这一小节要介绍两个内容, 一个是 DatetimeIndex 日期索引, 另一个是 Resample, 这是一个函数, 可以通过参数的设置, 来调整数据的查询条件, 从而得到不同的结果.
首先看下关于 DatetimeIndex 的内容, 照例先引入一个csv 文件作为数据基础:
import pandas as pd
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/14_ts_datetimeindex/aapl.csv')
df.head()
输出: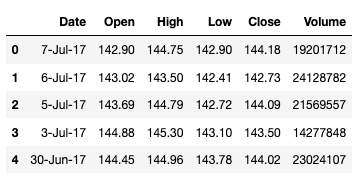
查看一下 Date 列的数据类型:
type(df.Date[0])
输出:
str
从数据结果来看, 目前的 Date 列存储的是字符串, 这显然是不适合用来做数据分析的, 需要转换成时间类型才可以:
import pandas as pd
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/14_ts_datetimeindex/aapl.csv', parse_dates=['Date'], index_col='Date')
df.head()
输出: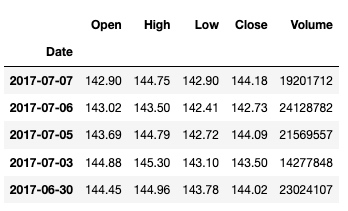
这里在引入数据的同时, 用 parse_dates 参数将 Date 列转成了 时间类型, 并把 Date 列设置为索引列, 因为我们后面的数据分析都会基于日期.
查看一下索引:
df.index
输出:
DatetimeIndex(['2017-07-07', '2017-07-06', '2017-07-05', '2017-07-03',
'2017-06-30', '2017-06-29', '2017-06-28', '2017-06-27',
'2017-06-26', '2017-06-23',
...
'2016-07-22', '2016-07-21', '2016-07-20', '2016-07-19',
'2016-07-18', '2016-07-15', '2016-07-14', '2016-07-13',
'2016-07-12', '2016-07-11'],
dtype='datetime64[ns]', name='Date', length=251, freq=None)
上面输出的最后一行有: dtype='datetime64[ns]', 证明 Date 列的数据类型已经从字符串变成了时间. 那么, 下面就尝试着根据索引来查看一些数据:
查看 2017年1月的所有数据:
df['Jan, 2017']
输出: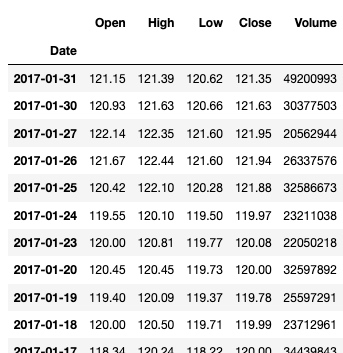
查看 2017年1月闭市数据的平均值:
df['Jan, 2017'].Close.mean()
输出:
119.57000000000001
查看具体某一天的数据:
df['2017-01-03']
输出:
查看某几天的数据:
df['2017-01-07':'2017-01-01']
输出: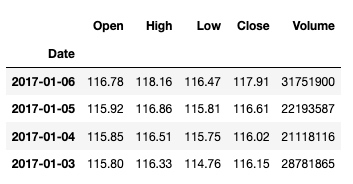
以上, 就是关于 DatetimeIndex 要跟大家分享的内容了, 总结一下, 可以看到我们只要把日期列设置为索引列, 并且保证其数据类型是时间, 就可以利用这个索引灵活地操作数据了.
下面我们来看下关于 resample() 函数的使用:
df.Close.resample('M').mean()
输出:
Date
2016-07-31 99.473333
2016-08-31 107.665217
2016-09-30 110.857143
2016-10-31 115.707143
2016-11-30 110.154286
2016-12-31 114.335714
2017-01-31 119.570000
2017-02-28 133.713684
2017-03-31 140.617826
2017-04-30 142.886842
2017-05-31 152.227727
2017-06-30 147.831364
2017-07-31 143.625000
Freq: M, Name: Close, dtype: float64
这里我们可以一步一步来看, 首先我们要获取所有的闭市数据, 在这个数据基础上又通过 resample() 函数加以加工, 函数里传的参数是 M, 就是 month 的缩写, 也就是我们要以月为单位, 也就是说要每个整月的数据, 那要每个月的什么值, 这个是必须要指定的, 否则计算机不知道是返回每个月的合计,还是最小值, 还是平均值等等, 所以后面用了 mean(), 也就是说要去平均值.
还可以将数据以图表的形式输出:
df.Close.resample('W').mean().plot()
输出: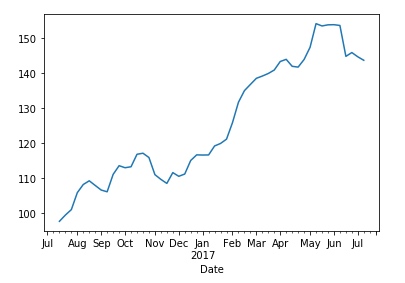
以季度为单位输出柱形图:
df.Close.resample('Q').mean().plot(kind='bar')
输出: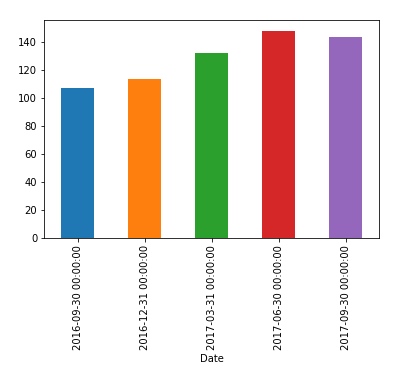
关于 resample 的具体用法, 大家还是可以按照上节课介绍的, 通过快捷键 shift+tab 查看, 它的参数有很多种, 除了我们上面介绍的 M, W, Q, 还有 D, B 等等.
以上, 有问题就给我留言吧, 希望共同进步, enjoy~~