这节的主题是 stack 和 unstack, 我目前还不知道专业领域是怎么翻译的, 我自己理解的意思就是"组成堆"和"解除堆". 其实, 也是对数据格式的一种转变方式, 单从字面上可能比较难理解, 所以给大家下面两张图来理解一下:

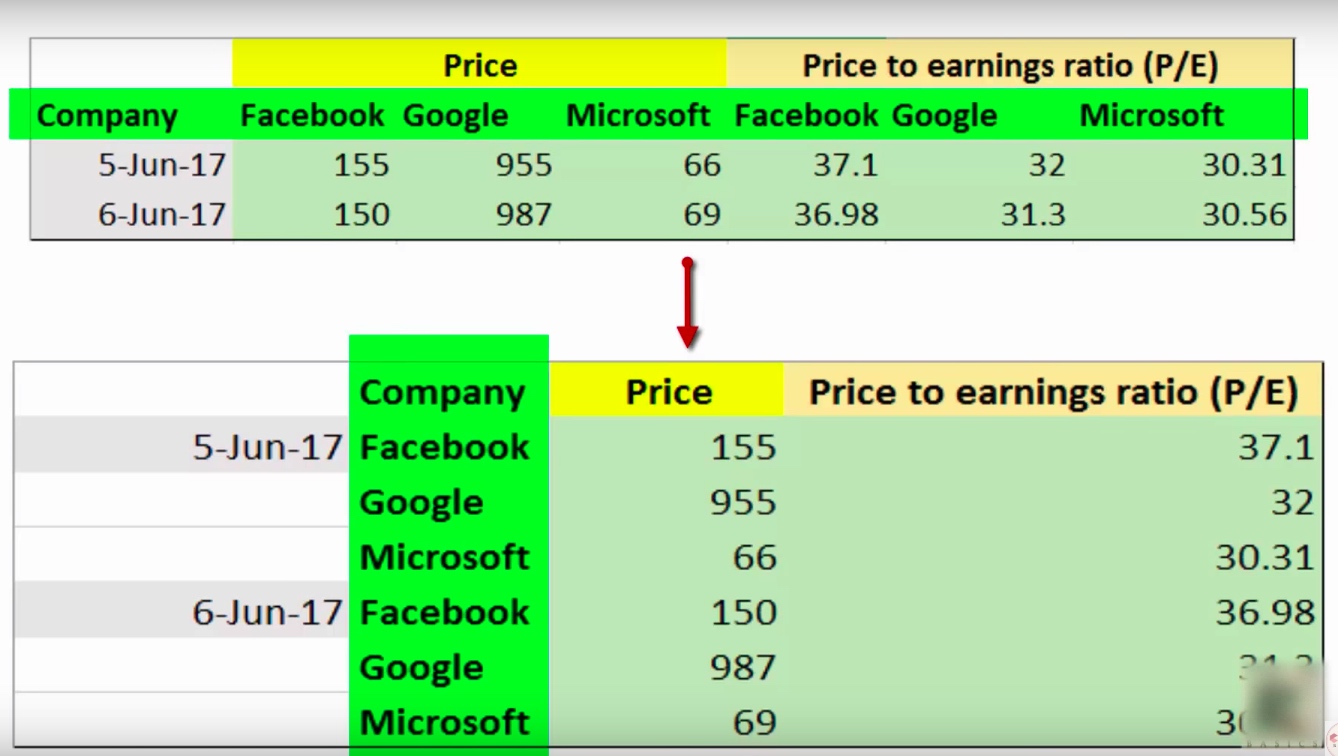
上图中, 标绿色的部分, 代表一个对应关系, 就是列的级别转为行级别.
下面来看下具体实现. 首先引入文件, 通过原表, 我们可以看到有两行表头, 所以这里要多加个参数 header=[0,1]:
df = pd.read_excel('/Users/rachel/Sites/pandas/py/pandas/12_stack/stocks.xlsx', header=[0,1])
输出:
用 stack() 方法改变一下格式, 看会是什么效果:
df_stacked = df.stack()
df_stacked
从输出可以看到, 原来的数据结构是有两行表头, 经过 stack 之后, 就变成一行了, 也就是 Facebook Google Microsoft 这一行, 从原来的列名, 变成了索引: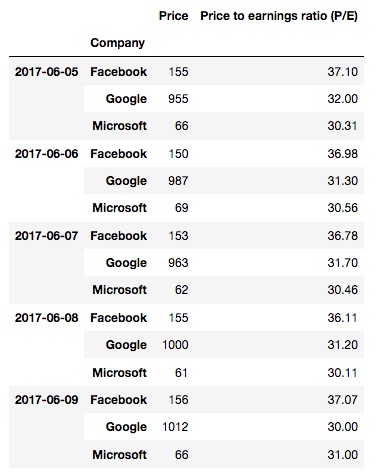
那我们现在再 unstack 看看:
df_stacked.unstack()
输出:
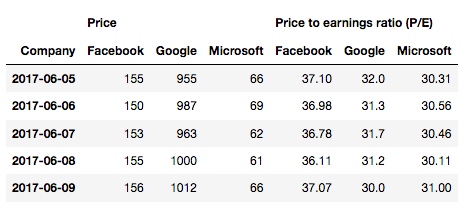
发现, unstack 之后, 整个数据结构又变回去了.
那我们现在再来重新 stack 一下, 并且加个参数 level=0, 也就是将第一行的表头堆叠成索引列:
df.stack(level=0)
输出: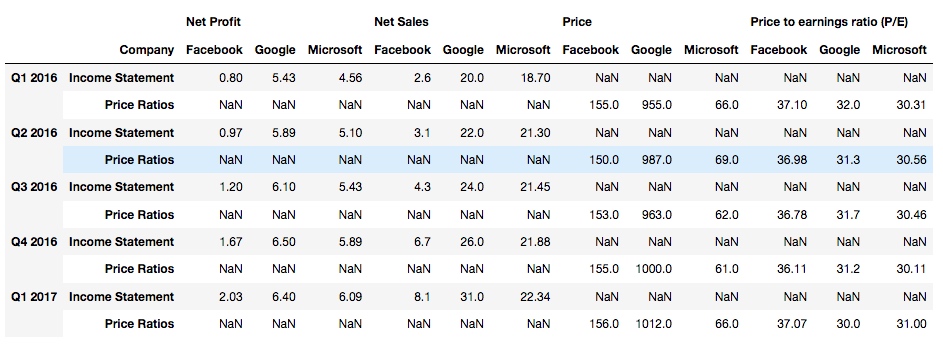
下面再来看一个更复杂点的例子, 这个表格中有三行表头:
df2 = pd.read_excel('/Users/rachel/Sites/pandas/py/pandas/12_stack/stocks_3_levels.xlsx', header=[0,1,2])
输出:
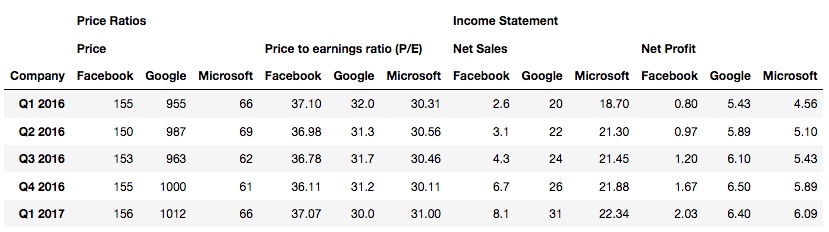
首先 stack 一下:
df2.stack()
输出, 我们看到最下面一行表头被堆叠到索引列了: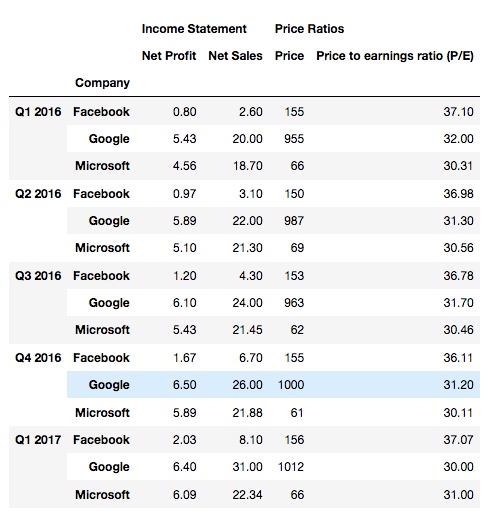
再试一下将 level 参数设为 0:
df2.stack(level=0)
发现, 第一行表头被 stack 了: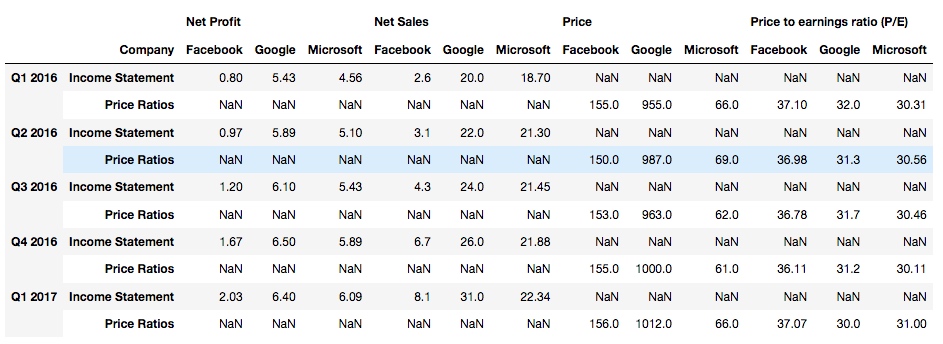
再设置 level=1:
df2.stack(level=1)
输出, 这次是第二行表头被 stack 了: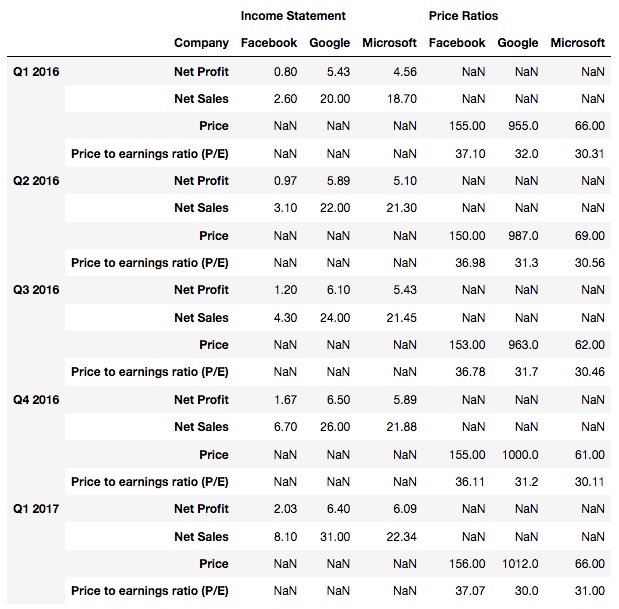
再试下设置 level=2:
df2.stack(level=2)
输出, 发现是第三行表头被 stack 了: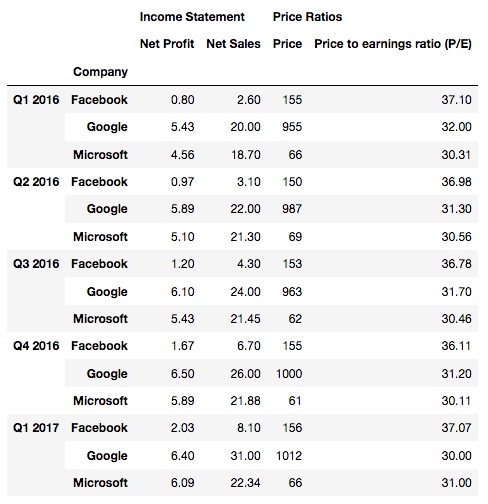
综上, 可以总结, stack 的作用就是可以将横向的表头(列名)转成纵向的索引列展示, 对于多行表头而言, 具体要转换哪一行取决于 level 参数, 如果不指定, 则默认转换最下面一行表头.
以上, 就是关于 stack 和 unstack 的基本操作了, enjoy!~~~