训练网络时往往会对全部的神经元参数进行微调,从而让训练结果更加准确。但在这个网络中,训练参数很多,每次微调上百万的数据是很浪费计算资源的。那么Negative Sampling方法可以通过每次调整很小的一部分权重参数,从而代替全部参数微调的庞大计算量。
词典D中的词在语料C中出现的次数有高有低,对于那些高频词,我们希望它被选为负样本的概率比较大,对于那些低频词,我们希望它被选中的概率比较小,这是我们对于负采样过程的一个大致要求,本质上可以认为是一个带权采样的问题。
一、基于Negative Sampling的CBOW模型
输入:基于CBOW的语料训练样本,词向量的维度大小Mcount,CBOW的上下文大小2c,步长η, 负采样的个数neg
输出:词汇表每个词对应的模型参数θ,所有的词向量xw
1. 随机初始化所有的模型参数θ,所有的词向量w
2. 对于每个训练样本(context(w0),w0),负采样出neg个负例中心词wi,i=1,2,...neg
3. 进行梯度上升迭代过程,对于训练集中的每一个样本(context(w0),w0,w1,...wneg)做如下处理:

d) 如果梯度收敛,则结束梯度迭代,否则回到步骤3继续迭代。
二、基于Negative Sampling的Skip-Gram模型
输入:基于Skip-Gram的语料训练样本,词向量的维度大小Mcount,Skip-Gram的上下文大小2c,步长η, , 负采样的个数neg。
输出:词汇表每个词对应的模型参数θ,所有的词向量xw
1. 随机初始化所有的模型参数θ,所有的词向量w
2. 对于每个训练样本(context(w0),w0),负采样出neg个负例中心词wi,i=1,2,...neg
3. 进行梯度上升迭代过程,对于训练集中的每一个样本(context(w0),w0,w1,...wneg)做如下处理:
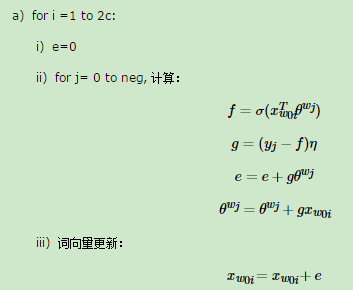
b)如果梯度收敛,则结束梯度迭代,算法结束,否则回到步骤a继续迭代。
参考内容:
https://www.cnblogs.com/pinard/p/7249903.html