DML(增删改)
insert
![]()
![]()
update

delete
![]()
说明:update和delete都要写清楚where
truncate(清空表)

区别:

select (查是最重要的)
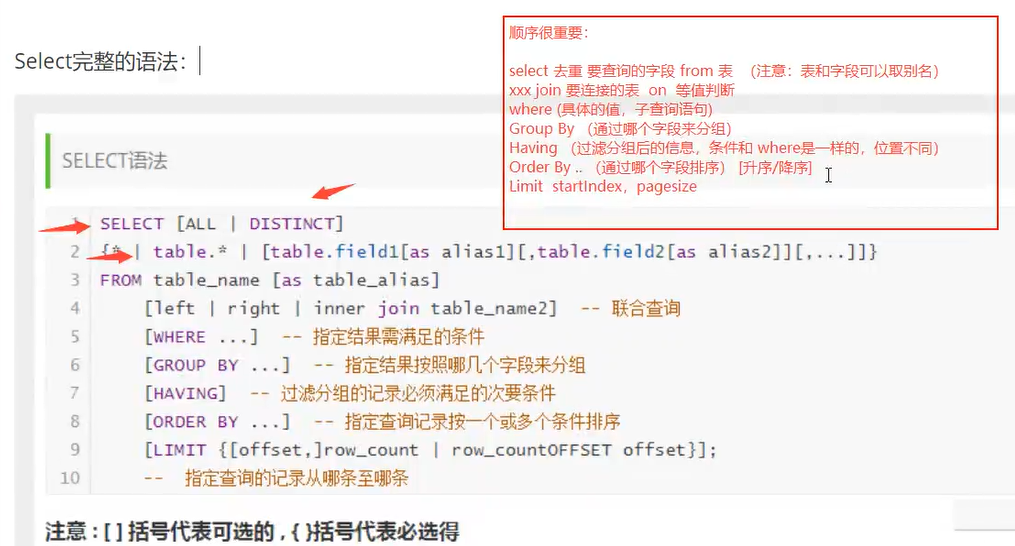
简单查询:
![]()
![]()
去重:
![]()
WHERE:配合NOT AND OR

模糊查询:(本质是 比较运算符)


Like %和_分别是:任意个、一个

![]()
![]()
In (后面括号内必须是全称、并且不能用%和_)
![]()
联表查询Join
![]()
联表查询的关键在于两个表的 "交叉点" ,交叉点在两个表中都有,所以要分清楚:

(是先join再select么?)

JOIN ON连接查询
WHERE等值查询
ON和WHERE:查询效果是一样的,但原理&效率分析,还不清楚

父子关系 (pid)

分组 GROUP BY 和 过滤 HAVING一般组合使用:
(用GROUP BY就不用WHERE,而用HAVING来说明 次要条件)
![]()
排序 ORDER BY
![]() ( ASC+DESC )
( ASC+DESC )
分页 LIMIT
LIMIT 3 //表示总共只选择3个
LIMIT 0,10 //startIndex, pageSize //起始号码,每页个数
ps:1个参数表示总数,两个参数表示分页
往往配合OFFSET来使用:
limit 1 offset 2 //表示第3个
子查询
![]()
两种方法:
方式一:先连接,再用select...where筛选(总共只有一个select)

方式二:先按条件找到关键词,再根据关键词去进一步select(有2或多个select)

再举一个例子:

推荐使用连接查询(JOIN)
连接查询不需要创建+销毁临时表,因此速度比子查询快。
MySQL函数
![]()
![]()
获取用户、获取版本:![]()
COUNT() 计数:
![]()
SUM() 求和
AVG()
MIN() MAX()

ROUND() 四舍五入
EXISTS
EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False

MD5加密
原理:Hash函数、不可逆运算
![]()
![]()
![]()
索引
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。


时间从O(n)到O(1),一次性就查到了

MySQL索引背后的数据结构及算法原理:http://blog.codinglabs.org/articles/theory-of-mysql-index.html
Mysql备份

备份方式:
1.直接拷贝物理文件:

2.Navicat等可视化界面里:右击,备份导出
3.使用命令行mysqldump命令:
![]()
例:![]()
JDBC示例
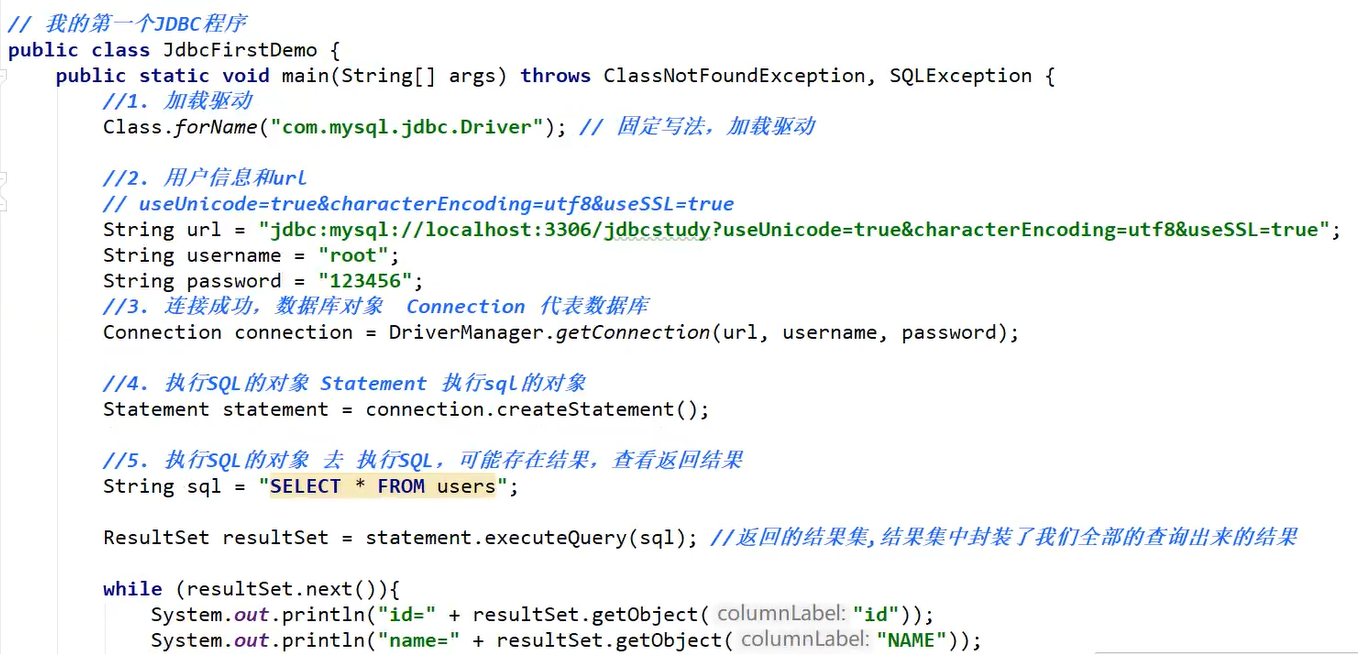

executeUpdate & executeSelect
SQL注入
例子:![]()
IDEA连接数据库(了解)
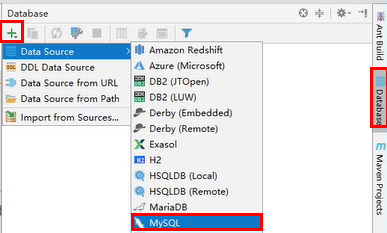
然后填写数据库信息(数据库名、用户、密码等)基本上和Navicat一样流程;
然后打开设置,![]()
之后勾选需要展示的数据库即可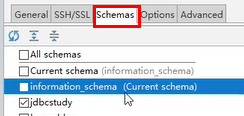
事务
try{
setAutoCommit(false); //关闭自动提交,
然后进行需要的操作(需要保持原子性的几行操作)
commit();//然后再提交
}
catch exception{
rollback(); //失败回滚
}
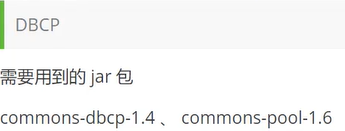
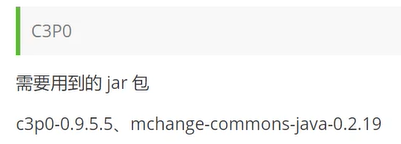
连接池

池化技术:准备一些预先的资源,过来就连接准备好的,但用完要释放

开源数据源实现(拿来即用):DBCP C3P0 Druid
![]()
Druid
(后面再仔细学吧~)
https://www.bilibili.com/video/BV1NJ411J79W?p=45
https://www.bilibili.com/video/BV1J4411877m?p=100