目录
1.1 软件安全概况
- 安全漏洞在软件开发周期的各个环节(包括设计、编码、发布等)中都可能被引入,而只有软件设计与开发人员充分认识到安全漏洞的危害,掌握安全漏洞机理,以及如何避免漏洞的安全编程经验,并在软件厂商的软件开发生命周期中切实执行安全设计开发的流程,才有可能尽量减少发布软件中的安全漏洞数量,降低它们对网络与现实世界所带来的影响与危害。
1.1.1 软件安全威胁
- 软件安全漏洞:可以被攻击者利用并导致危害的安全缺陷被称为软件安全漏洞。
- 安全漏洞包括软件安全漏洞,硬件、个人与组织管理中存在的、能够被攻击者利用来破坏安全策略的弱点,软件安全漏洞是目前最常见,也是影响范围最大的安全漏洞类型。
- 安全漏洞定义(美国国家标准技术研究院NIST):在系统安全流程、设计、实现或内部控制中所存在的缺陷或弱点,能够被攻击者所利用并导致安全侵害或对系统安全策略的违反。包括三个基本要素:系统的脆弱性或缺陷、攻击者对缺陷的可访问性,以及攻击者对缺陷的可利用性。
1.1.2 软件安全困境
软件安全“困境三要素”:
- 复杂性:软件规模会更快膨胀,变得更加复杂,也就意味着软件的bug会越来越多。源代码行数是目前衡量软件规模的一个重要度量指标,已经在软件工程中普遍用来进行项目开发规模的估算
- 可扩展性:现代软件为了支持更加优化的软件架构,支持更好的客户使用感受,提出一些扩展和交互渠道
- 连通性:互联网的普及使得全球更多的软件系统都联通在一起,接入互联网的计算机数量增加,一些控制关键基础设施的重要信息系统也与互联网建立起连通性
1.1.3 软件安全漏洞类型
软件安全漏洞类型从技术上分为:
- 内存安全违规类:在软件开发过程中在处理RAM内存访问时所引入的安全缺陷。缓冲区溢出漏洞是一种最基础的内存安全问题
- 输入验证类:指软件程序在对用户输入进行数据验证存在的错误,没有保证输入数据的正确性、合法性和安全性,从而导致可能被恶意攻击与利用
- 竞争条件类:系统或进程中一类比较特殊的错误,通常在设计多进程或多线程处理的程序中出现,是指处理进程的输出或者结果无法预测,并依赖于其他进程事件发生的次序或时间时,所导致的错误
- 权限混淆与提升类:计算机程序由于自身编程疏忽或被第三方欺骗,从而滥用其权限,或赋予第三方不该给予的权限。具体形式:Web应用程序中的跨站请求伪造、Clickjacking、FTP反弹攻击、权限提升、“越狱”等
1.2 缓冲区溢出基础概念
1.2.1 缓冲区溢出的基本概念与发展过程
- 缓冲区溢出基本概念:在计算机程序向特定缓冲区内填充数据时,超出了缓冲区本身的容量,导致外溢数据覆盖了相邻内存空间的合法数据,从而改变执行流程破坏系统运行完整性。常见于C/C++的memcpy(),strcpy()等内存与字符串复制函数的引用位置
1.2.2 缓冲区溢出攻击背景知识
-
编译器与调试器的使用:高级编程语言编写的源码需要通过编译器和连接器才能生成可直接在操作系统平台上运行的可执行程序代码。调试器是程序开发人员在运行时刻调试与分析程序行为的基本工具。常使用的C/C++编程语言,最著名的编译与连接器是GCC。类UNIX平台上进行程序的调试经常使用GDB调试器。Windows平台,常用Visual Studio、VS.net等集成开发环境
-
汇编语言基础知识:汇编语言,尤其是IA32架构下的汇编语言,是理解软件安全漏洞机理,掌握软件渗透攻击代码技术的底层基础。
-
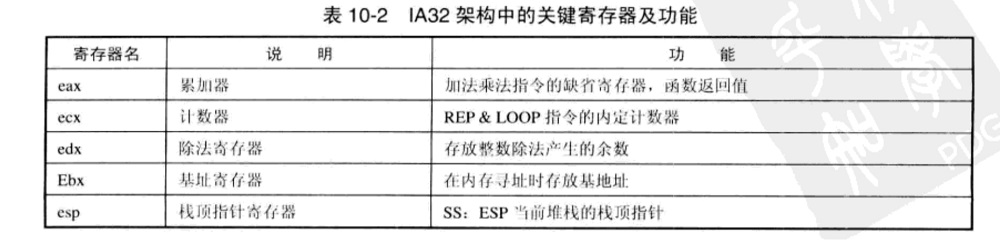
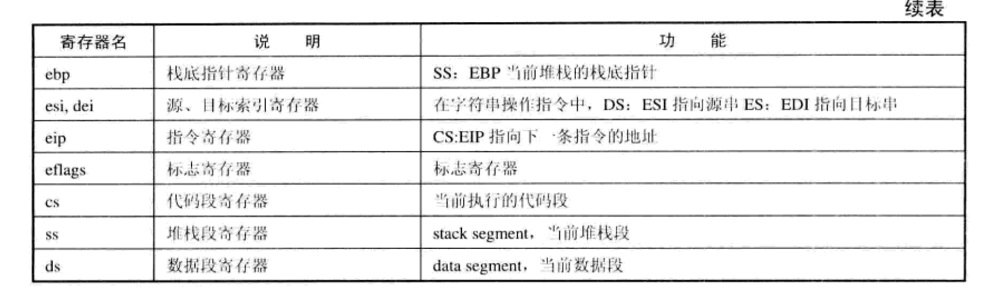
从应用的角度将寄存器分为:
- 通用寄存器:用于普通的算术运算,保存数据、地址、偏移量、计数值等
- 段寄存器:在IA32架构中是16位的,一般用作段基址寄存器
- 控制寄存器:用来控制处理器的执行流程,其中最关键的是eip,也称为“指令指针”,它保存了下一条即将执行的机器指令的地址
- 其他寄存器:“扩展标志”eflags寄存器,由不同的标志位组成,用于保存指令执行后的状态和控制指令执行流程的标志信息
-
IA32架构中的关键寄存器及功能
-
进程内存管理
- Linux操作系统中的进程内存空间布局和管理机制:程序在执行时,系统在内存中会为程序创建一个虚拟的内存地址空间,在32位机上即4GB的空间大小,用于映射物理内存,并保存程序的指令和数据。内存空间3GB以下为用户态空间,3GB-4GB为内核态空间。操作系统将可执行程序加载到新创建的内存空间中,程序一般包含.text(包含程序指令)、.bss(包含未经初始化的数据)和.data(包含静态初始化的数据)三种类型的段。则主要包含未经初始化的数据,两者都被映射至可写的内存空间中。加载完成后,系统开始为程序初始化“栈”和“堆”。“栈”是一种后进先出的数据结构,其地址空间从高地址向低地址增长,程序运行的环境变量env、运行参数argv、运行参数数量argc都被放置在“栈”底,然后是主函数及调用“栈”中各个函数的临时保存信息“堆”则是一种先进先出的数据结构,用于保存程序动态分配的数据和变量,其地址空间从低地址往高地址增长,与“栈”正好相反。程序执行时,就会按照程序逻辑执行.text中的指令,并在“堆”和“栈”中保存和读取数据,然而程序并不能正确地区分指令和数据,所以当我们修改内存空间中影响程序执行逻辑的敏感位置,并将恶意数据作为指令提交给处理器时,它仍会执行。
- Windows操作系统中的进程内存空间布局和管理机制:内核态地址空间为2GB-4GB,用于映射Windows内核代码和一些核心态DLL,并用于存储一些内核态对象,0GB-2GB为用户态地址空间。高地址段映射大量程序共用系统DLL
-
函数调用过程:栈结构与函数调用过程的底层细节是理解栈溢出攻击的重要基础,因为栈溢出攻击就是针对函数调用过程中返回地址在栈中的存储位置,进行缓冲区溢出,从而改写返回地址,达到让处理器指令寄存器跳转至攻击者指定位置执行恶意代码的目的。
程序进行函数调用的过程有如下三个步骤:
- 调用:调用者将函数调用参数、函数调用下一条指令的返回地址压栈,并跳转至被调用函数入口地址
- 序言:被调用函数开始执行首先会进入序言阶段,将对调用函数的栈基址进行压栈保存,并创建自身函数的栈结构,具体包括将ebp寄存器赋值为当前栈基址,为本地函数局部变量分配栈地址空间,更新esp寄存器为当前栈顶指针等
- 返回:被调用函数执行完功能将指令控制权返回给调用者前会进行返回阶段操作,通常执行level 和 ret指令,即恢复调用者的栈顶与栈底指针,并将之前压栈的返回地址装载至指令寄存器eip中,继续执行调用者在函数调用后的下一条指令。
1.2.3 缓冲区溢出攻击原理
- 缓冲区溢出漏洞根据溢出区在进程内存空间中的位置不同,分为
- 栈溢出:存储在栈上的一些缓冲区变量由于存在缺乏边界保护问题,能够被溢出并修改栈上的敏感信息(通常是返回地址),从而导致程序流程的改变
- 堆溢出:存储在堆上的缓冲区变量缺乏边界保护所遭受溢出攻击的安全问题
- 内核溢出:存在于一些内核模块或程序中,由于进程内存空间内核态中存储的缓冲区变量被溢出造成的
- 栈溢出安全漏洞的例子
#include <stdio.h>
void return_input(void){
char array[30];
gets(array);
printf("%s
", array);
}
int main (void){
return_input();
return 0;
}
- 构建成功的栈溢出攻击
#include <stdio.h>
#include <string.h>
char shellcode[]=
// setreuid(0,0);
"x31xc0" // xor %eax,%eax
"x31xdb" // xor %ebx,%ebx
"x31xc9" // xor %ecx,%ecx
"xb0x46" // mov $0x46,%al
"xcdx80" // int $0x80
// execve /bin/sh
"x31xc0" // xor %eax,%eax
"x50" // push %eax
"x68x2fx2fx73x68" // push $0x68732f2f
"x68x2fx62x69x6e" // push $0x6e69622f
"x89xe3" // mov %esp,%ebx
"x8dx54x24x08" // lea 0x8(%esp,1),%edx
"x50" // push %eax
"x53" // push %ebx
"x8dx0cx24" // lea (%esp,1),%ecx
"xb0x0b" // mov $0xb,%al
"xcdx80" // int $0x80
// exit();
"x31xc0" // xor %eax,%eax
"xb0x01" // mov $0x1,%al
"xcdx80"; // int $0x80
char large_string[128];
int main(int argc, char **argv){
char buffer[96];
int i;
long *long_ptr = (long *) large_string;
for (i = 0; i < 32; i++)
*(long_ptr + i) = (int) buffer;
for (i = 0; i < (int) strlen(shellcode); i++)
large_string[i] = shellcode[i];
strcpy(buffer, large_string);
return 0;
}
- 缓冲区溢出攻击的三个挑战:
- 如何找出缓冲溢出区要覆盖和修改的敏感位置?
- 将敏感位置的值修改为什么?
- 执行什么代码达到攻击目的?
1.3 Linux平台上的栈溢出与Shellcode
1.3.1 Linux平台栈溢出攻击技术
- NRS模式:主要适用于被溢出的缓冲区变量比较大,足以容纳Shellcode的情况,其攻击数据是从低地址到高地址的的构造方式是一堆Nop指令(即空操作指令)之后填充Shellcode,再加上一些期望覆盖RET返回地址的跳转地址,从而构成了NRS攻击数据缓冲区
- RNS模式:一般用于被溢出的变量比较小,不足于容纳Shellcode的情况。攻击数据从低地址到高地址的构造方式是首先填充一些期望覆盖RET返回地址的跳转地址,然后是一堆Nop指令,最后再是Shellcode。
- RS模式:能够精确地定位出Shellcode在目标漏洞程序进程空间中的起始地址,因此也就无需引入Nop空指令构建着陆区。这种模式是将Shellcode放置在目标漏洞程序执行时的环境变量中,由于环境变量位于Linux进程空间的栈底位置,其位置是固定的,可以通过公式
ret=0xc0000000-sizeof(void*)-sizeof(FILENAME)-sizeof(Shellcode)计算。
1.3.2 Linux平台的Shellcode实现技术
- Linux系统中本地shellcode的产生过程
- 先用高级编程语言,C,来编写shellcode程序
- 编译并反汇编调试这个shellcode程序
- 从汇编语言代码级别分析程序执行流程
- 提取汇编代码所对应的opcode二进制指令,创建shellcode指令数组
1.4 Windows平台上的栈溢出与Shellcode
1.4.1 Windows平台栈溢出攻击技术
-
成功攻击应用程序中栈溢出漏洞密切相关的主要有以下三点:
- 对程序运行过程中废弃栈的处理方式差异
- 进程内存空间的布局差异
- 系统功能调用实现方式差异
1.4.2 Windows平台Shellcode实现技术
- Windows平台Shellcode实现技术
- shellcode必须可以找到所需要的Windows32 API函数,并生成函数调用表
- 为了能够使用API函数,shellcode必须找到目标程序已加载的函数地址
- shellcode需考虑消除空字节,以免在字符串操作函数中被截断
- shellcode需确保自己可以正常退出,并使原来的目标程序进程继续运行或终止
- 在目标系统环境存在异常处理和安全防护机制时,shellcode需进一步考虑如何应对这些机制
- Windows远程Shellcode
- 创建一个服务器端socket,并在指定的端口上监听
- 通过accept()接受客户端的网络连接
- 创建子程序,运行“cmd.exe”,启动命令行
- 创建两个管道,命令管道将服务器端socket接收(recv)到的客户端通过网络输入的执行命令,连接至cmd.exe的标准输入;然后输出管道将cmd.exe的标准输出连接至服务器端socket的发送(send),通过网络将运行结果反馈给客户端
1.5 堆溢出攻击
堆溢出是缓冲区溢出中第二种类型的攻击方式,由于堆中的内存分配与管理机制较栈更复杂,不同操作系统平台的实现机制具有显著的差异,同时通过堆中的缓冲区溢出控制目标程序执行流程需要更精妙的构造。
- 函数指针改写:被溢出的缓冲区临近全局函数指针存储地址,且在其低地址方向上。在符合这种变量布局的条件下,当缓冲区填充数据时,如果没有边界控制和判断的话,缓冲区溢出就会自然的覆盖函数指针所在的内存区,从而改写函数指针的指向地址,攻击者只要能够将该函数指针指向恶意构造的Shellcode入口地址,在程序使用函数指针调用原先期望的函数时,就会转而执行Shellcode
- C++类对象虚函数表改写:对于使用了虚函数机制的C++类,如果它的类成员变量中存在可被溢出的缓冲区,那么就可以进行堆溢出攻击,通过覆盖类对象的虚函数指针,使其指向一个特殊构造的虚函数表,从而转向执行攻击者恶意注入的指令。
- Linux下堆管理glibc库free()函数本身漏洞:Linux操作系统的堆管理是通过glibc库来实现的,使用被称为Bin的双向循环链表来存储内存空闲块的信息,并使用两个宏来完成对Bin链表的插入和删除操作。glibc库的free()函数在处理内存块回收时,需要将已被释放的空闲块和与之相邻的块合并,再将新的空闲块插回链表中。
1.6 缓冲区溢出攻击的防御技术
- 尝试杜绝溢出的防御技术
- 允许溢出但不让程序改变执行流程的防御技术
- 无法让攻击代码执行的防御技术