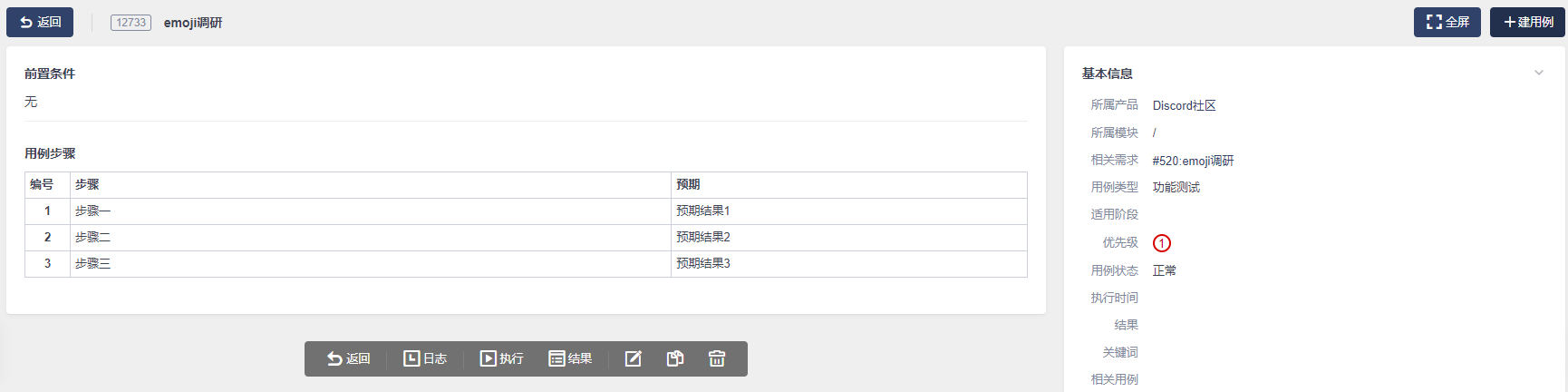
前言
废话不多说,因为工作需要,写这个工具就是为了方便编写以及上传测试用例
由于用例需要上传禅道,还需要按照禅道上的Excel模板来写,但是之前用脑图写习惯了,再加上强逼症,用禅道下载的Excel模板写非常难受,于是就百度找教程并借鉴部分代码。
实现原理:首先制定一套xmind模板规则,然后解析xmind用例数据,然后处理数据,写入Excel模板中
1、定制ximd模板规则
所属模块-相关需求-用例标题-前置条件-操作步骤-预期结果
没有前置条件时可以忽略
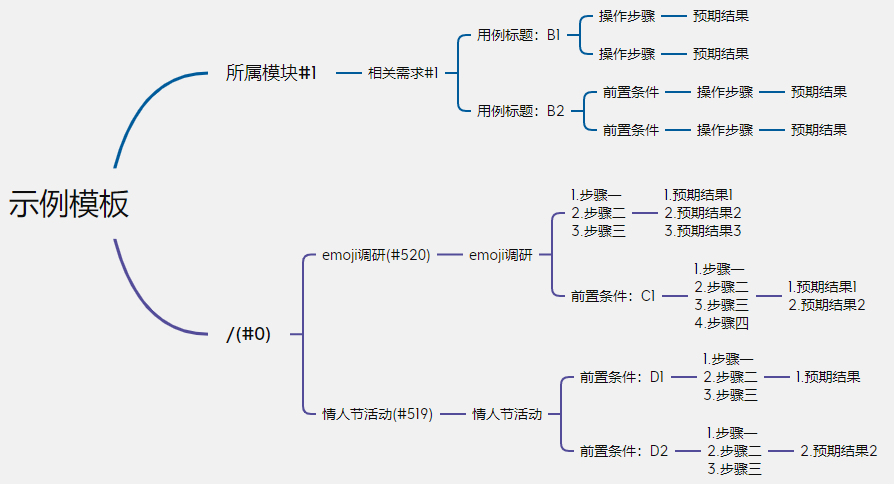
2、xmind数据解析(吐槽:俄罗斯套娃一样)
写好了xmind模板(demo)
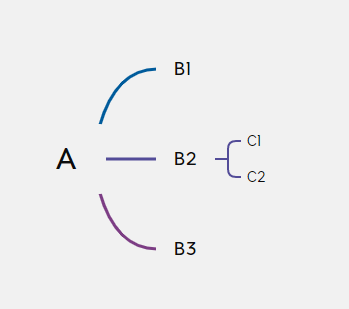
首先要提取Xmind文件分支内容
[
{
'title': '画布1',
'topic': {
'title': 'A',
'topics': [
{
'title': 'B1'
},
{
'title': 'B2',
'topics': [
{
'title': 'C1'
},
{
'title': 'C2'
}
]
},
{
'title': 'B3'
}
]
},
'structure': 'org.xmind.ui.map.unbalanced'
}
]
内容装在一个list里,字典最外层title为“画布1”,
topic装有我们需要的内容(可以看出其他位置叫topics),
这是xmind文件中没有的,经验证这是个固定值,可以忽略。
然后通过取list,A是字典中value值,key为title,其子节点装在topics的分支中。
处理后是这样,最外层是dict:
{
'title': 'A',
'topics': [
{
'title': 'B1'
},
{
'title': 'B2',
'topics': [
{
'title': 'C1'
},
{
'title': 'C2'
}
]
},
{
'title': 'B3'
}
]
}
需要一层层取子节点才可以得到我们想要的AB2C1、AB2C2,
节点值永远在title里,而子节点却在dict、list里的dict里,
而且子节点里有的只有一个title,有的有一个title加一个topics,
不难发现,有topics的是还有其子节点的
处理数据的逻辑大概是下面这样的:
如果 输入字典:
当字典只有有title时:
操作1
当字典有title和topics时:
操作2
如果 输入list:
遍历list里的字典:
对每个字典进行操作3
如果 输入的既不是字典也不是list:
输出值
3、写入Excel
处理后的data数据:
('所属模块#1', '相关需求#1', '用例标题:B1', '无', '操作步骤', '预期结果', '', 1, '功能测试')
('所属模块#1', '相关需求#1', '用例标题:B1', '无', '操作步骤', '预期结果', '', 1, '功能测试')
('所属模块#1', '相关需求#1', '用例标题:B2', '前置条件', '操作步骤', '预期结果', '', 1, '功能测试')
('所属模块#1', '相关需求#1', '用例标题:B2', '前置条件', '操作步骤', '预期结果', '', 1, '功能测试')
写入模板文件:
from openpyxl import load_workbook
def save_excel(self,template, data, new_file):
'''
把数据写入模板用例中
:param template: Excel用例模板文件
:param data: xmind转化后的data数据
:param new_file: 保存至新的Excel表
:return:
'''
wb = load_workbook(template)
sheet = wb.active
for i in data:
print(i)
self.color_handle(str(i))
sheet.append(i)
wb.save(new_file)
print("运行结束!")
4、pyqt5可视化界面
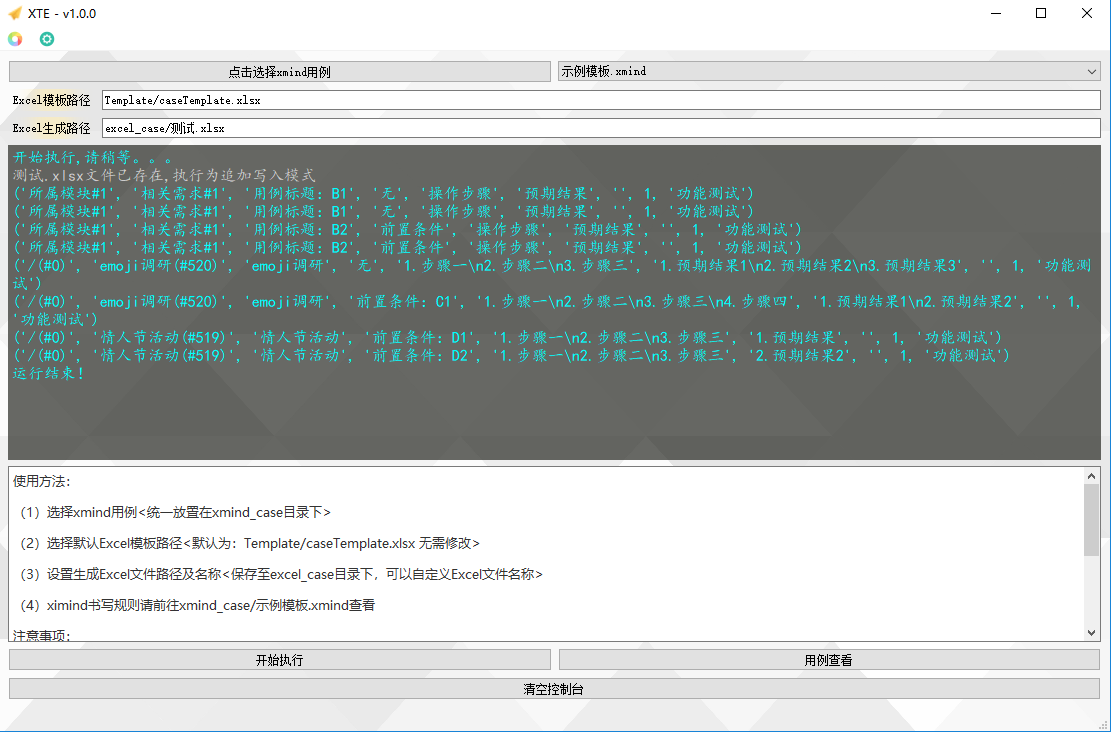
5、写入data后的Excel用例文件
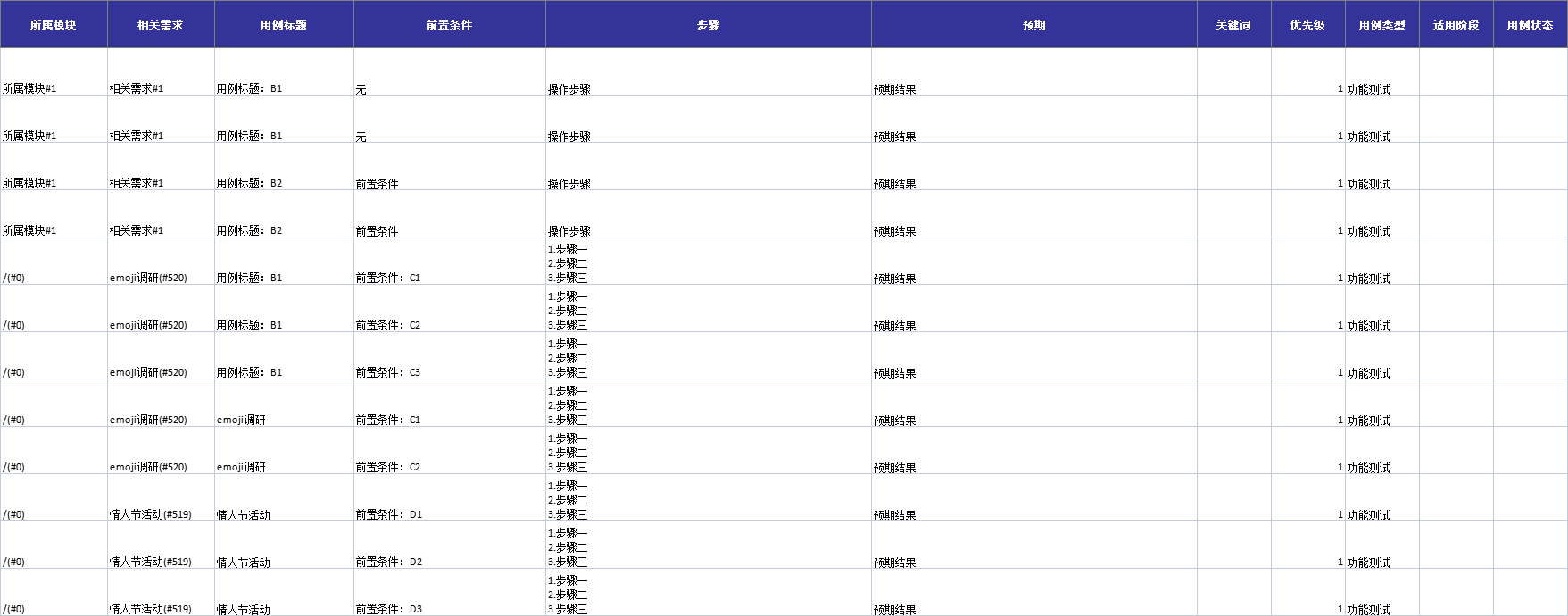
最后上传Excel用例至禅道即可