前言
前面的文章主要讲了文件字符输入流FileWriter、文件字符输出流FileReader、文件字节输出流FileOutputStream、文件字节输入流FileInputStream,这些都是常见的流类。当然除了这些流类之外,Java还提供了很多的流类给用户使用,本文就看一下别的流。
管道流
管道流主要用于连接两个线程的通信。管道流也分为字节流(PipedInputStream、PipedOutputStream)和字符流(PipedReader、PipedWriter)。比如一个PipedInputStream必须和一个PipedOutputStream对象进行连接而产生一个通信管道,PipedOutputStream向管道中写入数据,PipedInputStream从管道中读取数据。管道流的工作如下图所示:
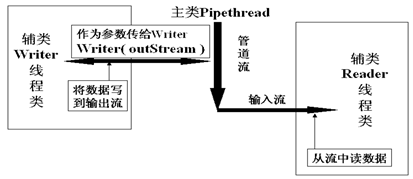
下面看一下管道流的用法。既然管道流的作用是用于线程间的通信,那么势必有发送线程和接收线程,两个线程通过管道流交互数据。首先写一个发送数据的线程:

public class Sender implements Runnable
{
private PipedOutputStream out = new PipedOutputStream();
public PipedOutputStream getOutputStream()
{
return out;
}
public void run()
{
String str = "Receiver, 你好!";
try
{
out.write(str.getBytes()); // 向管道流中写入数据(发送)
out.close();
}
catch (IOException e)
{
e.printStackTrace();
}
}
}
用流写数据的时候注意关注一下,该流是否支持直接写String,不可以的话要用String的getBytes()方法获取字符串的字节。既然有一个发送数据的线程了,接下来来一个接收数据的线程:
public class Receiver implements Runnable
{
private PipedInputStream in = new PipedInputStream();
public PipedInputStream getInputStream()
{
return in;
}
public void run()
{
String s = null;
byte b0[] = new byte[1024];
try
{
int length = in.read(b0);
if (-1 != length)
{
s = new String(b0, 0 , length);
System.out.println("收到了以下信息:" + s);
}
in.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
两个线程都有了,写一个main线程,利用管道输出流的connect方法连接管道输出流和管道输入流:
public static void main(String[] args)
{
try
{
Sender sender = new Sender();
Receiver receiver = new Receiver();
Thread senderThread = new Thread(sender);
Thread receiverThread = new Thread(receiver);
PipedOutputStream out = sender.getOutputStream(); // 写入
PipedInputStream in = receiver.getInputStream(); // 读出
out.connect(in);// 将输出发送到输入
senderThread.start();
receiverThread.start();
}
catch (IOException e)
{
e.printStackTrace();
}
}
输出结果应该很明显了,大家都知道,接收线程接收到了来自发送线程通过管道流输出流发送的数据:
收到了以下信息:Receiver, 你好!
注意一下,PipedInputStream运用的是一个1024字节固定大小的循环缓冲区,写入PipedOutputStream的数据实际上保存到了对应的PipedInputStream的内部缓冲区。PipedInputStream执行读操作时,读取的数据实际上来自这个内部缓冲区。如果对应的PipedInputStream输入缓冲区已满,任何企图写入PipedOutputStream的线程都将被阻塞。而且这个写操作线程将一直阻塞,直至出现读取PipedInputStream的操作从缓冲区删除数据。
这意味着,向PipedOutputStream写入数据的线程不应该是负责从对应PipedInputStream读取数据的唯一线程(所以这里开了两个线程分别用于读写)。假定t线程试图一次对PipedOutputStream的write()方法的调用中向对应的PipedOutputStream写入2000字节的数据,在t线程阻塞之前,它最多能够写入1024字节的数据(PipedInputStream内部缓冲区的大小)。然而,一旦t被阻塞,读取PipedInputStream的操作就再也不能出现了,因为t是唯一读取PipedInputStream的线程,这样,t线程已经完全被阻塞。
对象流
序列化,在这篇文章中已经讲得比较清楚了,这一部分主要是再次简单过一下对象流的知识而已。
Java中提供了ObjectInputStream、ObjectOutputStream这两个类用于对象序列化操作,这两个类是用于存储和读取对象的输入输出流类,只要把对象中的所有成员变量都存储起来,就等于保存了这个对象,之后从保存的对象之中再将对象读取进来就可以继续使用此对象。ObjectInputStream、ObjectOutputStream可以帮助开发者完成保存和读取对象成员变量取值的过程,但要求读写或存储的对象必须实现了Serializable接口。
看一下例子,先来一个实现了Serializable接口的实体类Person:
public class Person implements Serializable
{
/**
* 序列化
*/
private static final long serialVersionUID = 7827863437931135333L;
private transient String name;
private int age;
private final static String sex = "man";
public Person(String name, int age)
{
this.name = name;
this.age = age;
}
public String toString()
{
return "姓名:" + this.name + ", 年龄:" + this.age + ", 性别:" + sex;
}
}
调用ObjectOutputStream和ObjectInputStream写一个序列化和反序列化的方法,我现在D盘下没有"serializable.txt":
public static void main(String[] args) throws Exception
{
File file = new File("D:/serializable.txt");
serializable(file);
deserializable(file);
}
// 序列化对象方法
public static void serializable(File file) throws Exception
{
OutputStream outputFile = new FileOutputStream(file);
ObjectOutputStream oos = new ObjectOutputStream(outputFile);
oos.writeObject(new Person("张三", 25));
oos.close();
}
// 反序列化对象方法
public static void deserializable(File file) throws Exception
{
InputStream inputFile = new FileInputStream(file);
ObjectInputStream ois = new ObjectInputStream(inputFile);
Person p = (Person)ois.readObject();
System.out.println(p);
}
现在运行一下,D盘下多了一个"serializable.txt",文件里面的内容是:
看到乱码,因为序列化之后本身就是按照一定的二进制格式组织的文件,这些二进制格式不能被文本文件所识别,所以乱码也是正常的。
当然,控制台上也是有输出的:
姓名:null, 年龄:25, 性别:man
这证明了被transient修饰的成员变量不会被序列化。