Link for origin article: http://community.altiusconsulting.com/blogs/glenchambers/archive/2008/03/10/loading-master-data-without-using-the-psa-in-sap-bi-7-0.aspx
I'll start with a quick refresher of the PSA; the Persistent Staging Area (PSA) is the inbound storage area for data from source systems coming into the system. The requested data is saved in relational database tables in the same format as the DataSource. The data held within the PSA remains unchanged from the source system, meaning that no summarization or transformations haven take place (as is the case with for example InfoCubes).
In BW 3.5 you had the option of loading data directly to InfoProviders completely by-passing the PSA all together, however this all changed with the release of BI 7.0. In version 7.0 it has become mandatory to use the PSA for all data loads, there are in fact many good reasons behind this change. One such example would be if one set of data is destined for two different InfoProviders both with different transformation requirements, then previously you could of loaded the data twice from transactional source system if you skipped the PSA, thereby putting undue stress on that system when dealing with large volumes of data. By using the PSA the same set of data can be read from within the SAP BI system time and time again reducing the impact on underlying source systems.
If you are loading small amounts of master data and want to avoid using the PSA for example when you are testing things in your sandbox there is a way; in data transfer process (DTP) maintenance, you can specify that data is not extracted from the PSA of the DataSource but is requested straight from the data source at DTP runtime. The (rather long!) Do not extract from PSA but allow direct access to data source check box is displayed for the Full extraction mode if the source of the DTP is a DataSource.
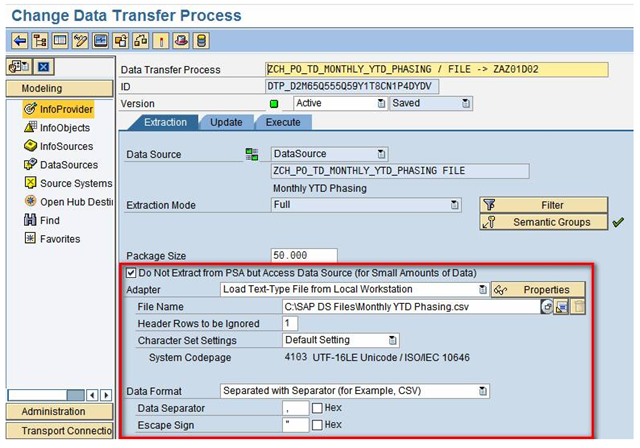
By using this method you do-not have to create an InfoPackage to extract data from the source system.
Some things to bear in mind though:
- Data is extracted synchronously - as in while you wait, hence it advises small data loads only, this does increase pressure on the systems memory
- If errors occur during the data load you have to extract the data again as the PSA is not available as a buffer.
- Deltas are not possible, only full loads.
- In the DTP, the filter only contains fields that the DataSource allows as selection fields. If you use the PSA, you can filter by any available field.
Despite all of the above I find it to be a real time-saver and useful way of working.