20155321 2016-2017-2 《Java程序设计》第五周学习总结
教材学习内容总结
第八章 异常处理
- Java提供特有的语句进行处理
try
{
需要被检测的代码;
}
catch(异常类 变量)
{
处理异常的代码;(处理方法)
}
finally
{
一定会执行的语句
}
- 对捕获到的异常对象进行常见方法操作
1)String getMessage() 显示异常信息
2)toString() 显示异常名称:异常信息
3) printStackTrace()(无返回值,无需给println)显示异常名称:异常信息:异常出现位置,而JVM默认的异常处理机制就是在调用printStackTrace()方法打印异常的堆栈跟踪信息
-
throws Exception:在功能上通过throws的关键字声明了该功能有可能会出现问题
-
2种处理方式:捕捉,抛出
-
多异常的处理
-
声明异常时,声明更为具体的异常,这样处理得可以更具体
-
对方声明几个异常,就对应有几个catch块,不要定义多余的catch块,且异常间不能有继承关系
-
在进行catch处理时,catch中一定要定义具体处理方式。不要简单定义一句printStackTrace(),不方便后期的处理
- 自定义异常
-
产生原因:因为项目中会出现特有的问题,而这些问题并未被Java所描述并封装对象。所以对于这些特有的问题可以按照Java的对问题封装的思想,将特有的问题进行自定义的异常封装
-
自定义异常:定义类继承Exception或者RuntimeException
1)为了让该自定义类具备可抛性
2) 为了让该类具备操作异常的共性方法
-
手动通过throw抛出一个自定义对象
-
当在函数内部出现了throw抛出异常对象,那么就必须要给对应的处理动作。要么在函数上声明让调用者处理。一般情况下,函数内出现异常,函数上需要声明。
-
定义异常信息的方法:因为父类中已经把异常信息的操作都完成了,所以子类只要在构造时,将异常信息传递给父类通过super语句,那么就可以直接通过getMessage方法获取自定义信息
-
throws和throw的区别:throws使用在函数上,throw使用在函数内;throws后面跟的异常类,可以跟多个,用逗号隔开,throw后面跟的是异常对象
-
特殊子类异常:runtimeexcetption运行时异常,即RuntimeException及其子类 在函数内抛出该异常,函数上不用声明,编译一样通过,如果在函数上声明了该异常,调用者可以不用进行处理(try或抛),编译一样通过
注意:之所以不用在函数上声明,是因为不需要让调用者处理。当该异常发生,希望程序停止,因为在运行时,出现了无法继续运算的情况,希望停止程序后,对代码进行修正。自定义异常时,如果该异常的发生,无法在继续进行运算,就让自定义异常继承RuntimeException
- 对于异常分两种
1)编译时被检测的异常
2)编译时不被检测的异常(运行时异常,RuntimeException以及其子类)
-
finally代码块
定义一定执行的代码,通常用于关闭资源
-
catch是用于处理异常,如果没有catch就代表异常没有被处理过,如果该异常是检测时异常,那么必须声明
-
异常在子父类覆盖中的体现
1) 子类在覆盖父类时,如果父类的方法抛出异常,那么子类的覆盖方法只能抛出父类的异常或者该异常的子类,或者不抛出
2) 如果父类方法抛出多个异常,那么子类在覆盖该方法时,只能抛出父类异常的子集
3) 如果父类或者接口的方法中没有异常抛出,那么子类在覆盖方法时,也不可以抛出异常。如果子类方法发生了异常,就必须要进行try处理,绝对不能抛
第九章 集合与泛型
-
集合类的特点:集合只用于存储对象,集合长度是可变的,集合可以存储不同类型的对象
-
出现这么多的集合容器的原因:因为每一个容器对数据的存储方式都有不同,这个存储方式称之为数据结构
-
集合中存储的不是对象实体,都是(引用)地址
-
Collection

-
List:元素是有序的,元素可以重复,因为该集合体系有索引
1)特有方法:凡是可以操作角标的方法都是该体系特有的方法
2.1)增 add(index,element);
addAll(index,Collection);2.2)删 remove(index);
2.3)改 set(index,element);
2.4)查 get(index);
subList(from,to);
listIterator();3)List集合特有的迭代器:ListIterator是Iterator的子接口
在迭代时,不可以通过集合对象的方法操作集合中的元素,因为会发生并发集合异常ConcurrentModificationException。所以,在迭代时,只能用迭代器的方法操作元素,可是Iterator方法是有限的,只能对元素进行判断,取出,删除的操作,如果想要其他的操作如添加,修改等,就需要使用其子接口,ListIterator
4)该接口只能通过List集合的listIterator方法获取
5)ArrayList:底层的数据结构使用的是数组结构。特点:查询速度很快,但是增删稍慢。线程不同步,效率就高
6)LinkedList:底层使用的是链表数据结构。特点:增删速度很快,查询速度稍慢
特有方法:
6.1)addFirst(),addLast()
6.2)getFirst(),getLast():获取元素,但不删除元素
6.3)removeFirst(),removeLast():获取元素,并删除元素。如果集合没有元素,会出现NoSuchElementException
-
Vector:底层是数组数据结构。功能与ArrayList一样。线程同步,效率低,因此被ArrayList替代了
枚举是Vector特有的取出方式,但其实枚举和迭代时一样的,因为枚举的名称及方法名称都过程,因此被迭代器取代了。
- 堆栈:先进后出(杯子);队列:先进先出(水管)
-
Set:元素是无序(存入和取出的顺序不一定一致),元素不可以重复
1)Set集合的功能和Collection是一致的
2)HashSet:底层数据结构是哈希表,线程是非同步的
3)HashSet保证元素唯一性的方法:通过元素的两个方法,hashCode和equals来完成。如果元素的HashCode值相同,才会判断equals是否为true,如果元素的hashcode值不同,不会调用equals
注意:对于判断元素是否存在以及删除等操作,依赖的方法是元素的hashcode和equals方法
4)TreeSet:可以对Set集合中的元素进行排序,底层数据结构是二叉树,保证元素唯一性的依据是compareTo方法return0
5)TreeSet排序的第一种方式:让元素自身具备比较性,元素需要实现comparable接口,覆盖compareTo方法,这种方式也称为元素的自然顺序,或者叫做默认顺序
6)TreeSet的第二种排序方式:当元素自身不具备比较性时,或者具备的比较性不是所需要的,这时就需要让集合自身具备比较性。
-
比较器:将比较器对象作为参数传递给TreeSet集合的构造函数
1)当默认排序和比较器排序都存在时,以比较器为主
2)定义一个比较器:定义一个类,实现Comparator接口,覆盖compare方法(在集合初始化时,就有了比较方式)
-
泛型:JDK1.5版本后出现的新特性,用于解决安全问题,是一个安全机制
1)好处是既能将运行时期出现的问题ClassCastException转移到了编译时期,方便于程序员解决问题,让运行时期问题减少,安全,又能避免使用强制转换
2)泛型格式:通过<>来定义要操作的引用数据类型,在使用Java提供的对象时,设么时候写泛型呢?
3)通常在集合框架中很常见,只要见到<>就要定义泛型。其实<>就是用来接收类型的,当使用集合时,将集合中要存储的数据类型作为参数传递到<>中即可
4)什么时候定义泛型类?
当类中要操作的引用数据类型不确定的时候,早起定义Object来完成扩展,现在定义泛型来完成扩展
5)泛型类定义的泛型在整个类中有效,如果被方法使用,那么泛型类的对象明确要操作的具体类型后,所有要操作的类型就已经固定了。为了让不同方法可以操作不同类型,而且类型还不确定,那么可以将泛型定义在方法上
6)特殊之处:静态方法不可以访问类上定义的泛型,如果静态方法操作的引用数据类型不确定,可以将泛型定义在方法上
教材学习中的问题和解决过程
-
问题1:为什么set会出现问题?

-
解决方案:因为在整个程序内根本没有出现set变量,应该是students才对
-
问题2:课本P270代码为什么主函数会有出错提示?
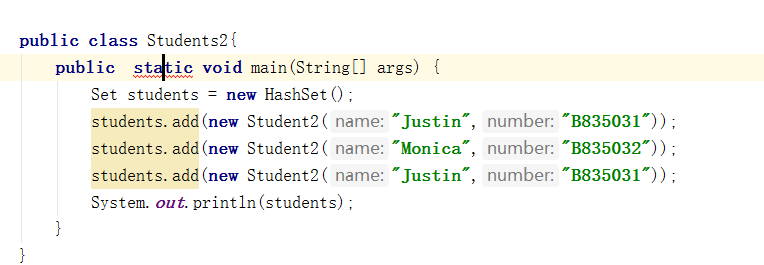
-
解决方案:估计是书本的大括号打错了,上面的Student2类结束的时候少了一个大括号
代码调试中的问题和解决过程
- 问题:课本代码中编译出现了错误

- 解决方案:暂时还并不知道为什么
代码托管

上周考试错题总结
-
错题1:填空:使用JDB进行调试时单步执行命令有step和next,我们优先使用(next)
-
错题2:填空:使用JDB进行调试时查看源代码的命令是(list)
-
错题3:填空:面向对象中,设计经验可以用(设计模式)表达
-
错题4:判断:Math中的abs()方法可以Override.(X)
原因:静态方法属于类,是不能被重写,故而也不能实现多态
理解情况:从API中得知,Math中的abs()方法是静态方法,因此不能被重写
-
错题5:判断:被声明为protected的方法,只能中继承后的子类中访问。(X)
原因:对于protected修饰符,该关键字所修饰的属性和方法在不同包的子类中可见,这是指子类继承了父类中使用protected修饰的属性和方法,而不是指能够使用该父类的对象来访问父类中特定访问修饰符修饰的属性或方法。即使在不同包的子类中定义了父类的对象,访问该父类对象的protected修饰的属性和方法是不能的
理解情况:

-
错题6:填空:写出编译P165 RPG.java的命令(javac –d . *.java)
原因:没写*号
结对及互评
搭档的学习非常认真,值得我好好学习
评分标准(满分10分)
-
从0分加到10分为止
-
正确使用Markdown语法(加1分):
- 不使用Markdown不加分
- 有语法错误的不加分(链接打不开,表格不对,列表不正确...)
- 排版混乱的不加分
-
模板中的要素齐全(加1分)
- 缺少“教材学习中的问题和解决过程”的不加分
- 缺少“代码调试中的问题和解决过程”的不加分
- 代码托管不能打开的不加分
- 缺少“结对及互评”的不能打开的不加分
- 缺少“上周考试错题总结”的不能加分
- 缺少“进度条”的不能加分
- 缺少“参考资料”的不能加分
-
教材学习中的问题和解决过程, 一个问题加1分
-
代码调试中的问题和解决过程, 一个问题加1分
-
本周有效代码超过300分行的(加2分)
- 一周提交次数少于20次的不加分
6 其他加分:
- 周五前发博客的加1分
- 感想,体会不假大空的加1分
- 排版精美的加一分
- 进度条中记录学习时间与改进情况的加1分
- 有动手写新代码的加1分
- 课后选择题有验证的加1分
- 代码Commit Message规范的加1分
- 错题学习深入的加1分
7 扣分:
- 有抄袭的扣至0分
- 代码作弊的扣至0分
点评模板:
-
基于评分标准,我给本博客打分:9。得分情况如下:
点评过的同学博客和代码
其他(感悟、思考等,可选)
本周的学习任务总体而言还是比较重的,学习的内容和深度感觉比以往几个星期都加重了不少。在本周的学习中,我觉得学会查找API给了我较大的帮助,特别是在学习异常和集合框架的时候,主动查API文件可以获取一些课本上没提到的信息进而能扫除学习上的一些障碍,除此之外,对于书本上有错误的代码也要进行主动地排错
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 1/ | 20/20 | 对IDEA、git、JDK、JVM有了更多的了解,面对学习过程中遇到的困难学会自己主动地寻找办法去解决 | |
| 第二周 | 1/2 | 18/38 | 掌握了Java中的基本运算符和基本语句 | |
| 第三周 | 1/3 | 22/60 | 对面向对象、封装、构造函数等重要知识点有了初步理解,学会自主学习,遇到困难的时候从多方面寻找资料以求答案 | |
| 第四周 | 1/4 | 22/60 | 对继承和多态了一定程度的理解,并学会使用多态来提高代码的复用性 | |
| 第五周 | 706/2639 | 1/5 | 25/85 | 对异常以及集合框架的学习 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:20小时
-
实际学习时间:25小时
-
改进情况:看书的效率应该更高,理解力有待提升