首先, 读入一个 csv 文件:
import pandas as pd
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/5_handling_missing_data_fillna_dropna_interpolate/weather_data.csv')
df输出: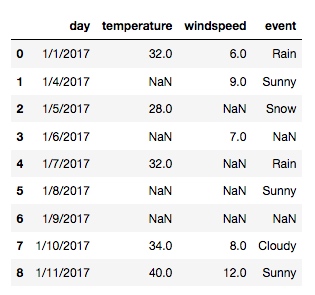
查看一下 day 列的数据类型:
type(df.day[0])
输出:
str
所以目前 day 列里数据类型是字符串.
把 day 列里的数据转成时间戳, 加上第二个参数 parse_dates=['day'] 即可:
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/5_handling_missing_data_fillna_dropna_interpolate/weather_data.csv', parse_dates=['day'])
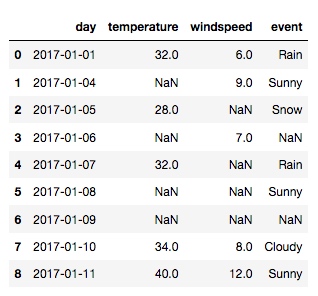
再查看一下 day 列的数据类型:
type(df.day[0])
输出:
pandas._libs.tslibs.timestamps.Timestamp
把 day 列设置为索引列:
df.set_index('day', inplace=True)
输出: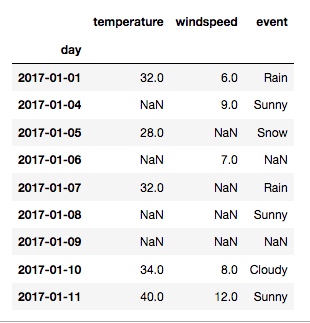
上面的输出有很多空值 NaN, 我们要把它改成数字0:
new_df = df.fillna(0)
new_df
输出: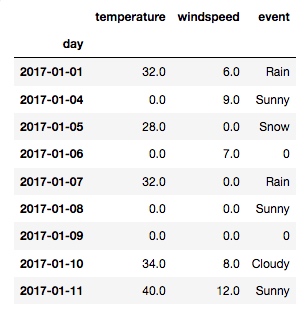
可以看到所有的 NaN 都变成 0 了. 但其实, 并不是所有的列都适合用 0 来填充, 比如 event 列里的 0 就没有实际意义. Pandas 提供了自定义每个列空值填充的方法:
new_df = df.fillna({
'temperature': 0,
'windspeed': 0,
'event': 'no event'
})
new_df
输出: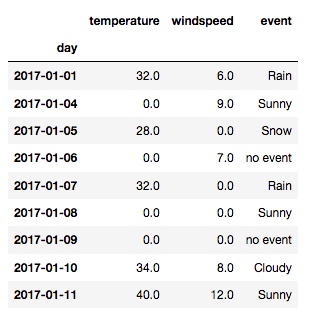
下面再介绍几个在实际应用中更有意义的空值填充方式:
fillna()函数
- 参考上一行的值填充:
new_df = df.fillna(method='ffill')
- 参考下一行的值填充:
new_df = df.fillna(method='bfill')
- 横向从右向左填充:
new_df = df.fillna(method='bfill', axis='columns')
- 横向从左向右填充:
new_df = df.fillna(method='ffill', axis='columns')
- 在使用上述几个填充的方法时, 还可以再加一个参数限定具体要填充几个格, 比如设置 limit=1, 就意味着只会向下填充一格, 后面的空格不管
new_df = df.fillna(method='ffill', limit=1)
输出如下, 可以看到 NaN 的部分就是未被填充的: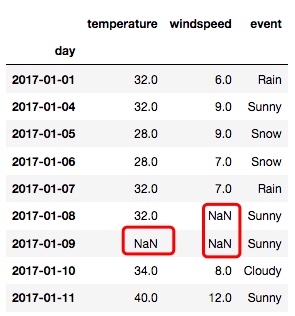
interpolate()函数
new_df = df.interpolate()
从输出中, 可以看出, 这个方法取的是空值前后的中间值:
显然, 取中间值的方式, 比简单粗暴地用前面的值填充更为合理, 但是其实还有优化的空间, 就以 temperature 列为例, 原本 1月4日的值是空的, 如果我们取中间值, 就得到了30.0度, 但是从实际意义出发, 我们会认为1月4日的温度应该与1月5日的温度更加接近, 而不是1月1日. 所以, 我们可以这样做:
new_df = df.interpolate(method='time')
输出: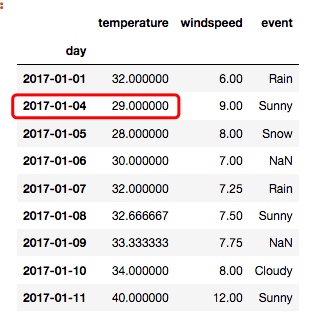
dropna() 函数
通过这个函数, 可以舍弃掉所有有空值的行:
new_df = df.dropna()
输出: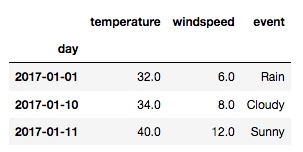
我们看到所有有空值的行全部被删除了, 但是这貌似也不是很合适, 我们只想舍弃所有列都为空值的行, 酱紫就可以了:
new_df = df.dropna(how='all')
输出: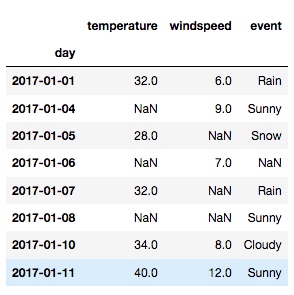
保留至少有一个列有值的行:
new_df = df.dropna(thresh=1)
输出:
保留至少有两个列有值的行:
new_df = df.dropna(thresh=2)
输出: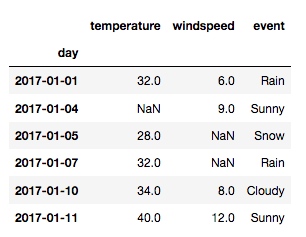
补足所缺的日期
#设置日期范围
dt = pd.date_range('2017-01-01', '2017-01-11')
#重新定义索引
idx = pd.DatetimeIndex(dt)
df = df.reindex(idx)
df
输出: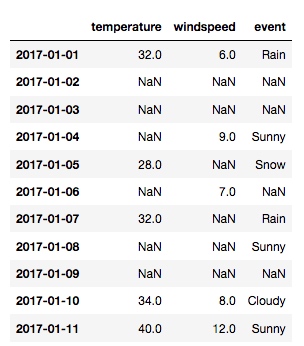
之后, 可以按照上面所讲的方法, 根据实际需要填充空值.
以上, 就是关于空值填充的一些方法, 如有问题请留言, enjoy~~~