最近做爬虫发现http协议真是太重要了 ,所以写一篇博客记录一下。
做后端的时候只是知道get,post区别,没有对http有详尽的了解,最近看了才发现这玩意跟递归一样,没有了解到时候都觉得很简单,了解之后才发现复杂的一匹。。。。。
- 首先我们从浏览器输入一个地址开始,浏览器会把这个url地址放入请求队列
- 然后会解析url地址中的ip地址,这个过程也叫DNS解析,可以理解为把这个域名拿去数据库进行查询获取域名对应的ip地址,注意这里有个流程叫DNS缓存,就想数据库缓存一样,每次我们查询的时候都会先看一下自己主机里面有没有关于这个域名的缓存,这也是有时候我们使用盗版软件时候,修改host文件,就是把软件指向的验证域名改成我们本机地址
- 获取到ip后,我们就要检查我们主机到ip之间的连接是否开启,如果开启之间连接,如果否,就开启tcp三次握手的连接,注意,这里还有一个判断,就是如果是https协议,那么在tcp的基础之上还要加上TLS握手协议
- 确认连接以后,到到ip层了,ip层会在收到tcp层发送数据的请求后,生成一个ip头部,这个头部包含ip地址信息
- ip层之后到MAC层,mac层会生成报头和校验序列,用于校验发送包的正确性
- MAC层之后就是PHY层会将MAC层的电信号转化为为网络传输协议所需的格式,通过网线转发后,最终到达服务器
服务返回的流程也是一样,把电信号转化回http请求,贴一张大致的流程图:
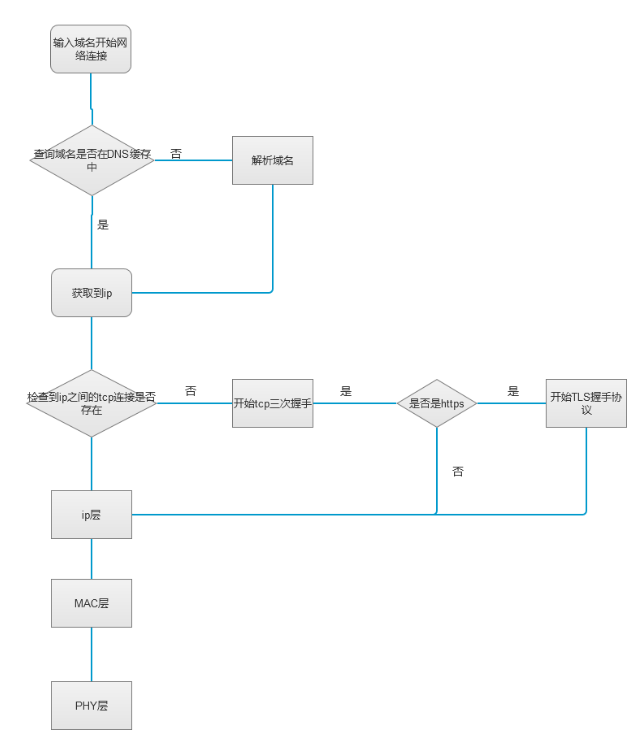
从服务器返回接受信号转为http协议,再到浏览器,这里面还有很多流程,如果你打开f12,看一下网站的任何一次访问,都会发现很多资源并不是一次加载好的,例如图片,js文件之类的资源,都是在主页面之后放入请求队列,再次请求,
eg:
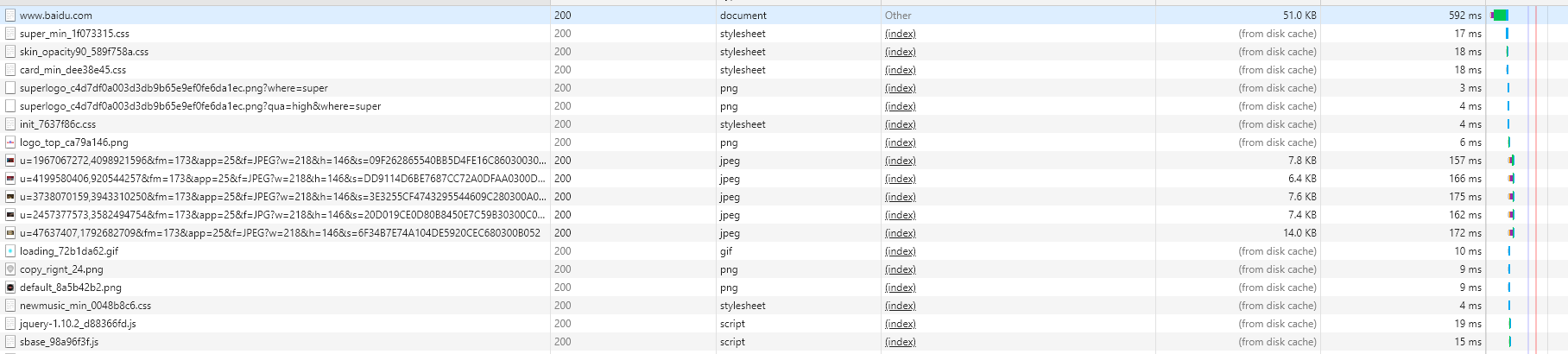
也就是说在获取到返回页面之后,浏览器会解析html,对页面的资源进行优先级排序,添加新的请求到请求队列,当所有的关键资源全部接收完成的时候,开始渲染页面,一个完整的页面渲染就是这样的

我把那个等待专门标注了,因为那个涉及浏览器内核如何工作,资源如何加载,这是一个复杂的流程,因为是异步加载,涉及到资源优先级,以及dom树的绘制以及渲染,都在浏览器进行,这一个方面我了解还不够深,这里面的部分等我了解了再写