c titanic -f xgbc_submission.csv -m "xgbc_predict"我的提交里面会有得分