数字类型int与float
定义:
# 1、定义:
# 1.1 整型int的定义
age=10 # 本质age = int(10)
# 1.2 浮点型float的定义
salary=3000.3 # 本质salary=float(3000.3)
# 注意:名字+括号的意思就是调用某个功能,比如
# print(...)调用打印功能
# int(...)调用创建整型数据的功能
# float(...)调用创建浮点型数据的功能
类型转换
# 纯数字的字符串转成int
res=int('100111')
print(res,type(res))
# 十进制转成其他进制:
# 10进制 -> 二进制
# 11 - > 1011
# 1011-> 8+2+1
print(bin(11)) # 0b1011=》0b指的是二进制
# 10进制 -> 八进制
print(oct(11)) # 0o13=》0o指的是八进制
# 10进制 -> 十六进制
print(hex(11)) # 0xb
print(hex(123)) # 0xb=》0x指的是十六进制
# 二进制转成其他进制:
# 二进制->10进制
print(int('0b1011',2)) # 11
# 二进制->8进制
print(int('0o13',8)) # 11
# 二进制->16进制
print(int('0xb',16)) # 11
使用
# int与float没有需要掌握的内置方法
# 他们的使用就是数学运算+比较运算
字符串
定义
msg = 'hello' # msg = str('hello')
print(type(msg))
类型转换
# str可以把任意类型转化为字符串
res = str({'a':1})
print(res, type(res))
使用(优先掌握):
1.按索引取值(正向取+反向取) :只能取
msg='hello world'
# 正向取
print(msg[0])
print(msg[5])
# 反向取
print(msg[-1])
# 只能取
msg[0]='H' # 报错
2.切片:索引的拓展应用,从一个大字符串中拷贝出一个子字符串
msg='hello world'
# 顾头不顾尾
msg='hello world'
res=msg[0:5]
print(res) # =》 "hello"
# 步长:默认步长为1
msg='hello world'
res = msg[0:5:2] # 0,2,4
print(res) # =》 "hlo"
# 反向步长(了解)
msg='hello world'
res=msg[5:0:-1]
print(res) # =》 " olle"
msg='hello world'
res=msg[:] # =》 res=msg[0:11]
print(res) # =》 "hello world"
msg='hello world'
res=msg[::-1] # =》 把字符串倒过来
print(res) # =》 "dlrow olleh"
3.长度len
msg='hello world'
print(len(msg)) # =》 "11"
4.成员运算in和not in
# 判断一个子字符串是否存在于一个大字符串中
print("alex" in "alex is sb") # =》 True
print("alex" not in "alex is sb") # =》 False
print(not "alex" in "alex is sb") # 不推荐使用
5.移除字符串左右两侧的符号strip
# 了解:strip只去两边字符,不去中间
msg=' egon '
res=msg.strip()
print(msg) # 不会改变原值 => " egon "
print(res) # 是产生了新值 => "egon"
# 默认去掉的空格
msg='****egon****'
print(msg.strip('*')) # => "egon"
msg='****e*****gon****'
print(msg.strip('*')) # => "e*****gon"
msg='**/*=-**egon**-=()**'
print(msg.strip('*/-=()')) # => "egon"
# 应用
inp_user=input('your name>>: ').strip() # => "your name>>:"
if inp_user == 'egon' and inp_pwd == '123':
print('登录成功')
else:
print('账号密码错误')
6.切分split:把一个字符串按照某种分隔符进行切分,得到一个列表
# 默认分隔符是空格
info='egon 18 male'
res=info.split()
print(res) # => ['egon', '18', 'male']
# 指定分隔符
info='egon:18:male'
res=info.split(':')
print(res) # => ['egon', '18', 'male']
# 指定分隔次数(了解)
info='egon:18:male'
res=info.split(':',1)
print(res) # => ['egon', '18:male']
7.循环
info='egon:18:male'
for i in info.split(':'):
print(i) # => egon
18
male
需要掌握
1.strip,lstrip,rstrip
msg='***egon****'
print(msg.strip('*')) # => 'egon'
print(msg.lstrip('*')) # => 'egon****'
print(msg.rstrip('*')) # => '***egon'
2.lower,upper
msg='AbbbCCCC'
print(msg.lower()) # => 'abbbcccc'
print(msg.upper()) # => 'ABBBCCCC'
3.startswith,endswith
print("alex is sb".startswith("alex")) # => True
print("alex is sb".endswith('sb')) # => True
5.split,rsplit:将字符串切成列表
info="egon:18:male"
print(info.split(':',1)) # => ["egon","18:male"]
print(info.rsplit(':',1)) # => ["egon:18","male"]
6.join: 把列表拼接成字符串
# l=['egon', '18', 'male']
# res=l[0]+":"+l[1]+":"+l[2]
# res=":".join(l) # 按照某个分隔符号,把元素全为字符串的列表拼接成一个大字符串
# print(res)
# l=[1,"2",'aaa']
# ":".join(l)
4.2.7、replace
# msg="you can you up no can no bb"
# print(msg.replace("you","YOU",))
# print(msg.replace("you","YOU",1))
4.2.8、isdigit
# 判断字符串是否由纯数字组成
# print('123'.isdigit())
# print('12.3'.isdigit())
# age=input('请输入你的年龄:').strip()
# if age.isdigit():
# age=int(age) # int("abbab")
# if age > 18:
# print('猜大了')
# elif age < 18:
# print('猜小了')
# else:
# print('才最了')
# else:
# print('必须输入数字,傻子')
4.3了解
4.3.1、find,rfind,index,rindex,count
msg='hello egon hahaha'
# 找到返回起始索引
# print(msg.find('e')) # 返回要查找的字符串在大字符串中的起始索引
# print(msg.find('egon'))
# print(msg.index('e'))
# print(msg.index('egon'))
# 找不到
# print(msg.find('xxx')) # 返回-1,代表找不到
# print(msg.index('xxx')) # 抛出异常
# msg='hello egon hahaha egon、 egon'
# print(msg.count('egon'))
4.3.2、center,ljust,rjust,zfill
# print('egon'.center(50,'*'))
# print('egon'.ljust(50,'*'))
# print('egon'.rjust(50,'*'))
# print('egon'.zfill(10))
4.3.3、expandtabs
# msg='hello world'
# print(msg.expandtabs(2)) # 设置制表符代表的空格数为2
4.3.4、captalize,swapcase,title
# print("hello world egon".capitalize())
# print("Hello WorLd EGon".swapcase())
# print("hello world egon".title())
4.3.5、is数字系列
4.3.6、is其他
# print('abc'.islower())
# print('ABC'.isupper())
# print('Hello World'.istitle())
# print('123123aadsf'.isalnum()) # 字符串由字母或数字组成结果为True
# print('ad'.isalpha()) # 字符串由由字母组成结果为True
# print(' '.isspace()) # 字符串由空格组成结果为True
# print('print'.isidentifier())
# print('age_of_egon'.isidentifier())
# print('1age_of_egon'.isidentifier())
num1=b'4' #bytes
num2=u'4' #unicode,python3中无需加u就是unicode
num3='四' #中文数字
num4='Ⅳ' #罗马数字
# isdigit只能识别:num1、num2
# print(num1.isdigit()) # True
# print(num2.isdigit()) # True
# print(num3.isdigit()) # False
# print(num4.isdigit()) # False
# isnumberic可以识别:num2、num3、num4
# print(num2.isnumeric()) # True
# print(num3.isnumeric()) # True
# print(num4.isnumeric()) # True
# isdecimal只能识别:num2
print(num2.isdecimal()) # True
print(num3.isdecimal()) # False
print(num4.isdecimal()) # False
字符串
定义
l = [1, 1.2, 'a'] # l=list([1, 1.2, 'a'])
print(type(l))
类型转换
# 只要是能够被for循环循环遍历的类型(可迭代对象)都可以当作参数传给list()转成列表
# 可迭代对象包括:字符串、列表、字典、元组、集合
list() # 就相当于for循环的循环遍历
使用优先掌握的操作:
1.按索引取值(正向取+反向取),可以存也可以改
# 正向取
l = [111, 'hello', 'world']
print(l[0]) # => '111'
# 反向取
l = [111, 'hello', 'world']
print(l[-1]) # => 'world'
# 可以存也可以改
l = [111, 'hello', 'world']
l[0]=222
print(l) # => [222, 'hello', 'world']
# 无论是取还是改,索引不存在则报错
2.切片(顾头不顾尾,步长)
print(l[0:]) # [111, 'hello', 'world']
print(l[:]) # [111, 'hello', 'world']
print(l[::-1]) # ['world', 'hello', 111]
new_l=l[:] # 切片等同于拷贝行为,而且相当于浅拷贝
3.长度
print(len(l)
4.成员运算in和not in
print(222 in l)
print(222 not in l)
5.向列表添加值
# 5.1追加
l.append(333) # 在列表末尾添加
print(l)
# 5.2插入值
l.insert(1, 'python')
print(l) # [111, 'python', 'hello', 'world']
# 5.3往原列表中添加新列表的值(extend)
new_l=[1,2,3]
'''
for i in new_l:
l.append(i)
print(l)
'''
# extend实现了上述代码,extend()中存放可迭代对象
l.extend(new_l)
print(l)
6.删除
# 方式一:del(万能删除法)
# del不支持赋值操作,赋值会抛出异常
del l[1]
# 方式二:l.pop(根据索引删除,会返回值)
# 默认删除列表最后一个元素
l.pop() # 不指定索引默认删最后一个
print(l)
res = l.pop(1) # 会返回被删除值,此处返回hello
print(res)
# 方式三:l.remove()根据元素删除,返回None
res = l.remove(111)
print(res)
7.循环
for i in l:
print(i)
需要掌握的操作
l = [111, 'aaa', 'bbb', 'aaa', 'aaa']
# 1.count()统计元素在列表中的出现次数
print(l.count('aaa'))
# 2.index()查找元素在列表所在的索引值,元素不存在则报错
print(l.index(111))
# 3.clear()清空列表
l.clear()
print(l)
# 4.reverse():不是排序,就是将列表倒过来
l.reverse()
print(l) # ['aaa', 'aaa', 'bbb', 'aaa', 111]
# 5.sort()默认从小到大排序(升序)
# 注意:列表内必须是同种类型才可以排序
l=[11,0,55,33,44,22]
l.sort()
l.sort(reverse=True) # 从大到小排序(降序)
print(l)
# 了解:字符串可以比大小,按照ASCI码表的先后顺序区别字符的大小
print('abc'>'aba') True
# 了解:列表也可以比大小,原理同字符串一样,但是对应位置的元素必须是同种类型
l1=[1,'abc','zzz']
l2=[1,'abc','aaa']
print(l1>l2) True
补充:模拟队列与堆栈的存取值操作
# 队列:先进先出的特点
l = []
l2 = []
for i in range(1, 5):
l.append(i)
l2.append(i)
print(l)
for j in l:
l2.pop(0)
print(l2)
# 堆栈:先近后出的特点
l = []
l2 = []
for i in range(1, 5):
l.append(i)
l2.append(i)
print(l)
for i in l:
l2.pop()
print(l2)
元组
作用
- 按照索引位置存放多个值,只用于读与用于改(就相当于是一个不可变的列表)
定义
t=(1,1.3,'aa') # t=tuple((1,1.3,'aa'))
print(t,type(t))
# 当元组中只含有一个元素时,必须加逗号,否则表示为包含
print((10),type((10))) # 10 int
print((10),type((10,))) # 10 tuple
# 元组是不可变的,指的是当元组内的元素内存地址不变那么元组也不会发生改变
t=(1,[1,2])
t[0]=111 # 报错
t[1]=222 # 报错
t[1][0]=333 # (1, [3, 2])
# 注意:此处改的是元组内的列表(可变类型)内的元素的内存地址,列表本身的内存地址并不会发生改变
类型转换
print(tuple('hello'))
print(tuple('hello'))
print(tuple('hello'))
使用
# 1.按索引取值(正向取+反向取),只能存
l = (111, 'hello', 'world')
# 正向取
print(l[0])
# 反向取
print(l[-1])
# 2.切片(顾头不顾尾,步长)
print(l[0:]) # (111, 'hello', 'world')
print(l[:]) # (111, 'hello', 'world')
print(l[::-1]) # ('world', 'hello', 111)
new_l=l[:] # 切片等同于拷贝行为,而且相当于浅拷贝
print(new_l) # (111, 'hello', 'world')
# 3.长度
print(len(l))
# 4.成员运算in和not in
print(222 in l)
print(222 not in l)
# 5.count()统计元素在列表中的出现次数
print(l.count('aaa'))
# 6.index()查找元素在列表所在的索引值,元素不存在则报错
print(l.index(111))
字典
定义
# {}内用逗号分隔开多个key:value,其中value可以是任意类型,但是key必须是不可变类型且唯一
dic = {'k1': 11, (1, 2, 3): 222} # dic=dict({'k1': 11, (1, 2, 3): 222})
类型转换
info = [
['name', 'egon'],
('age', 18),
['gender', 'male']
]
# 造字典的四种方式
'''
# 方式一:
dic = {}
for k,v in info:
dic[k]=v
print(dic)
# 方式二:
print(dict(info))
# 方式三:
keys = ['name','age','gender']
print({}.fromkeys(keys,None))
# 方式四:
print(dict(name='egon',age=18,gender='male'))
'''
使用:优先掌握的操作
d={'k1':111}
# 1.按key存取值:可存可取
# key存在则修改值,key不存在则创建新值
d['k1']=222
d['k2']=333
print(d)
# 2.长度len
print(len(d))
# 3.成员运算in和not in(即判断字符串是否在字典中)
print('k1' in d)
print(111 in d)
# 4.删除
d={'k1':111,'k2':222,'k3':333}
'''
# 方式一:del通用删除
del d['k1']
print(d)
# 方式二:pop删除:根据key删除元素,返回删除key对应的那个value值
res=d.pop('k2')
print(d)
print(res)
# 方式三:popitem删除:随机删除,返回元组(删除的key,删除的value)
res=d.popitem()
print(d)
print(res)
'''
# 5.键keys(),值values(),键值对items()
'''
# 在python2中相当于得到的是一筐鸡蛋
>>> d={'k1':111,'k2':222}
>>> d.keys()
['k2', 'k1']
>>> d.values()
[222, 111]
>>> d.items()
[('k2', 222), ('k1', 111)]
>>>
# 在python3中相当于得到一只老母鸡(大大减少的空间的使用)
>>> d={'k1':111,'k2':222}
>>> d.keys()
dict_keys(['k1', 'k2'])
>>> d.values()
dict_values([111, 222])
>>> d.items()
dict_items([('k1', 111), ('k2', 222)])
>>>
>>> list(d.keys())
['k1', 'k2']
>>> list(d.values())
[111, 222]
>>> list(d.items())
[('k1', 111), ('k2', 222)]
>>>
'''
# 6.循环
d={'k1':111,'k2':222}
for k in d:
print(k) # 默认循环取值结果为字典的key
for k in d.keys():
print(k)
for v in d.values():
print(k)
for item in d.items():
print(k) # 结果是一个个元组(key,value)
需要掌握的操作
d={'k1':111}
# 1.clear()
print(d.clear()) # 清空字典
# 2.update()
'''
# 更新字典,即将新字典中的key:value添加到原字典中,
# 当原字典中存在key时则修改原字典的value值,
# 当原字典中不存在key时,则在原字典中创建key:value
'''
d.update({'k1':222})
print(d) # {'k1':222}
d.update({'k2':222})
print(d) # {'k1':222,'k2':222}
# 3.get() 根据key取值,容错性好
print(d['k2']) # key不存在则报错
print(d.get('k2')) # key不存在则返回None
# 4.setdefault()
info={}
'''
if 'name' in info:
... # 等同于pass
else:
info['k1'] = 111
print(info)
'''
# setdefault()就类似于做了上面这种效果
# 如果key有则不添加,返回字典中key对应的值
info={'name':'egon'}
print(info.setdefault('name','alex')) # egon
# 如果key没有则添加,返回字典中key对应的值
info={}
print(info.setdefault('name','egon')) # egon
集合
作用:集合、list、tuple、dict一样都可以存放多个值,但是集合主要用于:去重、关系运算
定义:
"""
定义:在{}内用逗号分隔开多个元素,集合具备以下三个特点:
1:每个元素必须是不可变类型
2:集合内没有重复的元素
3:集合内元素无序
"""
s = {1,2,3,4} # 本质 s = set({1,2,3,4})
# 注意1:列表类型是索引对应值,字典是key对应值,均可以取得单个指定的值,而集合类型既没有索引也没有key与值对应,所以无法取得单个的值,而且对于集合来说,主要用于去重与关系元素,根本没有取出单个指定值这种需求。
# 注意2:{}既可以用于定义dict,也可以用于定义集合,但是字典内的元素必须是key:value的格式,现在我们想定义一个空字典和空集合,该如何准确去定义两者?
d = {} # 默认是空字典
s = set() # 这才是定义空集合
类型转换
# 但凡能被for循环的遍历的数据类型(强调:遍历出的每一个值都必须为不可变类型)都可以传给set()转换成集合类型
>>> s = set([1,2,3,4])
>>> s1 = set((1,2,3,4))
>>> s2 = set({'name':'jason',})
>>> s3 = set('egon')
>>> s,s1,s2,s3
{1, 2, 3, 4} {1, 2, 3, 4} {'name'} {'e', 'o', 'g', 'n'}
关系运算
# 我们定义两个集合friends与friends2来分别存放两个人的好友名字,然后以这两个集合为例讲解集合的关系运算
friends1 = ["zero","kevin","jason","egon"]
friends2 = ["Jy","ricky","jason","egon"]
两个集合关系如下图:

1.合集/并集(|):求两个用户所有的好友(重复好友只留一个)
print(friends1 | friends2) # => {'kevin', 'ricky', 'zero', 'jason', 'Jy', 'egon'}
print(friends1.union(friends2))
2.取交集:两者共同的好友
res=friends1 & friends2
print(res) # => {'jason', 'egon'}
print(friends1.intersection(friends2))
3.取差集:取friends1独有的好友
print(friends1 - friends2) # => {'kevin', 'zero'}
print(friends1.difference(friends2)) # => {'ricky', 'Jy'}
4.对称差集: 求两个用户独有的好友们(即去掉共有的好友)
print(friends1 ^ friends2) # => {'kevin', 'zero', 'ricky', 'Jy'}
print(friends1.symmetric_difference(friends2))
5.值是否相等(==)
print(friends1 == friends2) # => False
6.父子集:包含的关系
s1={1,2,3}
s2={1,2,4}
# 不存在包含关系,下面比较均为False
print(s1 > s2)
print(s1 < s2)
s1={1,2,3}
s2={1,2}
print(s1 > s2) # 当s1大于或等于s2时,才能说是s1是s2他爹
print(s1.issuperset(s2))
print(s2.issubset(s1)) # s2 < s2 =>True
s1={1,2,3}
s2={1,2,3}
print(s1 == s2) # s1与s2互为父子
print(s1.issuperset(s2))
print(s2.issuperset(s1))
7.子集
{1,2} < {1,2,3}
True
{1,2} <= {1,2,3}
True
去重
集合去重复有局限性
# 1. 只能针对不可变类型
print(set([1,1,1,1,2]))
# 2. 集合本身是无序的,去重之后无法保留原来的顺序
示例如下:
>>> l=['a','b',1,'a','a']
>>> s=set(l)
>>> s # 将列表转成了集合
{'b', 'a', 1}
>>> l_new=list(s) # 再将集合转回列表
>>> l_new
['b', 'a', 1] # 去除了重复,但是打乱了顺序
# 针对不可变类型,并且保证顺序则需要我们自己写代码实现,例如
l=[
{'name':'lili','age':18,'sex':'male'},
{'name':'jack','age':73,'sex':'male'},
{'name':'tom','age':20,'sex':'female'},
{'name':'lili','age':18,'sex':'male'},
{'name':'lili','age':18,'sex':'male'},
]
new_l=[]
for dic in l:
if dic not in new_l:
new_l.append(dic)
print(new_l)
# 结果:既去除了重复,又保证了顺序,而且是针对不可变类型的去重
[
{'age': 18, 'sex': 'male', 'name': 'lili'},
{'age': 73, 'sex': 'male', 'name': 'jack'},
{'age': 20, 'sex': 'female', 'name': 'tom'}
]
其他操作
# 1.长度
>>> s={'a','b','c'}
>>> len(s)
3
# 2.成员运算
>>> 'c' in s
True
# 3.循环
>>> for item in s:
... print(item)
...
c
a
b
其他内置方法
s={1,2,3}
# 需要掌握的内置方法1:discard
s.discard(4) # 删除元素不存在do nothing
print(s)
s.remove(4) # 删除元素不存在则报错
# 需要掌握的内置方法2:update
s.update({1,3,5})
print(s)
# 需要掌握的内置方法3:pop
res=s.pop()
print(res)
# 需要掌握的内置方法4:add
s.add(4)
print(s)
# 其余方法全为了解
res=s.isdisjoint({3,4,5,6}) # 两个集合完全独立、没有共同部分,返回True
print(res)
# 了解
s.difference_update({3,4,5}) # s=s.difference({3,4,5})
print(s)
可变类型与不可变类型
- 可变数据类型:值发生改变时,内存地址不变,即id不变,证明在改变原值
- 不可变类型:值发生改变时,内存地址也发生改变,即id也变,证明是没有在改变原值,是产生了新的值
数字类型:
>>> x = 10
>>> id(x)
1830448896
>>> x = 20
>>> id(x)
1830448928
# 内存地址改变了,说明整型是不可变数据类型,浮点型也一样
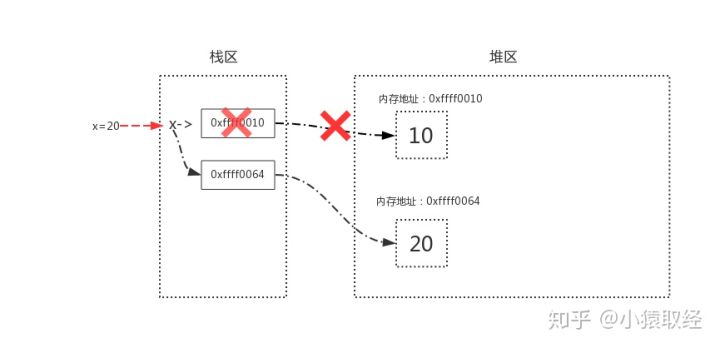
字符串:
>>> x = "Jy"
>>> id(x)
938809263920
>>> x = "Ricky"
>>> id(x)
938809264088
# 内存地址改变了,说明字符串是不可变数据类型
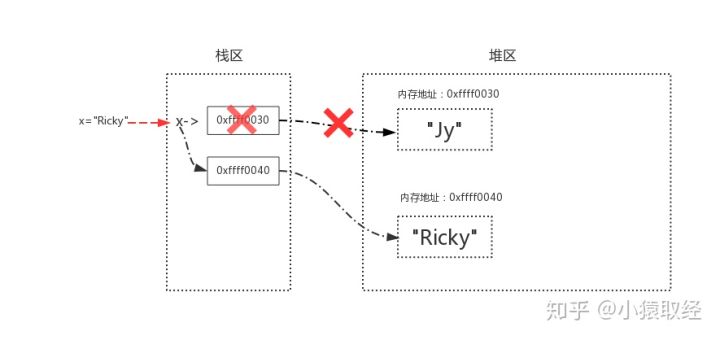
列表
>>> list1 = ['tom','jack','egon']
>>> id(list1)
486316639176
>>> list1[2] = 'kevin'
>>> id(list1)
486316639176
>>> list1.append('lili')
>>> id(list1)
486316639176
# 对列表的值进行操作时,值改变但内存地址不变,所以列表是可变数据类型
元组
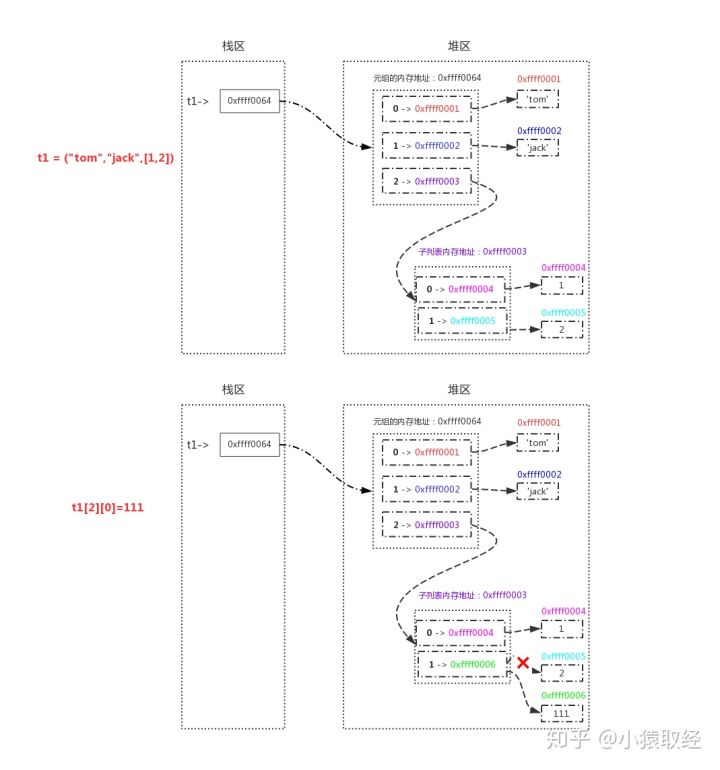
>>> t1 = ("tom","jack",[1,2])
>>> t1[0]='TOM' # 报错:TypeError
>>> t1.append('lili') # 报错:TypeError
# 元组内的元素无法修改,指的是元组内索引指向的内存地址不能被修改
>>> t1 = ("tom","jack",[1,2])
>>> id(t1[0]),id(t1[1]),id(t1[2])
(4327403152, 4327403072, 4327422472)
>>> t1[2][0]=111 # 如果元组中存在可变类型,是可以修改,但是修改后的内存地址不变
>>> t1
('tom', 'jack', [111, 2])
>>> id(t1[0]),id(t1[1]),id(t1[2]) # 查看id仍然不变
(4327403152, 4327403072, 4327422472)
字典
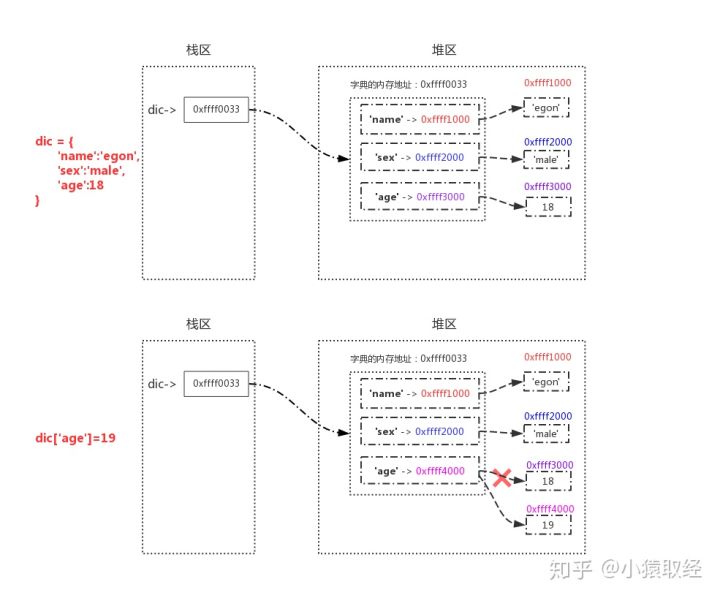
>>> dic = {'name':'egon','sex':'male','age':18}
>>>
>>> id(dic)
4327423112
>>> dic['age']=19
>>> dic
{'age': 19, 'sex': 'male', 'name': 'egon'}
>>> id(dic)
4327423112
# 对字典进行操作时,值改变的情况下,字典的id也是不变,即字典也是可变数据类型
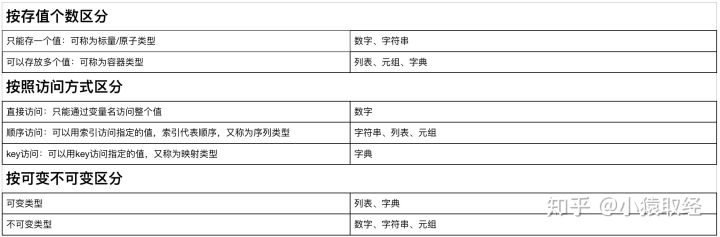
数据类型总结