1、前提
在阅读这篇博客之前,希望你对HashMap已经是有所理解的,否则可以参考这篇博客: jdk1.8源码分析-hashMap;另外你对java的cas操作也是有一定了解的,因为在这个类中大量使用到了cas相关的操作来保证线程安全的。
2、概述
ConcurrentHashMap这个类在java.lang.current包中,这个包中的类都是线程安全的。ConcurrentHashMap底层存储数据的结构与1.8的HashMap是一样的,都是数组+链表(或红黑树)的结构。在日常的开发中,我们最长用到的键值对存储结构的是HashMap,但是我们知道,这个类是非线程安全的,在高并发的场景下,在进行put操作的时候有可能进入死循环从而使服务器的cpu使用率达到100%;sun公司因此也给出了与之对应的线程安全的类。在jdk1.5以前,使用的是HashTable,这个类为了保证线程安全,在每个类中都添加了synchronized关键字,而想而知在高并发的情景下相率是非常低下的。为了解决HashTable效率低下的问题,官网在jdk1.5后推出了ConcurrentHashMap来替代饱受诟病的HashTable。jdk1.5后ConcurrentHashMap使用了分段锁的技术。在整个数组中被分为多个segment,每次get,put,remove操作时就锁住目标元素所在的segment中,因此segment与segment之前是可以并发操作的,上述就是jdk1.5后实现线程安全的大致思想。但是,从描述中可以看出一个问题,就是如果出现比较机端的情况,所有的数据都集中在一个segment中的话,在并发的情况下相当于锁住了全表,这种情况下其实是和HashTable的效率出不多的,但总体来说相较于HashTable,效率还是有了很大的提升。jdk1.8后,ConcurrentHashMap摒弃了segment的思想,转而使用cas+synchronized组合的方式来实现并发下的线程安全的,这种实现方式比1.5的效率又有了比较大的提升。那么,它是如何整体提升效率的呢?见下文分析吧!
3、重要成员变量
1、ziseCtr:在多个方法中出现过这个变量,该变量主要是用来控制数组的初始化和扩容的,默认值为0,可以概括一下4种状态:
a、sizeCtr=0:默认值;
b、sizeCtr=-1:表示Map正在初始化中;
c、sizeCtr=-N:表示正在有N-1个线程进行扩容操作;
d、sizeCtr>0: 未初始化则表示初始化Map的大小,已初始化则表示下次进行扩容操作的阈值;
2、table:用于存储链表或红黑数的数组,初始值为null,在第一次进行put操作的时候进行初始化,默认值为16;
3、nextTable:在扩容时新生成的数组,其大小为当前table的2倍,用于存放table转移过来的值;
4、Node:该类存储数据的核心,以key-value形式来存储;
5、ForwardingNode:这是一个特殊Node节点,仅在进行扩容时用作占位符,表示当前位置已被移动或者为null,该node节点的hash值为-1;
4、put操作
先把源码摆上来:
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
//key和value不能为空
if (key == null || value == null) throw new NullPointerException();
//通过key来计算获得hash值
int hash = spread(key.hashCode());
//用于计算数组位置上存放的node的节点数量
//在put完成后会对这个参数判断是否需要转换成红黑树或链表
int binCount = 0;
//使用自旋的方式放入数据
//这个过程是非阻塞的,放入失败会一直循环尝试,直至成功
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//第一次put操作,对数组进行初始化,实现懒加载
if (tab == null || (n = tab.length) == 0)
//初始化
tab = initTable();
//数组已初始化完成后
//使用cas来获取插入元素所在的数组的下标的位置,该位置为空的话就直接放进去
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//hash=-1,表明该位置正在进行扩容操作,让当前线程也帮助该位置上的扩容,并发扩容提高扩容的速度
else if ((fh = f.hash) == MOVED)
//帮助扩容
tab = helpTransfer(tab, f);
//插入到该位置已有数据的节点上,即用hash冲突
//在这里为保证线程安全,会对当前数组位置上的第一个节点进行加锁,因此其他位置上
//仍然可以进行插入,这里就是jdk1.8相较于之前版本使用segment作为锁性能要高效的地方
else {
V oldVal = null;
synchronized (f) {
//再一次判断f节点是否为第一个节点,防止其他线程已修改f节点
if (tabAt(tab, i) == f) {
//为链表
if (fh >= 0) {
binCount = 1;
//将节点放入链表中
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//为红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
//将节点插入红黑树中
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//插入成功后判断插入数据所在位置上的节点数量,
//如果数量达到了转化红黑树的阈值,则进行转换
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
//由链表转换成红黑树
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//使用cas统计数量增加1,同时判断是否满足扩容需求,进行扩容
addCount(1L, binCount);
return null;
}
在代码上写注释可能看得不是很清晰,那么我就使用文字再来描述一下插入数据的整个流程:
1、判断传进来的key和value是否为空,在ConcurrentHashMap中key和value都不允许为空,然而在HashMap中是可以为key和val都可以为空,这一点值得注意一下;
2、对key进行重hash计算,获得hash值;
3、如果当前的数组为空,说明这是第一插入数据,则会对table进行初始化;
4、插入数据,这里分为3中情况:
1)、插入位置为空,直接将数据放入table的第一个位置中;
2)、插入位置不为空,并且改为是一个ForwardingNode节点,说明该位置上的链表或红黑树正在进行扩容,然后让当前线程加进去并发扩容,提高效率;
3)、插入位置不为空,也不是ForwardingNode节点,若为链表则从第一节点开始组个往下遍历,如果有key的hashCode相等并且值也相等,那么就将该节点的数据替换掉,
否则将数据加入 到链表末段;若为红黑树,则按红黑树的规则放进相应的位置;
5、数据插入成功后,判断当前位置上的节点的数量,如果节点数据大于转换红黑树阈值(默认为8),则将链表转换成红黑树,提高get操作的速度;
6、数据量+1,并判断当前table是否需要扩容;
所以,put操作流程可以简单的概括为上面的六个步骤,其中一些具体的操作会在下面进行详细的说明,不过,值得注意的是:
1、ConcurrentHashMap不可以存储key或value为null的数据,有别于HashMap;
2、ConcurrentHashMap使用了懒加载的方式初始化数据,把table的初始化放在第一次put数据的时候,而不是在new的时候;
3、扩容时是支持并发扩容,这将有助于减少扩容的时间,因为每次扩容都需要对每个节点进行重hash,从一个table转移到新的table中,这个过程会耗费大量的时间和cpu资源。
4、插入数据操作锁住的是表头,这是并发效率高于jdk1.7的地方;
4.1、hash计算的spread方法
/**
* Spreads (XORs) higher bits of hash to lower and also forces top
* bit to 0. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
从源码中可以看到,jdk1.8计算hash的方法是先获取到key的hashCode,然后对hashCode进行高16位和低16位异或运算,然后再与 0x7fffffff 进行与运算。高低位异或运算可以保证haahCode的每一位都可以参与运算,从而使运算的结果更加均匀的分布在不同的区域,在计算table位置时可以减少冲突,提高效率,我们知道Map在put操作时大部分性能都耗费在解决hash冲突上面。得出运算结果后再和 0x7fffffff 与运算,其目的是保证每次运算结果都是一个正数。对于java位运算不了解的同学,建议百度自行了解相关内容。
4.2、java内存模型和cas操作
这里我只是简单的说一下java的内存模型和cas,因为这篇文章的主角的ConcurrentHashMap。
java内存模型:在java中线程之间的通讯是通过共享内存(即我们在变成时声明的成员变量或叫全局变量)的来实现的。Java内存模型中规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存(可以与前面将的处理器的高速缓存类比),线程的工作内存中保存了该线程使用到的变量到主内存副本拷贝,线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,而不能直接读写主内存中的变量。不同线程之间无法直接访问对方工作内存中的变量,线程间变量值的传递均需要在主内存来完成,线程、主内存和工作内存的交互关系如下图所示,和上图很类似。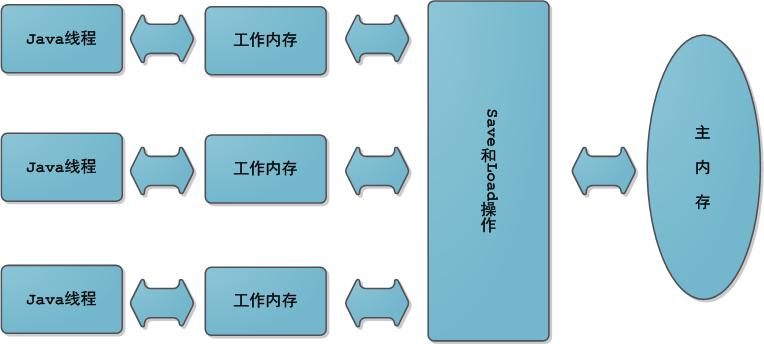
举一个非常简单的例子,就是我们常用的i++的操作,这个操作看起来只有一行,然而在编译器中这一行代码会被编译成3条指令,分别是读取、更新和写入,所以i++并不是一个原子操作,在多线程环境中是有问题了。其原因在于(我们假设当前 i 的值为1)当一条线程向主内存中读取数据时,还没来得及把更新后的值刷新到主内存中,另一个线程就已经开始向主内存中读取了数据,而此时内存中的值仍然为1,两个线程执行+1操作后得到的结果都为2,然后将结果刷新到主内存中,整个i++操作结果,最终得到的结果为2,但是我们预想的结果应该是3,这就出现了线程安全的问题了。
cas: cas的全名称是Compare And Swap 即比较交换。cas算法在不需要加锁的情况也可以保证多线程安全。核心思想是: cas中有三个变量,要更新的变量V,预期值E和新值N,首先先读取V的值,然后进行相关的操作,操作完成后再向主存中读取一次取值为E,当且仅当V == E时才将N赋值给V,否则再走一遍上诉的流程,直至更新成功为止。就拿上面的i++的操作来做说明,假设当前i=1,两个线程同时对i进行+1的操作,线程A中V = 1,E = 1,N = 2;线程B中 V = 1,E = 1,N = 2;假设线程A先执行完整个操作,此时线程A发现 V = E = 1,所以线程A将N的值赋值给V,那么此时i的值就变成了 2 ;线程B随后也完成了操作,向主存中读取i的值,此时E = 2,V = 1,V != E,发现两个并不相等,说明i已经被其他线程修改了,因此不执行更新操作,而是从新读取V的值V = 2 ,执行+1后N = 3,完成后再读取主存中i的值,因为此时没有其他线程修改i的值了,所以E = 2,V = E = 2,两个值相等,因此执行赋值操作,将N的值赋值给i,最终得到的结果为3。在整过过程中始终没有使用到锁,却实现的线程的安全性。
从上面的过程知道,cas会面临着两个问题,一个是当线程一直更新不成功的话,那么这个线程就一直处于死循环中,这样会非常耗费cpu的资源;另一种是ABA的问题,即对i =1进行+1操作后,再-1,那么此时i的值仍为1,而另外一个线程获取的E的值也是1,认为其他线程没有修改过i,然后进行的更新操作,事实上已经有其他线程修改过了这个值了,这个就是 A ---> B ---> A 的问题;
4.3、获取table对应的索引元素的位置
通过(n-1)& hash 的算法来获得对应的table的下标的位置,如果对于这条公式不是很理解的同学可以到: jdk1.8源码分析-hashMap 博客中了解。
tabAt(Node<K,V>[] tab, int i): 这个方法使用了java提供的原子操作的类来操作的,sun.misc.Unsafe.getObjectVolatile 的方法来保证每次线程都能获取到最新的值;
casTabAt(Node<K,V>[] tab, int i,Node<K,V> c, Node<K,V> v): 这个方法是通过cas的方式来获取i位置的元素;
4.4、扩容
- 如果新增节点之后,所在的链表的元素个数大于等于8,则会调用treeifyBin把链表转换为红黑树。在转换结构时,若tab的长度小于MIN_TREEIFY_CAPACITY,默认值为64,
则会将数组长度扩大到原来的两倍,并触发transfer,重新调整节点位置。(只有当tab.length >= 64, ConcurrentHashMap才会使用红黑树。)
- 新增节点后,addCount统计tab中的节点个数大于阈值(sizeCtl),会触发transfer,重新调整节点位置。
/**
* Adds to count, and if table is too small and not already
* resizing, initiates transfer. If already resizing, helps
* perform transfer if work is available. Rechecks occupancy
* after a transfer to see if another resize is already needed
* because resizings are lagging additions.
*
* @param x the count to add
* @param check if <0, don't check resize, if <= 1 only check if uncontended
*/
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
5、get操作
get操作中没有使用到同步的操作,所以相对来说比较简单一点。通过key的hashCode计算获得相应的位置,然后在遍历该位置上的元素,找到需要的元素,然后返回,如果没有则返回null:
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code key.equals(k)},
* then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* @throws NullPointerException if the specified key is null
*/
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
欢迎大家关注公众号: 【java解忧杂货铺】,里面会不定时发布一些技术博客;关注即可免费领取大量最新,最流行的技术教学视频: