第11章:并发控制
代码是基于SQLServer学习,与MySQL有略微差别!
11.1、并发控制概述
多用户数据库系统
- 允许多个用户同时使用的数据库系统称为多用户数据库系统。
- 多用户数据库系统面临着执行多事务的情况。
事务并发执行带来的问题
- 并发执行的多个事务可能会同时存取同一数据,造成数据的不一致,破坏事务的隔离性和数据库的一致性。
- DBMS必须提供并发控制机制解决事务并发执行带来的问题。(并发控制器)
- 并发控制机制是衡量一个DBMS性能的重要标志之一。
并发操作带来的数据不一致性:
1、丢失修改(lost update)
2、不可重复读(non-repeatable read)
3、读“脏”数据(dirty read)
丢失修改
丢失修改是指事务T1与事务T2从数据库中读入同一数据并修改,事务T2的提交结果破坏了事务T1提交的结果,导致事务T1的修改被丢失。

CREATE TABLE sales
(
id char(2),
qty int
)
insert into sales values( 'A1', 10 )
-- 事务一
begin tran
declare @sl int
select @sl = qty from sales where id = 'A1'
waitfor delay '00:00:15.000'
update sales set qty = @sl - 1 where id = 'A1'
commit tran
-- 事务二
begin tran
declare @sl int
select @sl = qty from sales where id = 'A1'
waitfor delay '00:00:15.000'
update sales set qty = @sl - 1 where id = 'A1'
commit tran
不可重复度
1、事务T1读取某一数据后,事务T2对其做了修改,当事务T1再次读该数据时,得到与前一次不同的值。

begin tran
declare @sl int
declare @s2 int
select @sl = qty from sales where id = 'A1'
print(@sl)
waitfor delay '00:00:30.000'
select @s2 = qty from sales where id = 'A1'
print(@s2)
commit tran
begin tran
update sales set qty = qty *2 where id = 'A1'
commit tran
2、事务T1按一定条件读取某些数据记录后,事务T2删除了其中部分记录,当事务T1再次按相同条件读取数据时,发现某些记录神密地消失了。
3、事务T1按一定条件读取某些数据记录后,事务T2插入了一些记录,当事务T1再次按相同条件读取数据时,发现多了一些记录。
后两种不可重复读有时也称为幻影现象。
读“脏”数据
事务T1修改某一数据,并将其写回磁盘,事务T2读取同一数据后,事务T1由于某种原因被撤消,这时事务T1已修改过的数据恢复原值,事务T2读到的数据就与数据库中的数据不一致,是不正确的数据,又称为“脏”数据。

事务并发执行会导致数据不一致性
- 由于并发操作破坏了事务的隔离性
并发控制就是要用正确的方式调度并发操作,使一个事务的执行不受其他事务的干扰,从而避免造成数据的不一致性
并发控制的主要技术
- 封锁(Locking)
- 时间戳(Timestamp)
- 乐观控制法
商用的DBMS一般都采用封锁方法
11.2、封锁(Locking)
11.2.1、封锁概述
什么是封锁?
- 封锁就是事务T在对某个数据对象(例如表、记录等)操作之前,先向系统发出请求,对其加锁。
- 如果事务T的加锁请求得到满足,事务T就对该数据对象有了一定的控制。
- 如果事务T的加锁请求得不到满足,事务T就不能控制该数据对象。
- 封锁是实现并发控制的一个非常重要的技术
基本封锁类型
- 排它锁(Exclusive lock,简记为X锁)
- 共享锁(Share lock,简记为S锁)
排它锁(Exclusive lock,简记为X锁)
- 排它锁又称为写锁。
- 若事务T对数据对象A加上X锁,允许T读取和修改A,其它任何事务都不能再对A加任何类型的锁,直到T释放A上的锁。
共享锁(Share lock,简记为S锁)
- 共享锁又称为读锁。
- 若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其它事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。
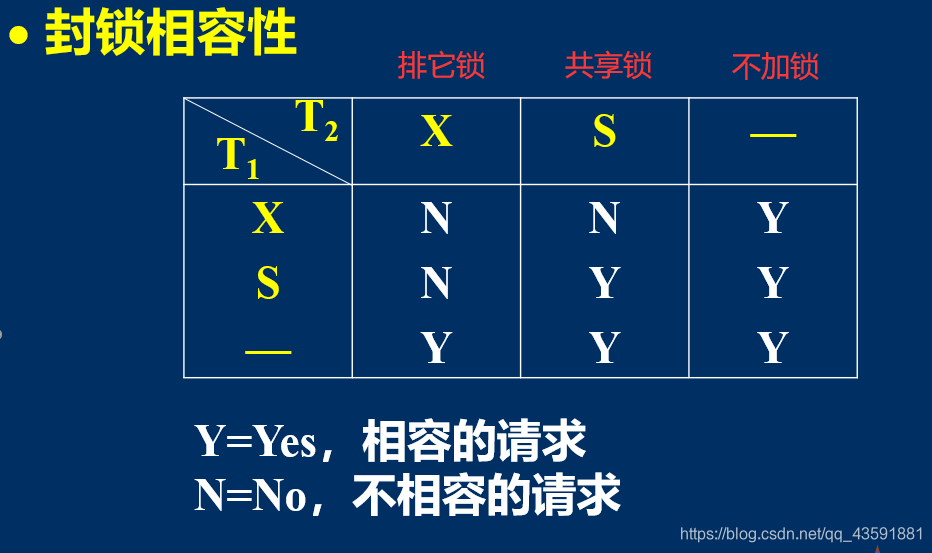
封锁协议(Locking Protocol)
- 在运用X锁和S锁对数据对象加锁时,需要约定一些规则(封锁协议):
- 何时申请X锁或S锁
- 何时释放X锁或S锁
- 常用的封锁协议:三级封锁协议。
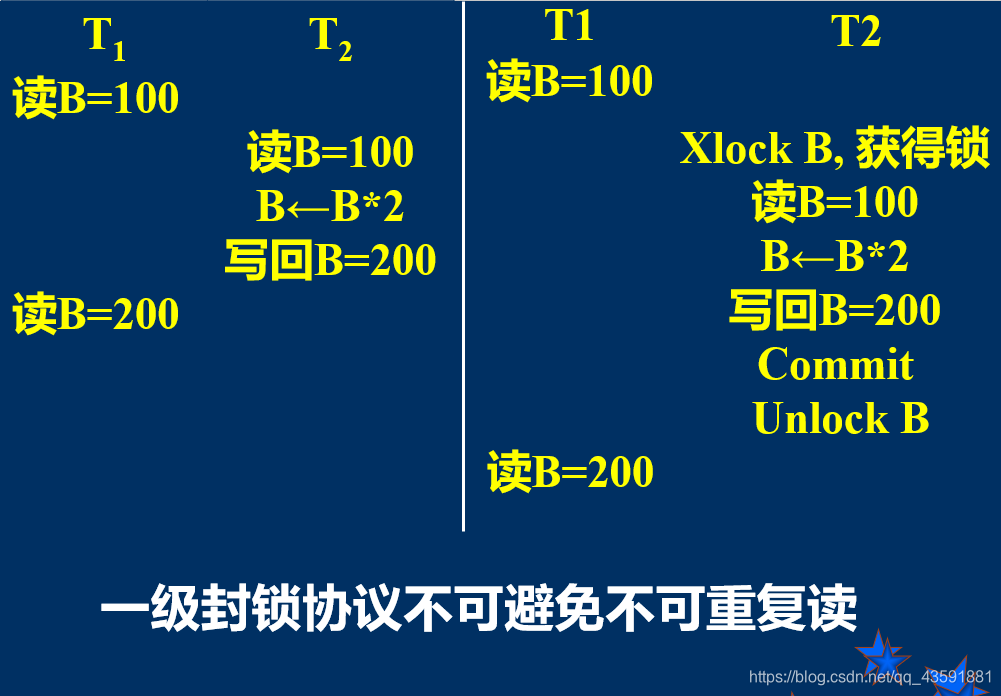
11.2.2、一级封锁协议
- 事务T在修改数据R之前必须先对其加X锁,直到事务结束才释放。
- 一级封锁协议可防止丢失修改
- 在一级封锁协议中,如果是读数据,是不需要加锁的,所以它不能避免不可重复读和读“脏”数据。


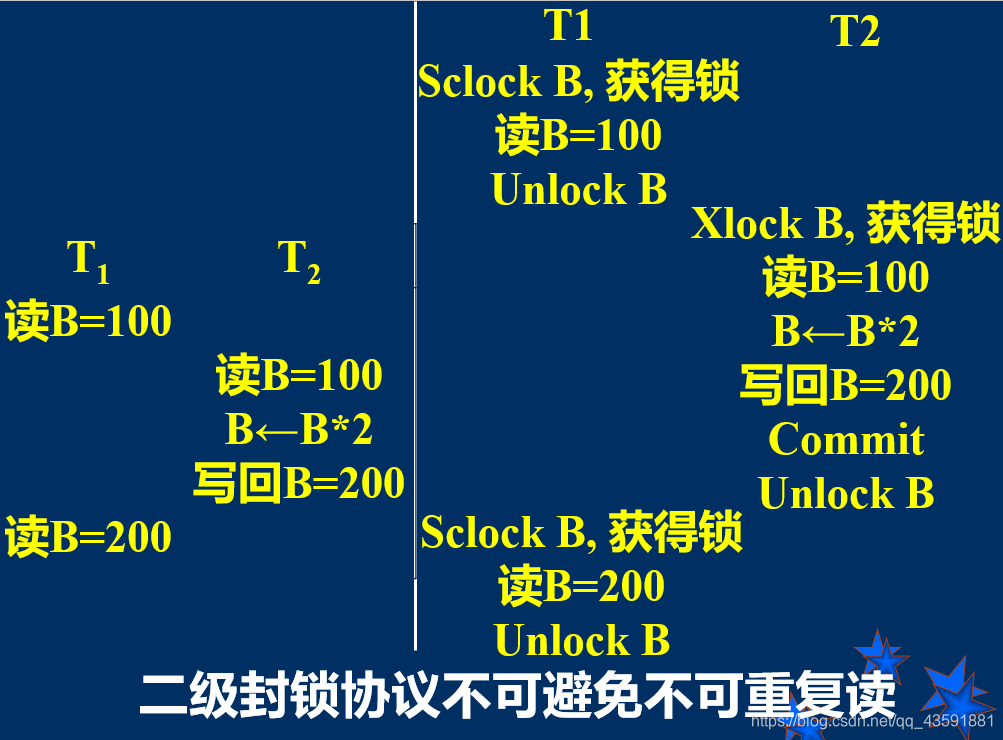
11.2.3、二级封锁协议
- 一级封锁协议+事务T在读取数据R前必须先加S锁,读完后不等事务结束即可释放S锁。
- 二级封锁协议可以防止丢失修改和读“脏”数据。
- 在二级封锁协议中,由于读完数据后即可释放S锁,所以它不能避免不可重复读。

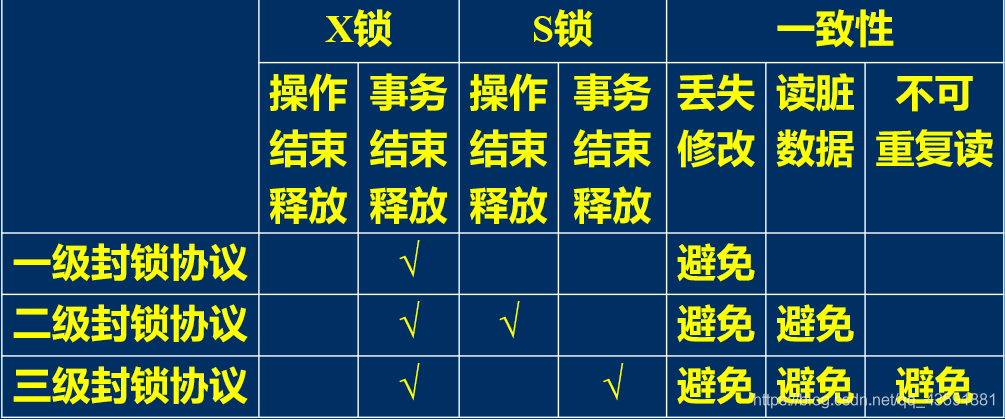
11.2.4、三级封锁协议
- 一级封锁协议 + 事务T在读取数据R之前必须先对其加S锁,直到事务结束才释放
- 三级封锁协议可避免丢失修改、读“脏”数据和不可重复读。

11.2.5、SQL Server的并发机制
测试加排它锁(X锁)能否避免丢失修改:
CREATE TABLE sales
(
id char(2),
qty int
)
insert into sales values( 'A1', 10 )
-- 【事务一】
begin tran
declare @sl int
select @sl = qty from sales with(Xlock)
where id = 'A1'
waitfor delay '00:00:10.000'
update sales set qty = @sl - 1 where id = 'A1'
commit tran
-- 【事务二】
begin tran
declare @sl int
select @sl=qty from sales with(Xlock)
where id='A1'
waitfor delay '00:00:10.000'
update sales set qty = @sl - 1 where id = 'A1'
commit tran
- 事务隔离
- 对于编程人员来说,不用手工去设置控制锁,通过设置事务的隔离级别自动管理锁。

-- 【设置事务的隔离级别】
set transaction isolation level
-- 【事务隔离级别】
read uncommitted
read committed
repeatable read
serializable
测试事务隔离级别为可重复读:
-- 设置为可重复度
set transaction isolation level repeatable read
-- 【事务一】
begin tran
declare @sl int
declare @s2 int
select @sl = qty from sales where id = 'a1'
print(@sl)
waitfor delay '00:00:30.000'
select @s2 = qty from sales where id = 'a1'
print(@s2)
commit tran
-- 【事务二】
begin tran
update sales set qty = qty *2 where id = 'a1'
commit tran
11.3、活锁和死锁
活锁
- 事务T1封锁了数据R
- 事务T2又请求封锁R,于是T2等待。
- T3也请求封锁R,当T1释放了R上的封锁之后系统首先批准了T3的请求,T2仍然等待。
- T4又请求封锁R,当T3释放了R上的封锁之后系统又批准了T4的请求……
- T2有可能永远等待(饿死)。
如何避免活锁
- 采用先来先服务的策略:
- 当多个事务请求封锁同一数据对象时,按请求封锁的先后次序对这些事务排队,该数据对象上的锁一旦释放,首先批准申请队列中第一个事务获得锁。
死锁

解决死锁的方法:
- 采取一定措施预防死锁的发生。
- 允许死锁发生,采取一定方法诊断死锁、解除死锁。
死锁的预防
- 一次封锁法
- 要求每个事务必须一次将所有要使用的数据全部加锁,否则就不能继续执行
- 一次封锁法存在的问题:
- 以后要用到的全部数据加锁,势必扩大了封锁的范围,从而降低了系统的并发度。

-
顺序封锁法:
- 预先对数据对象规定一个封锁顺序,所有事务都按这个顺序实行封锁。
-
顺序封锁法存在的问题
- 数据库系统中可封锁的数据对象极其众多,而且还在不断变化,要维护这样极多而且变化的资源的封锁顺序非常困难,成本很高。
- 事务的封锁请求可以随着事务的执行而动态地决定,很难事先确定每一个事务要封锁哪些对象,因此也就很难按规定的顺序去施加封锁。

死锁的诊断
- 超时法:
- 如果一个事务的等待时间超过了规定的时限,就认为发生了死锁
- 优点:实现简单
- 缺点
- 有可能误判死锁。
- 时限若设置得太长,死锁发生后不能及时发现。
死锁的诊断
- 等待图法:
- 用事务等待图动态反映所有事务的等待情况
- 事务等待图是一个有向图G=(T,U)

- 并发控制子系统周期性地(比如每隔1min)检测事务等待图,如果发现图中存在回路,则表示系统中出现了死锁。
死锁的解除
选择一个处理死锁代价最小的事务,将其撤消,释放此事务持有的所有的锁,使其它事务能继续运行下去。