| 这个作业属于哪个课程 | 2020春|S班 |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 编写疫情统计程序、熟悉GitHub的使用、制定代码规范 |
| 作业正文 | ... |
| 其他参考文献 | CSDN、博客园、《阿里巴巴Java开发手册》 |
1.GitHub主仓库
https://github.com/kofyou/InfectStatistic-main
2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 30 |
| Estimate | 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 900 | 800 |
| Analysis | 需求分析 (包括学习新技术) | 180 | 150 |
| Design Spec | 生成设计文档 | 30 | 40 |
| Design Review | 设计复审 | 20 | 15 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 40 | 40 |
| Design | 具体设计 | 40 | 30 |
| Coding | 具体编码 | 400 | 320 |
| Code Review | 代码复审 | 60 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 100 | 120 |
| Reporting | 报告 | 150 | 180 |
| Test Repor | 测试报告 | 30 | 40 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 40 |
| 合计 | 1100 | 1050 |
3.解题思路
3.1初步分析
一开始看到题目时,我首先注意到的是其中三个点:命令行、main函数参数、文件操作。最开始学Java的时候有接触过命令行运行,如今已经忘了,更不用说main函数参数了。
我把程序分为三大模块,用户操作(命令行)模块、数据存储模块、文件读写模块。用户操作(命令行)模块对应一个Controller类。数据存储模块里有一个统计所有数据的类Statistics,以及对应省份(或者全国)的AreaInformation类。文件读写模块对应一个FileProcessor类,用于处理任何和文件有关的操作。
3.2 Controller类
Controller类用于处理用户操作。其数据成员用于保存用户输入的参数,即输入文件夹位置、输出文件夹位置、指定省份列表、指定类型列表、指定日期。Controller类只有一个方法,即用于解析参数的GetParameters()方法,该方法接收一个字符串数组(args[ ]),然后将其中的指令和参数分离出,再存入对于的数据对象里。
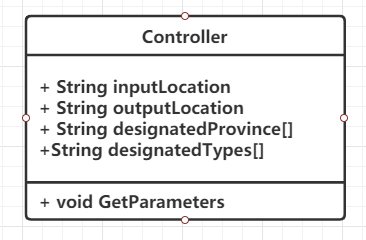
3.3 FileProcessor类
程序中所有和文件有关的操作都由FileProcessor类来执行。其中的主要方法有:创建输出文件、单行读取、单文件读取、多文件读取、文件输出等。
FileProcessor类的核心是三个读取方法。这三个方法通过反复调用下一级方法的方式实现读取指定文件的效果。

3.4 AreaInformation类
AreaInformation类是程序数据存储的基本单元,一个AreaInformation对象对应一个省(或者全国)。其中数据成员有省份名、感染人数、疑似人数、被治愈人数、死亡人数,主要方法有各类人数的Set方法,以及一个返回值为String的Output方法。
Output就是输出文件里一行的信息,返回的格式是“某地 感染患者多少人 疑似患者多少人 治愈多少人 死亡多少人”。在FileProcessor类输出文件的时候,依次调用目标AreaInformation对象的Output方法,就可以输出所有统计信息了。
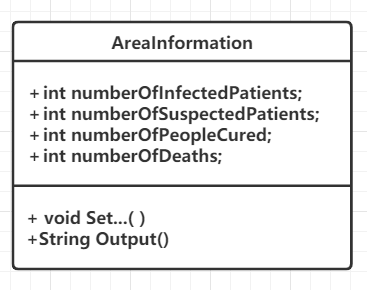
3.5 Statistics类
Statistics类是统计类,用于统计所有AreaInformation对象的信息。其中主要数据成员有:省份名列表(用于初始化用)、省份对象列表、省份名-列表索引值键值对、输出判断位列表等。主要方法是各种添加统计数据的方法。
其中输出判断位在向文件输出信息时使用,程序会先判断省份对应的输出是否为1,若为1则调用AreaInformation对象的Output方法,输出省份的信息。

4.实现流程
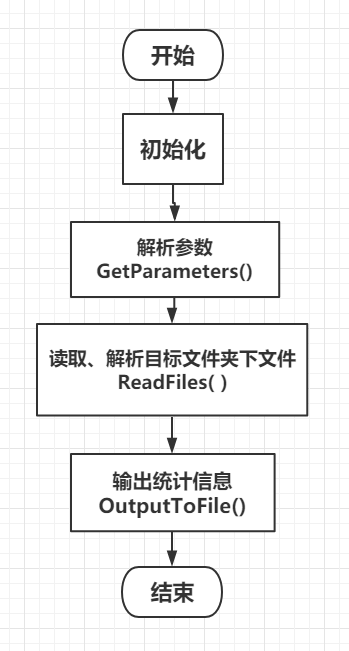
4.1总流程
程序的总流程在main函数里实现,即初始化—解析参数—读取、解析目标文件夹下文件—输出统计信息四个步骤。
public static void main(String[] args){
// 初始化区域类
for (int i0 = 0,l=Statistics.nameOfAreas.length; i0 < l; i0++){
Statistics.Areas[i0] = new AreaInformation(Statistics.nameOfAreas[i0]);
Statistics.indexOfAreas.put(Statistics.nameOfAreas[i0],i0);
}
Statistics.KeyOfOutput[0] = 1;
Controller.GetParameters(args); // 获取输入的参数
FileProcessor.CreateOutputFile(); // 创建输出文件
FileProcessor.ReadFiles(Controller.inputLocation);
try {
FileProcessor.OutputToFile();
} catch (IOException e) {
e.printStackTrace();
}
}
总流程图如下:
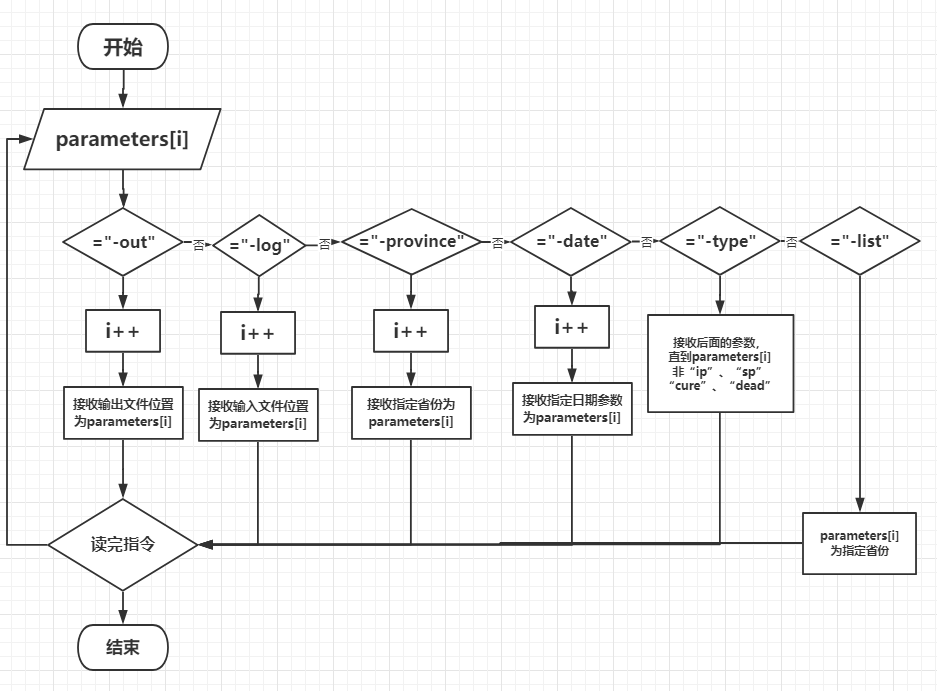
4.2解析参数
解析参数的过程有Controller类的GetParameters方法完成,该方法使用一个大型switch将各个指令及指令后的参数从命令行输入中提取出来。
流程图如下:
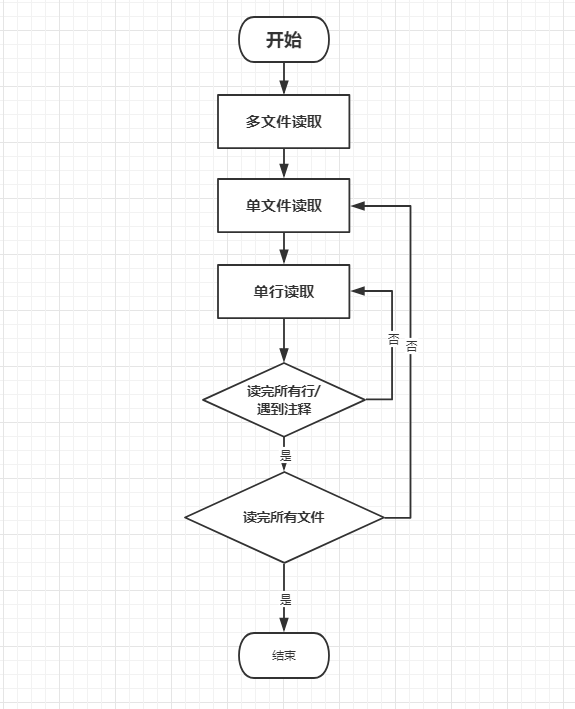
4.3读取文件
读取文件由FileProcessor类的ReadFiles方法完成。该方法由一个三级嵌套构成,即多文件读取(ReadFiles)—单文件读取(ReadASingleFile)—单行读取(ReadASingleLine)。
流程图如下:
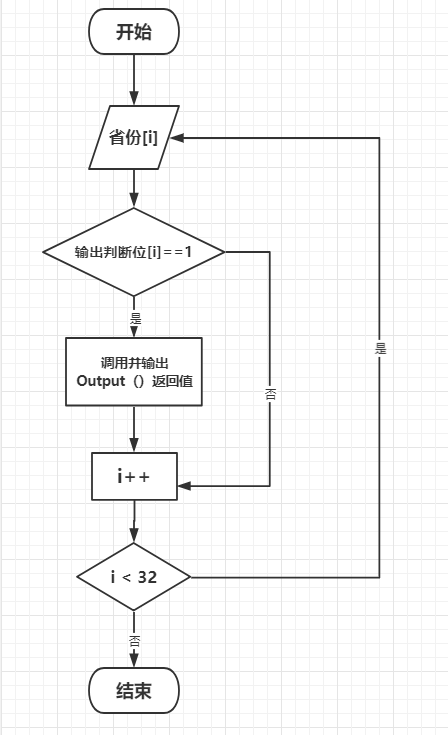
4.4输出
文件输出由FileProcessor.OutputToFile()完成。OutputToFile方法中调用了所有省份对象的Output方法来获得省份信息。并通过输出对应的判断位来判断是否输出该省信息。
其流程如下:
5.代码说明
5.1 初始化
初始化过程主要建立起一个包含32个AreaInformation对象的数组。每个对象对应一个省(或者全国)。然后初始化省份名-索引值键值对数组。最后将“全国”对象的输出判断位置为1(因为所有情况都会输出全国的统计信息)。
public static String[] nameOfAreas = {"全国","安徽", "北京","重庆","福建","甘肃", "广东", "广西", "贵州", "海南",
"河北", "河南", "黑龙江", "湖北", "湖南", "吉林", "江苏", "江西", "辽宁", "内蒙古", "宁夏", "青海",
"山东", "山西", "陕西", "上海", "四川", "天津", "西藏", "新疆", "云南", "浙江"};
for (int i0 = 0,l=Statistics.nameOfAreas.length; i0 < l; i0++){
Statistics.Areas[i0] = new AreaInformation(Statistics.nameOfAreas[i0]);
Statistics.indexOfAreas.put(Statistics.nameOfAreas[i0],i0);
}
Statistics.KeyOfOutput[0] = 1;
5.2 获取参数
获取参数部分由Controller类的GetParameters方法完成,该方法通过一个大型switch来分离出各种参数,并将其存入Controller类中。
public static void GetParameters(String[] parameters){
//获得输入信息
for (int i0 = 0,l = parameters.length;i0 < l;i0++){
switch (parameters[i0]){
case ("-out"):
i0++;
Controller.outputLocation=parameters[i0];
break;
case ("-log"):
i0++;
Controller.inputLocation=parameters[i0];
break;
case ("-province"):
i0++;
Controller.designatedProvince[numberOfDesignatedProvince]=parameters[i0];
numberOfDesignatedProvince++;
break;
case ("-date"):
i0++;
Controller.designatedDate=parameters[i0];
break;
case ("-type"):
i0++;
while (true){
if (parameters[i0].equals("ip")||parameters[i0].equals("sp")||
parameters[i0].equals("cure")||parameters[i0].equals("dead")){
Controller.designatedTypes[Controller.numberOfTypes]=parameters[i0];
i0++;
Controller.numberOfTypes++;
}
else {
i0--;
break;
}
}
break;
case ("list"):
break;
default:
Controller.designatedProvince[numberOfDesignatedProvince]=parameters[i0];
Statistics.KeyOfOutput[Statistics.GetIndexOfArea(parameters[i0])] = 1;
numberOfDesignatedProvince++;
}
}
// 处理没有输入-type的情况
if (Controller.numberOfTypes == 0){
Controller.numberOfTypes = 4;
designatedTypes=new String[]{"ip","sp","cure","dead"};
}
// 处理没有输入-province的情况
if (Controller.numberOfDesignatedProvince == 0){
Controller.numberOfDesignatedProvince = 1;
designatedProvince=new String[]{"全国"};
}
}
5.3 多文件读取
多文件读取由FileProcessor类的ReadFiles方法实现。ReadFiles方法会进入指定的log路径,然后开始一个个处理路径下的文件。若文件的日期小于等于指定日期,则调用单文件读取方法读取该文件。
public static void ReadFiles(String path) {
ArrayList<String> listFileName = new ArrayList<String>();
GetAllFileName(path, listFileName);
for (String name : listFileName) {
if (FileProcessor.ComparingTheDate(name)) {
FileProcessor.ReadASingleFile(name);
}
}
}
5.4 单文件读取
单文件读取方法是读取三阶段中的中间步骤,由FileProcessor类的ReadASingleFile方法实现。该方法会一行行读取指定文件的内容,然后将每一行的信息交给单行读取方法来操作。若单行读取方法读到注释部分,则停止读取。
public static void ReadASingleFile(String path){
File file = new File(path);
StringBuilder result = new StringBuilder();
try{
//构造一个BufferedReader类来读取文件
BufferedReader reader = new BufferedReader(
new InputStreamReader(new FileInputStream(file),"UTF-8"));
String line = null;
while((line = reader.readLine())!=null){
if (!FileProcessor.ReadASingleLine(line)){
break;
}
}
reader.close();
}catch(Exception e){
e.printStackTrace();
}
}
5.5 单行读取
FileProcessor类的ReadSingleLine方法用于执行单行读取。该方法有一个布尔型的返回值,在读取到注释行的“//”时将返回false,来使单文件读取方法停止。该方法同样使用一个大型switch来实现,对于每一种情况会调用对应的Statistics.Add某某方法。每读到一个省份,就会将该省份对应的输出判断位置1。
public static boolean ReadASingleLine(String line){
String words[] = line.split(" ");
String number; // 用于记录数
int num;
int indexOfArea = 0; // 每行最开始的地区的数组索引
int indexOfTarge = 0;
if (words[0].equals("//")){
return false; // 首先判断这行是不是注释内容
}
indexOfArea = Statistics.GetIndexOfArea(words[0]); // 获得地区索引
Statistics.KeyOfOutput[indexOfArea] = 1; // 把该地区的输出key设为1
// 开始按照后面的输入操作地区类
for (int i0 = 1,l = words.length;i0 < l;i0++) {
switch (words[i0]){
case ("新增"):
i0++;
switch (words[i0]){
case ("感染患者"):
i0++;
num = FileProcessor.GetNumber(words[i0]);
Statistics.AddInfectedPatients(num,indexOfArea);
break;
case ("疑似患者"):
i0++;
num = FileProcessor.GetNumber(words[i0]);
Statistics.AddSuspectedPatients(num,indexOfArea);
break;
}
break;
case ("治愈"):
i0++;
num = FileProcessor.GetNumber(words[i0]);
Statistics.AddCured(num,indexOfArea);
break;
case ("死亡"):
i0++;
num = FileProcessor.GetNumber(words[i0]);
Statistics.AddDeaths(num,indexOfArea);
break;
case ("排除"):
i0 += 2;
num = FileProcessor.GetNumber(words[i0]);
Statistics.Areas[0].numberOfSuspectedPatients -= num;
Statistics.Areas[indexOfArea].numberOfSuspectedPatients -= num;
break;
case ("感染患者"):
i0 += 2;
indexOfTarge = Statistics.GetIndexOfArea(words[i0]);
i0++;
num = FileProcessor.GetNumber(words[i0]);
Statistics.Areas[indexOfArea].numberOfInfectedPatients -= num;
Statistics.Areas[indexOfTarge].numberOfInfectedPatients += num;
break;
case ("疑似患者"):
i0++;
switch (words[i0]){
case ("确诊感染"):
i0++;
num = FileProcessor.GetNumber(words[i0]);
Statistics.AddInfectedPatients(num,indexOfArea);
Statistics.Areas[0].numberOfSuspectedPatients -= num;
Statistics.Areas[indexOfArea].numberOfSuspectedPatients -= num;
break;
case ("流入"):
i0 ++;
indexOfTarge = Statistics.GetIndexOfArea(words[i0]);
i0++;
num = FileProcessor.GetNumber(words[i0]);
Statistics.Areas[indexOfArea].numberOfSuspectedPatients -= num;
Statistics.Areas[indexOfTarge].numberOfSuspectedPatients += num;
}
}
}
return true;
}
5.6 输出信息
在读取完所有的数据后,程序将调用FileProcessor的OutputToFile方法,将统计信息类Statistics里的信息输出至输出文件夹。OutputToFile主要进行一个循环,依次判断省份的输出判断位是否为1,若是则调用并输出AreaInformation对象的Output方法的返回值。
public static void OutputToFile() throws IOException {
BufferedWriter writer = null;
writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(Controller.outputLocation,true),"UTF-8"));
for (int i0 = 0;i0 < 32;i0++){
if (Statistics.KeyOfOutput[i0] == 1){
writer.write(Statistics.Areas[i0].Output()+"
");
}
}
writer.flush();//刷新内存,将内存中的数据立刻写出。
writer.close();
}
6.单元测试
做单元测试的时候就简单地看了一些CSDN上JUnit4的教程并在IDEA里导入了JUnit4框架和相关插件。
按照我的初步理解,我们需要把要测试的函数放到@Test下,然后在IDEA左下角就能看到被测方法运行的时间了。

但是实际操作的时候发现我的方法里调用了很多其他类的数据对象,如果想用上述方法测试要重写目标方法,把其他类的数据对象分离出来。
最后我只能在@Before里进行初始化,在@Test里放测试方法,并插入long l = System.currentTimeMillis();语句来输出目标方法执行时间。有一种给你个电饭煲让你做饭,你却把它当柴火烧了的感觉。
public class InfectStatisticTest {
@Before
public void setUp() throws Exception {
InfectStatistic ret = new InfectStatistic();
// 初始化区域类
for (int i0 = 0, l = InfectStatistic.Statistics.nameOfAreas.length; i0 < l; i0++){
InfectStatistic.Statistics.Areas[i0] = new InfectStatistic.AreaInformation(InfectStatistic.Statistics.nameOfAreas[i0]);
InfectStatistic.Statistics.indexOfAreas.put(InfectStatistic.Statistics.nameOfAreas[i0],i0);
}
InfectStatistic.Statistics.KeyOfOutput[0] = 1;
String argsForTest ="java InfectStatistic list -date 2020-01-27 -log D:/log/ -out D:/output.txt";
InfectStatistic.Controller.GetParameters(argsForTest.split(" ")); // 获取输入的参数
}
@Test
public void main() {
long l = System.currentTimeMillis();
InfectStatistic.Statistics.Areas[0].OutputInformation();
l = System.currentTimeMillis()-l;
System.out.println("目标方法执行了"+l+"毫秒");
}
}
主要方法的测试结果如下:
-
ReadFiles方法(多文件读取):

-
ReadASingleFile方法(单文件读取):

- GetIndexOfArea(获得省份对应索引值):
一开始GetIndexOfArea方法是用遍历输出的方式来获得键值对的。其单次执行时间如下:

获取32个索引值的执行时间如下:

后来我添加了一个省份名-索引值的键值对数组,也把GetIndexOfArea方法改为了相应的哈希表操作。优化后单次执行时间如下:

获取32个索引值的执行时间如下:

7.覆盖率、性能测试与优化
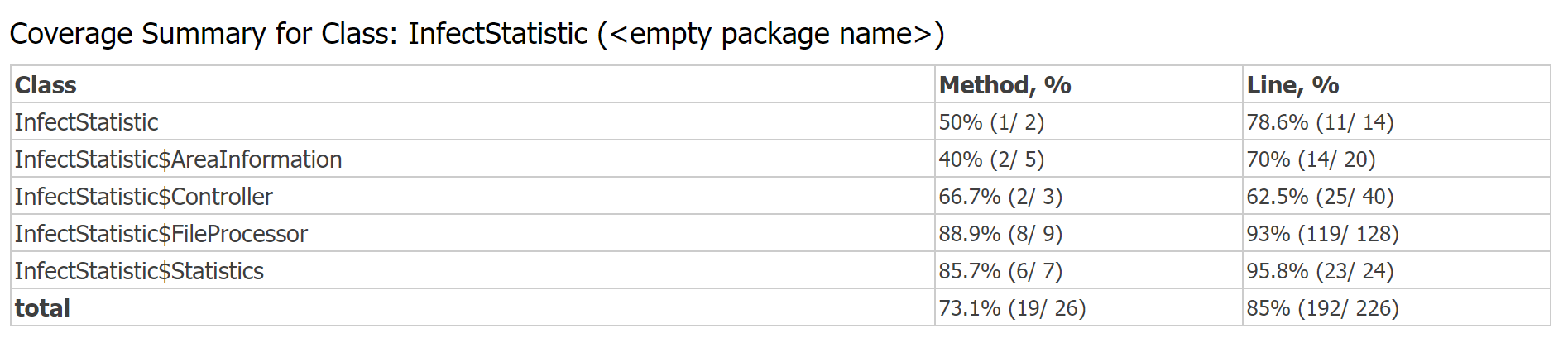
7.1 覆盖率
覆盖率测试使用的是IDEA自带的Run with coverage功能,测试结果如下:
7.2 性能测试
性能测试使用的是JProfiler工具,总览如下:

内存占用如下:
7.3 优化
1.添加了新的省份名-索引值键值对数组,重写搜索省份名返回数组索引值的GetIndexOfArea方法。将依次遍历改成了哈希表操作。
优化前:
public static int GetIndexOfArea(String nameOfArea){
int res=0;
for(int i0 = 0;i0 < 32;i0++){
if (BasicInformation.nameOfAreas[i0].equals(nameOfArea)){
res = i0;
break;
}
return res;
}
优化后:
public static int GetIndexOfArea(String nameOfArea){
if (!Statistics.indexOfAreas.containsKey(nameOfArea)){
return 0;
}
return Statistics.indexOfAreas.get(nameOfArea);
}
2.修改了for循环中的条件变量。
优化前:
for (int i0 = 0;i0 < BasicInformation.nameOfAreas.length;i0++)
优化后:
for (int i0 = 0,l=Statistics.nameOfAreas.length; i0 < l; i0++)
8.代码规范
借此作业机会买了本《阿里巴巴Java开发手册》看,并根据里面的内容并结合我的习惯初步制定了代码风格。《手册》内容还没看完,今后还会慢慢改进我的代码风格。
代码风格GitHub连接:
https://github.com/RadishBEAR/InfectStatistic-main/blob/master/221701231/codestyle.md
9.心路历程
我一向觉得,软件工程的作业分两种,一种广,一种深。像数据库大作业就属于广的范畴,使用的技术可以不难不复杂,但是有一定综合性。算法作业属于深,一门学问钻到最底下。而此次实践也属于广,且相对较广。作业涉及的GitHub、JUnit、JProfiler等技术也给了我一种工业化编程的感觉。
这次作业是我第一次实际操作GitHub,也是第一次学习和使用了JUnit和JProfiler。虽然都只是学习了一点,用了一点,但是知道了这些技术的存在。今后也会慢慢使用JUnit和JProfiler来测试、优化代码了。当然对于现在只能感叹一句内容很多,学得不够,学得不精。希望今后能慢慢跟进上各种技术的学习。
10.GitHub仓库
1.Vue Notification
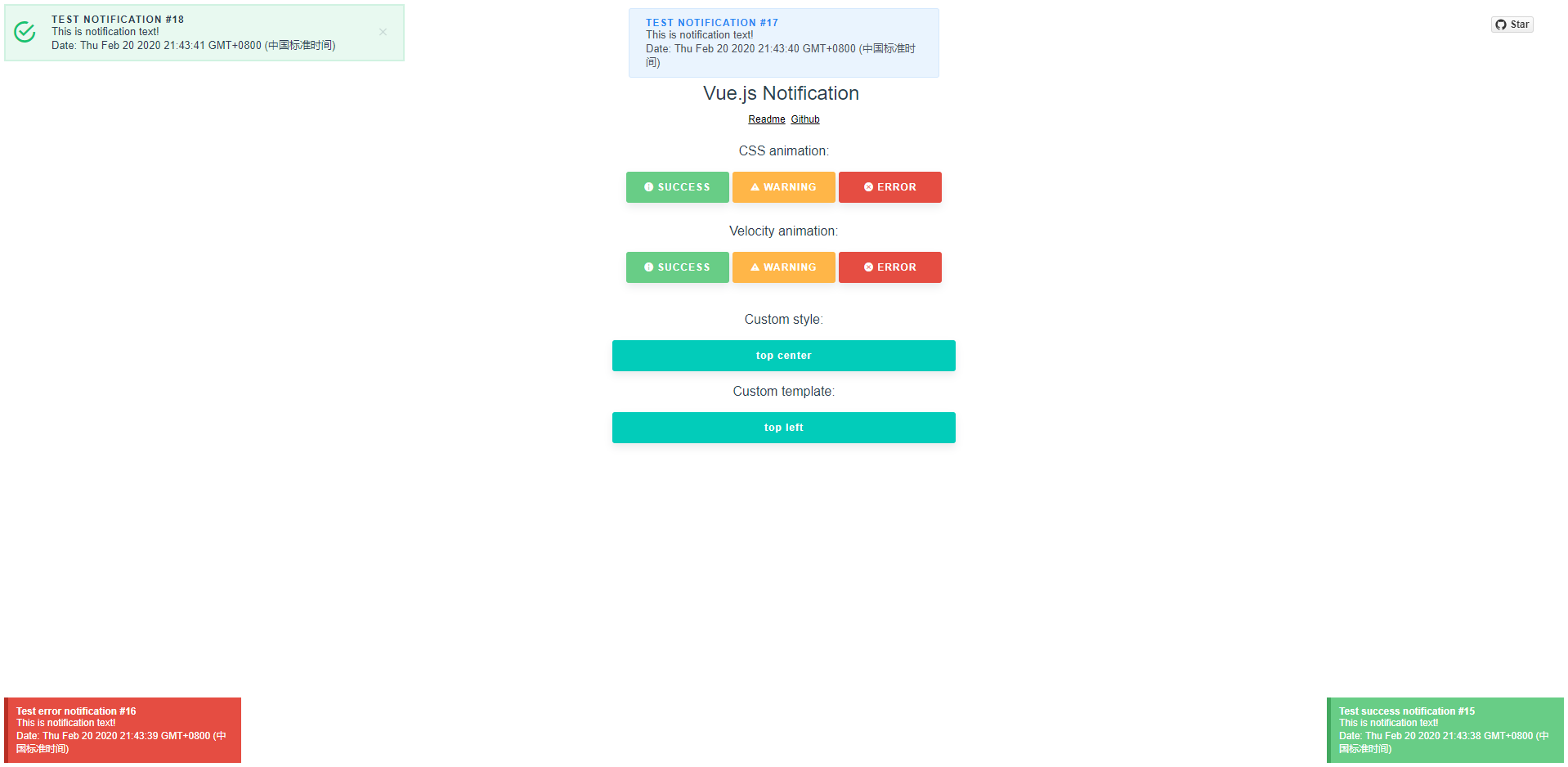
Web应用中常涉及通知和警告,而Vue Notification可以为网页提供通知、警告组件。
Vue Notification用在 Vue.js 应用程序中的成功、警告和错误通知。可以放在右侧、左侧、底部、顶部或中间,任何开发者想要的地方。
https://github.com/euvl/vue-notification
2.Epic Spinners
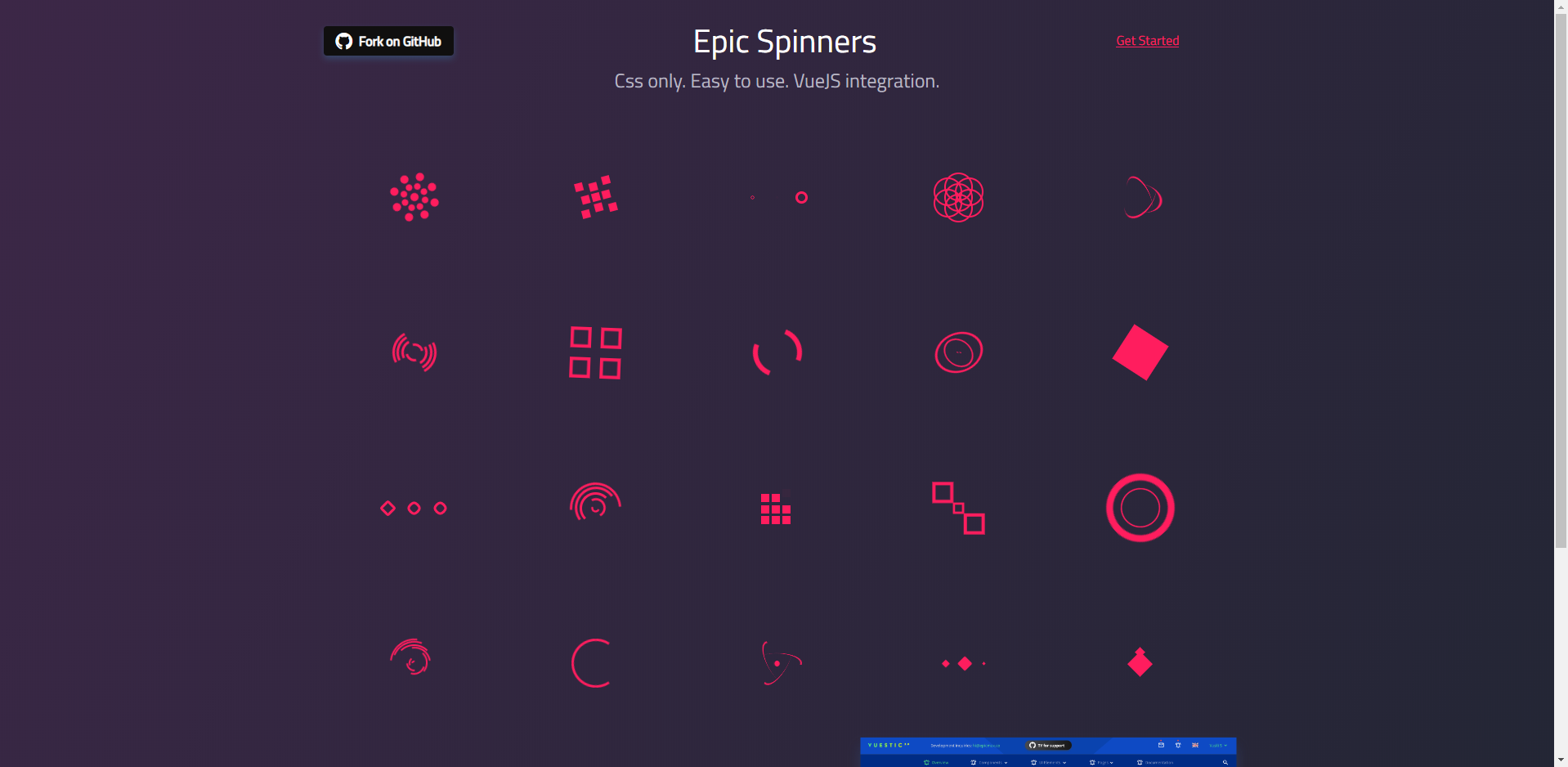
该仓库内置了20个易于使用的CSS调节器。它们既可以作为html / css代码片段,也可以很容易地自定义vue.js组件。
这些效果美观且专业,只需稍微部署即可在程序中使用。
https://github.com/epicmaxco/epic-spinners
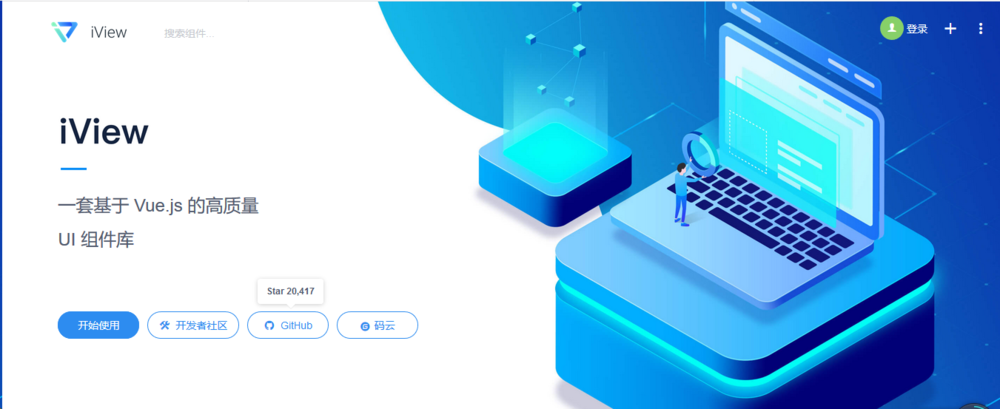
3.iView UI
一套基于 Vue.js 的高质量UI 组件库,主要服务于 PC 界面的中后台产品,过去的两年里,iView 开源项目已经帮助成千上万的开发者快速完成网站开发,大幅度提高了开发效率,成为 Vue.js 生态里重要的一部分。
https://github.com/TalkingData/iview-weapp
4.ElementUI
element ui框架的按钮组件,这款由饿了么前端开源的UI框架,一经面世,就收获大量程序员的芳心。在github 上更是高达29.8k的star早已说明一切。用于开发PC端的页面还是绰绰有余的。
https://github.com/ElementUI/element-starter
5.基于 iView 的 Vue 2.0 管理系统模板

许多网站的都包含后台系统,这个基于 iView 的 Vue 2.0 管理系统模板能够帮助我们部署简单、实用、美观的后台网页,且易学,上手快。