1998年10月DOM1级规范成为了W3C的推荐标准,为基本的文档结构及查询提供了接口。
一、Node类型
每个节点都有个nodeType属性,表明了节点的类型。共有12种类型:
元素节点 Node.ELEMENT_NODE(1)
属性节点 Node.ATTRIBUTE_NODE(2)
文本节点 Node.TEXT_NODE(3)
CDATA节点 Node.CDATA_SECTION_NODE(4)
实体引用名称节点 Node.ENTRY_REFERENCE_NODE(5)
实体名称节点 Node.ENTITY_NODE(6)
处理指令节点 Node.PROCESSING_INSTRUCTION_NODE(7)
注释节点 Node.COMMENT_NODE(8)
文档节点 Node.DOCUMENT_NODE(9)
文档类型节点 Node.DOCUMENT_TYPE_NODE(10)
文档片段节点 Node.DOCUMENT_FRAGMENT_NODE(11)
DTD声明节点 Node.NOTATION_NODE(12)
这12个类型并不完全受到浏览器的支持;而开发人员常用的就是前三个(元素节点,属性节点,文本节点)
if(someNode.nodeType==3){
//为了兼容ie,通常将noteType的属性值与数值进行比较
}
此外节点还有nodeNames和nodeValue这两个属性。而这二个属性的值完全取决于节点的类型。
1)对于nodeName来说
元素节点的 nodeName 是标签名称。
属性节点的 nodeName 是属性名称。
文本节点的 nodeName 是 #text。
文档节点的 nodeName 是 #document。
2)对于nodeValue来说
文本节点的nodeValue 属性包含文本。
对于属性节点的nodeValue 属性包含属性值。
文档节点的nodeVlaue为null。
元素节点是nodeVlaue为null。
1.1节点关系:
每个节点都有一个childNodes属性,其中保存着一个NodeList对象,它是基于DOM结构动态执行查询的结果而不是一张初次访问时的快照。
每个节点也都有个parentNode节点,该属性指向文档节点的父节点。childNodes列表中所有的节点都具有相同的父节点。而且它们之间都是同胞节点,可以通过previousSibling和nextSibling互相之间访问,父节点的firstChild和lastChild分别指向childcNodes列表的第一个和最后一个j节点。
1.2操作节点
appendChild()方法:
用于向父节点的chidNodes末尾添加一个节点。如果传入到appendChild()的节点已经是文档中的一部分了,那么该节点会从原来的位置转移到新的位置上。
例如:
<div id="ss">hi
<p>1</p>
<p>2</p>
<p>3</p>
</div> <script> var ss=document.getElementById("ss"); ss.appendChild(ss.firstChild); alert(ss.lastChild.nodeValue);//hi 第一个文本节点 变成了最后一个节点 </script>
insetBefore()方法:
这个方法接受二个参数:要插入的节点和作为参照的节点。插入后被插入的节点会变成参照节点的前一个同胞节点。
如果参照节点是null那么执行和appendChild相同的操作。
replaceChild()方法:
这个方法接受二个参数:要插入的节点和要替换的节点。返回替换的节点。
removeChild()方法:
这个方法接受一个参数,即要移除的节点。返回被移除的节点。
上面的四个方法在调用时,都是在某个节点的子节点上操作,所以都必须先取得它们的父节点!
cloneNode()方法:
该方法接受一个布尔型参数表示是否进行深浅负责,为true时执行深复制(复制节点及其整个子节点树),为false时执行浅复制(只复制节点本身)。
var ss=document.getElementById("ss");var tt=ss.cloneNode(true); ss.appendChild(tt);//复制完后,为他指定父节点,将它添加到文档中
二、Document类型
document对象是HTMLDocument的一个实例,表示整个HTMl页面。
可以通过document.documentElement和document.body来取得对<html>和<body>的引用
文档信息:
document.title包含着<title>元素中文本的引用。
document.URl包含着页面完整的URl。
document.domain包含着页面的域名。它是可读取也可设置的,进而可以对二个页面进行通信设置。
document.referrer保存着链接到当前页面的那个页面的URl。
查找元素:
document.getElementById();
document.getElementsByTagName();
特殊集合:
document.anchors 包含文档中所有带name特性的<a>标签
document.forms 包含文档中所有的<form>元素
document.images 包含文档中所有的<img>元素
document.links 包含文档中所有带href特性<a>元素
文档写入:
document.write()或writeln()
可以在页面加载过程中动态的向页面加入内容。
三、Element类型
Element类型用来表现XML或HTML元素,提供了对元素标签名,子节点及特性的访问。
取得元素的标签名可以使用nodeName或者tagName。
取得特性:
每个元素都有特性,而操作特性的DOM主要有三个方法:
getAttribute() 一般用它来取得自定义的特性
setAttribute() 如果设置的特性已经存在则以指定的值替换它,如果没有则创建它。
removeAttribute()
创建元素:
document.createElement();
三、Text类型
创建文本节点:
document.createTextNode()
分割文本节点:
splitText()
小结:DOM将文档形象地看作一个层次化的节点树,可以用js来操作这个节点树,进而改变底层文档的外观和结构。DOM操作往往是js中开销最大的部分,尽量减少DOM操作。
DOM扩展
选择符API
querySelector() 接受一个css选择符,返回与该模式匹配到的第一个元素。
querySelectorAll() 返回的是所有匹配的元素。
与类相关的扩展:
getElementsByClassName()
classList属性
它有如下的方法:
add() 将给定的字符串值添加到列表中,有就不添加。
contains() 表示列表中是否有给定的值,返回布尔值
remove() 从列表中删除给定的字符串。
toggle() 如果列表中存在给定的值则删除它,没有的话则添加它。
焦点管理
document.activeElement属性 这个属性始终会引用DOM中当前获得焦点的元素。
document.hasFocus()方法
自定义数据属性
h5规定可以为元素添加非标准的属性,只需添加前缀data-。然后可以通过元素的dataset属性来访问自定义属性的值。
innerHTML属性
读模式下会返回调用元素的所有子节点。写模式下,替换调用元素原来的所有子节点。
contains方法
该方法用来检测某个节点是不是另外一个节点的子节点。返回布尔值。
插入文本
innerText、outerText属性
它们都没有被纳入h5的规范。
DOM2和DOM3
DOM2级样式模块
<div id="demo" style="200px;height:200px;border:1px solid #599;"></div> <script> var aa=document.getElementById("demo"); document.write(aa.style.cssText);// 200px; height: 200px; border: 1px solid rgb(85, 153, 153); </script>
设计length的目的就是将其与item()方法配套使用。用for循环获得属性名后就可以进一步用getPropertyValue()来获得属性名的值:
<div id="demo" style="200px;height:200px;border:1px solid #599;"></div> <script> var aa=document.getElementById("demo"); var len=aa.style.length,i,prop,value; for(i=0;i<len;i++){ prop=aa.style[i];//或者aa.style.item(i); value=aa.style.getPropertyValue(prop); document.write(prop+":"+value+"</br>");//竟然有19种属性名,名称是以短划线形式出现,不是驼峰形式。
//200px //height:200px //border-top-1px //border-right-1px //border-bottom-1px //border-left-1px //border-top-style:solid //border-right-style:solid //border-bottom-style:solid //border-left-style:solid //border-top-color:rgb(85, 153, 153) //border-right-color:rgb(85, 153, 153) //border-bottom-color:rgb(85, 153, 153) //border-left-color:rgb(85, 153, 153) //border-image-source:initial //border-image-slice:initial //border-image-initial //border-image-outset:initial //border-image-repeat:initial } </script>
要想删除某个css属性,调用removeProperty()即可:
aa.style.removeProperty("width");//删除后,将应用默认的值
2、计算的样式:
通过style对象可以访问任何支持style特性的元素的样式信息,但不包括从其他样式表层叠而来而影响到当前元素的样式信息。
so,DOM2级样式模块增强了document.defaultView,提供了getComputedStyle()方法。这个方法接受二个参数;要取得计算样式的 元素和一个伪元素字符串,如果不需要伪元素则将它设置为null。
看个例子:
<div id="demo" style="200px;height:200px;"></div> <style>#demo{border:1px solid #789;background:#ccc}</style>
<script> var aa=document.getElementById("demo"); var computedStyle=document.defaultView.getComputedStyle(aa,null); alert(computedStyle.width);//"200px" alert(computedStyle.border);//"1px solid #789" //IE不支持getComputedSytle()方法,但是是在IE中支持style属性的元素还有个currentStyle属性 //这个属性包含当前元素计算后的样式 //var computedStyle=aa.currentSytle; //alert(computedStyle.border); </script>
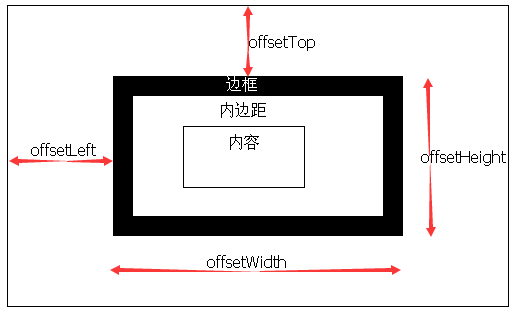
元素大小
偏移量包括元素在屏幕上占用的所有可见空间。元素的可见大小由宽高度来决定,包括内边距,滚动条和边框大小。通过下列四个属性可以获得元素的偏移量。
offsetHeight:元素在垂直方向上占用的空间大小,包括元素的高度,水平滚动条的高度,上下边框的高度。
offsetWidth:元素在水平方向上占用的空间的大小,包括元素的宽度,垂直滚动条的宽度,左右边框的宽度。
offsetLeft:元素的左外边框至包含元素的左内边框之间的像素距离。
offsetTop:元素的上外边框至包含元素的上内边框之间的像素距离。
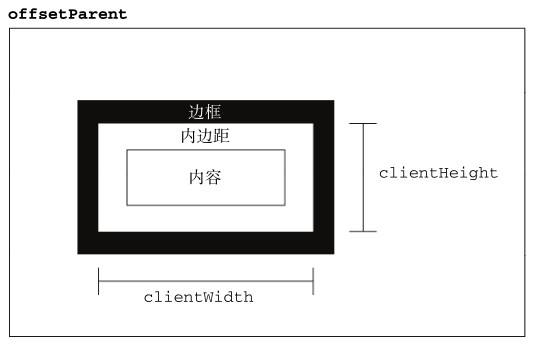
客户区大小
元素的客户区表示的是元素内容及其内边距所占据的空间的大小。
DOM2级遍历和范围模块
“DOM2级遍历和范围”模块定义了两个用于辅助完成顺序遍历DOM结构的类型:NodeIterator和treeWalker。这两个类型能够基于给定的起点对DOM进行深度优先的遍历操作。
nodeIterator类型
可以使用document.createNodeIterator()方法创建它的一个实例。这个方法接受四个参数:
root:表示想要作为搜索起点的树中的节点。
whatToShwo:表示要访问哪些节点的数字代码。
filter:是一个NodeFilter对象,或是一个表示应该接受还是拒绝某种特性的函数。
entiyReferenceExpansion:布尔值,表示是否要扩展实体引用。
whatToShwo参数是一个位掩码,通过应用一个或多个过热器来确定要访问那些节点。这个参数以常量形式在NodeIterator类型中定义。列表如下:
1、NodeFilter.SHOW_ALL:搜索所有节点;
2、NodeFilter.SHOW_ELEMENT:搜索元素节点;
3、NodeFilter.SHOW_ATRRIBUTE:搜索特性节点;
4、NodeFilter.SHOW_TEXT:搜索文本节点;
5、NodeFilter.SHOW_ENTITY_REFERENCE:搜索实体引用节点;
6、NodeFilter.SHOW_ENTITY:搜索实体节点;
7、NodeFilter.SHOW_PROCESSING_INSTRUCTION:搜索PI节;
8、NodeFilter.SHOW_COMMENT:搜索注释节点;
9、NodeFilter.SHOW_DOCUMENT:搜索文档节点;
10、NodeFilter.SHOW_DOCUMENT_TYPE:搜索文档类型节点;
11、NodeFilter.SHOW_DOCUMENT_FRAGMENT:搜索文档碎片节节;
12、NodeFilter.SHOW_NOTATION:搜索记号节点;
nodeIterator类型的两个主要的方法是nextNode()和previousNode()。前者方法用于向前进一步,而后者方法用于向后后退一步。
下面的代码将遍历div元素的所有元素:
<div id="demo"> <p>hello</p>
<ul><li>1</li><li>2</li><li>3</li></ul> </div>
<script> var div=document.getElementById("demo"); var iterator=document.createNodeIterator(div,NodeFilter.SHOW_ELEMENT,null,false); var node=iterator.nextNode(); while(node!==null){ document.write(node.tagName);// 输出标签名:DIV P UL LI LI LI var node=iterator.nextNode(); } </script>
如果不指定过滤器,则第三个参数应该指定为null,如果指定的话我们可以自定义一个过滤器,输出想要的结果:
<script> var div=document.getElementById("demo");
var filter=function(node){
return node.nodeName.toLowerCase()=="li"?NodeFilter.FILTER_ACCEPT:
NodeFilter.FILLTER_SKIP; }; var iterator=document.createNodeIterator(div,NodeFilter.SHOW_ELEMENT,filter,false);
var node=iterator.nextNode(); while(node!==null){ document.write(node.tagName);// 输出标签名:LI LI LI var node=iterator.nextNode(); }
TreeWalker类型
它除了有nextNode()和previousNode()还有下面的这些方法:
parentNode():遍历当前节点的父节点;
firstChild():遍历到当前节点的第一子节点;
lastChild():遍历到当前节点的最后一个子节点;
nextSibling():遍历到当前节点的下一个同辈节点;
previousSibling():遍历到当前节点的前一个兄弟节点。
创建TreeWalker对象要使用document.createTreeWalker()方法,这个方法也接受同样的四个参数:作为搜索起点的根节点,要显示的节点类型,过滤器和表示是否可扩展实体引用的布尔值。
TreeWalker即使不使用过滤器也能够取得遍历到想要的元素。
var div=document.getElementById("demo"); var walker=document.createTreeWalker(div,NodeFilter.SHOW_ELEMENT,null,false); walker.firstChild();//转到p元素 walker.nextSibling();//转到ul元素
var node=walker.firstChild(); while(node!==null){ document.write(node.tagName);// 输出标签名:LI LI LI node=walker.nextSibling(); }