day6 - day10
1. 函数:实现了一个功能,可以重复调用
2. 无参函数:
def 函数名称():
函数功能实现的代码(函数体)
3. 有参函数:
def 函数名(形参1,形参2...)
4. 定义函数时,占位的参数是形参,调用参数的时候,传递的是实参;
5. 函数参数类型:
1> 位置参数/必传参数:按实参位置的顺序一一对应传值给形参
2> 默认参数:定义函数时,给参数一个默认的值,形参=值,默认参数一定要在非默认参数后面;


1 # 非默认参数要放在默认参数之前 2 # 当有多个默认参数时,想部分默认参数不传参。关键字参数 3 def add_to_sum_v4(end_num, start_num=1, step=1): # start_num=1 step=1都是默认参数 4 sum = 0 5 for i in range(start_num, end_num ,step): 6 sum += i 7 print(sum) 8 9 add_to_sum_v4(12, 4) # 位置一一对应 10 add_to_sum_v4(12, step=2) # 位置参数,关键字参数 实参=值 明确指定哪个值传给哪个参数。 11 add_to_sum_v4(start_num=4,end_num=66) # 关键字参数
3> 不定长参数 *args,传给函数时,是以一个元组传给形参的
1 # 定义函数的时候,用*args,在函数内部,是以一个元组传进去的 2 def add_random(start_num, *args): 3 print(args) 4 sum = start_num 5 for num in args: 6 sum += num 7 print(f"总和为: {sum}") 8 9 add_random(10) 10 add_random(10,66) 11 add_random(10,2,3,4,5,6,7,8)
4> 关键字参数 **kwargs:实参=值的形式明确指定是给哪个形参传值,这样就和位置无关了,在函数内部是一个字典
1 def desc_your_feather(**kwargs): 2 print(kwargs) 3 4 # 传参时:key=value 5 desc_your_feather(name="未知", age=30, sex="boy") 6 7 def both(*args, **kwargs): 8 print("打印单身狗args:{}".format(args)) # 是一个元组 9 print("打印非单身狗及对象信息kwargs:{}".format(kwargs)) # 是一个字典 10 11 both("陈独秀","人生","阿然","珍珍",so="soso", yijiu="leisen")
PS:各种参数联合使用时的顺序: 位置参数 > 默认参数 > 不定长参数 > 关键字参数
6. 函数传参时的拆包
1> 当需要将一组数据传入函数内使用时,可以用 * 拆包,将一组数据拆分成一个个单独的参数,一组参数一般是一个列表或元组;
1 def deal(*args): 2 sum = 1 3 print(args) 4 for item in args: 5 sum *= item 6 left = sum % 20 7 print("对20取余结果为: {}".format(left)) 8 9 nums = input("请输入数字(用逗号隔开每一个数字)") # nums = "10,20,30,40" 10 11 # 方法1 12 new_list = [] 13 for item in nums.split(","): 14 new_list.append(int(item)) 15 print(f"输入多个数字处理成列表:{new_list}") # new_list = [10, 20, 30, 40] 16 # deal(new_list) # 报错TypeError,因为new_list传入后,args = ([1, 2, 3, 4],) 17 18 # 方法2 19 # 传参拆包-拆列表,给函数a,b,c..传参 20 deal(*new_list) # 传参拆包: * 脱掉了列表的[],相当于 deal(10,20,30,40) 21 # 传参拆包-拆元组,给函数a,b,c..传参 22 mytuple = (1,2,3,4,5) # 传参拆包: * 脱掉了元组的括号,相当于 deal(1,2,3,4,5) 23 deal(*mytuple)
2> ** 是将字典拆成键值对,使用*对字典拆包只能获得字典的所有键;
1 # 传参拆包-拆字典,给函数key=value传参 2 def newdict(**kwargs): 3 print(f"传进来的参数:{kwargs}") 4 5 mydict = {"name":"xj", "age":10} 6 # newdict(mydict) # 报错TypeError,因为需要的形式是 name="xj", age=10 7 8 newdict(name='qcx',age=20) 9 newdict(**mydict) # 传参拆包:** 脱掉了字典的{},相当于 newdict(name="qcx", age=20)
7. 函数返回值 return 作用:
输入 -- 函数参数 输出 -- 函数返回值 -- return
1> 函数的输出,返回的类型可以是任意类型;
2> 一旦在执行函数的过程中,遇到了return语句,直接退回函数,函数执行结束;
3> 如果函数当中没有return,那么函数的返回值是None;
4> 在定义函数时,如果希望某些条件没有满足,直接退出函数的话,就用return;
5> 获取函数返回值: 变量名(接收返回值) = 函数调用;
1 def get_money_from_ATM(cardNo, passwd, need_money): 2 if need_money > 1000: 3 print("您的余额不足1000,没有钱返回") 4 has_money = False 5 else: 6 has_money = True 7 return need_money # 函数执行的过程当中,返回的值 8 9 print("我取到钱了吗?{}".format(has_money)) 10 11 def shopping(money): 12 print("我要花 {} 钱去买年货!".format(money)) 13 14 money = get_money_from_ATM("123456","123456",800) # money接收返回值 15 print("我取到了 {} 块钱。准备去买买买了。".format(money)) 16 17 shopping(money) # money来自调用get_money_from_ATM()函数的返回值 18 19 # money = get_money_from_ATM("123456","123456",1200) # 没有return的时候返回的就是None 20 # print("我取到了 {} 块钱。准备去买买买了。".format(money))
1 def get_money_from_ATM(cardNo, passwd, need_money): 2 3 if passwd != "666888": 4 return 5 6 if need_money > 1000: 7 print("您的余额不足1000,没有钱返回") 8 has_money = False 9 else: 10 has_money = True 11 return need_money,cardNo 12 print("我取到钱了吗?{}".format(has_money)) 13 return 666 14 15 16 money = get_money_from_ATM("123456","66688",800) # 返回 None 17 print(money) 18 19 money,card = get_money_from_ATM("123456","666888",800) 20 print("我取到了 {} 块钱。准备去买买买了。".format(money)) 21 print("卡号是:{}".format(card))
8. 变量作业域:
1> 局部变量:函数内部定义的变量;
2> 全局变量:全局可用;
3> 一般不在建议在函数内部修改全局变量,容易导致值变化;
4> 如果真要在函数内部修改全局变量,可以使用关键字gloab
1 b = "hello" 2 3 def helloworld(): 4 a = 100 5 b = 200 6 print(a) 7 print("函数内部的b:",b) 8 9 10 helloworld() 11 # print("在函数外部打印函数局部变量a: ", a) # 报错 name 'a' is not defined,因为它是局部变量,作业域只在函数内部 12 print("全局变量b:",b)
1 b = "hello" 2 3 def helloworld(): 4 global b 5 a = 100 6 print(a) 7 print(b) 8 b = 2000 # 修改全局变量 9 10 11 helloworld() 12 print("全局变量b被修改了:",b)
9. 文件操作
读写文件,不管是从文件读取出来,还是写入到文件当中,都是以字符串的形式!
9.1 文件读取
1> fs = open(文件路径,mode=模式,encoding="utf-8"): 打开文件,读写追加模式;
a> r: 默认只读,文件一定要存在,否则报错;
b> w:只能写入,不能读取,直接覆盖原有所有内容,若文件不存在,会自动创建,但文件所在的目录一定要存在,否则会报错;
c> a:追加(append),内容追加到文件末尾,若文件不存在,会自动创建,但文件所在的目录一定要存在,否则会报错;
d> rb:二进制的只读,其它同r;
e> wb:二进制的写入,基它同w;
f> ab:二进制的追加,其他同a;
g> +:上面的模式后面加+,代表可以写入,可以读出;
2> fs.read() :一次性读取所有内容,得到的是字符串;
3> fs.readline(): 一次只读一行内容,得到的是字符串;
4> fs.readlines(): 按行读取,每行内容作为列表一个成员,得到是一个列表;
1 # 默认以只读模式打开文件 注意:文件的完整路经必须存在,不然就会报错 FileNotFoundError 2 fs = open(r"D:python_lemon37202104_pycharm使用+python基本语法day8_文件操作dict_file.txt",encoding="utf-8") 3 4 # 读取数据 - fs.read() 全部读取 5 data = fs.read() 6 print(data) 7 print("------------------") 8 data = fs.read() # 没有读到内容,因为上面的read()执行后,读取指针已指向文件内容最后,故再读时内容为空 9 print("还能读到内容吗?",data) 10 fs.close()
1 # 默认以只读模式打开文件 注意:文件的完整路经必须存在,不然就会报错 FileNotFoundError 2 fs = open(r"D:python_lemon37202104_pycharm使用+python基本语法day8_文件操作dict_file.txt",encoding="utf-8") 3 4 # # 读取数据 - fs.read() 全部读取 5 # data = fs.read() 6 # print(data) 7 # print("------------------") 8 # data = fs.read() # 没有读到内容,因为上面的read()执行后,读取指针已指向文件内容最后,故再读时内容为空 9 # print("还能读到内容吗?",data) 10 # fs.close() 11 12 # 按行读取 fs.readline() / fs.readlines() 13 data = fs.readline() 14 print(type(data)) 15 16 data = fs.readlines() 17 print(data) 18 fs.close()
9.2 文件写入
文件写入数据时,不会自动换行,需要在数据当中,加入换行符
1> write(mode = w):写入数据,打开文件时是写入模式,mode = w;
a> 如果文件存在,就打开,且会清除之前已写入的内容,从头开始写;
b> 如果文件不存在,重新创建一个;
c> 如果文件完整路径当中的某个目录不存在,会报错;
2> write(mode = a):
a> 如果文件存在,就打开,且不会清除之前已写入的内容,而是直接在文件末尾接着写入内容;
b> 如果文件不存在,重新创建一个;
c> 如果文件完整路径当中的某个目录不存在,会报错;
3> writelines():写入列表当中的每个成员;
4> fs.close():无论读、写文件,都需要关闭文件,释放资源;
# 默认以只读模式打开文件 注意:文件的完整路经必须存在,不然就会报错 FileNotFoundError fs = open(r"D:python文件操作write_file.txt",mode="w",encoding="utf-8") fs.write("66666 ") fs.write("hello world ") fs.write("我能回家吗?? ") datalist = ["小阿卷子 ", "虾米 ", "童子 ","阿研 "] fs.writelines(datalist) fs.close()
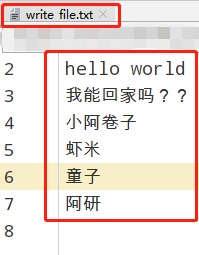
5> with...as:使用with操作文件,会启动文件的上下管理器,不需要关闭文件,会自动关闭文件;
with open(r"D:python文件操作write_file.txt",mode="a",encoding="utf-8") as fs: fs.write("Y. ") fs.write("小饭团 ") fs.write("张一田 雷森 安江 so") with open(r"D:python文件操作write_file.txt",encoding="utf-8") as fs: data = fs.read() print(data)
10. 模块/包
1> python本身安装时,就自带的库,即标准库,默认在Lib目录下;
2> 第三方库:python有非常丰富的第三方库,需要手动安装,默认安装Lib/site-packages目录下,如excel交互openpyxl,http通信requests,ui自动化selenium,发送箱件email等等,而且有官网详情的指导文档
3> 自定义的模块/包:自己编写的,一般在项目目录下,可以导入模块,也可以具体导入到模块的内容(函数,全局变量 ,类);
4> 包(package):python的包就是一个包含一个__init__.py文件的目录(文件夹)
5> 模块(module):是一个python文件,以.py结尾,包含python对象定义和python语句
11. 模块/包导入
1> 导入模块:
a> 相对于project的路径当中,有包,则 from 包名.[包名.包包...] import 模块名 [as 别名];
b> 相对于project的路径当中,没有包,则 import 模块名 [as 别名];
c> 导入之后,要使用模块当中的内容,则语法为:模块名(有别名只能用别名).变量/模块名(有别名只能用别名).函数(参数)
2> 导入模块当中的内容(变量/全局变量/类):
a> 相对于project的路径当中,有包,则 from 包名.[包名.包包...].模块包 import 变量/全局变量/类 [as 别名];
b> 相对于project的路径当中,没有包,则 from 模块名 import 变量/全局变量/类 [as 别名];
c> 导入之后,直接使用;
3> 同级目录下的文件,可以直接导入,但是一般不建议这么做,特别不友好;
12. 找导入文件的顺序和地方(sys模块,sys.path)
1> 执行文件当前所在的目录;
2> 当前工程目录(在pycharm执行时,是pycharm添加进去的);
3> python根目录下的lib目录(python安装时自带的标准库);
4> python根目录下的lib/site-packages(通过pip命令安装的第三方库);
PS:注意,取模块名时,千万不要使用标准库/第三方库的名字
5> pep8规范 -导包顺序:导入文件要放在文件顶部,先后顺序是标准库,第三方库,自定义库,同级别的库名称短的在前;
6> 模块导入的搜索路径: import sys print(sys.path)
import os import sys import requests from python基本语法.day9_import import myfunc from python基本语法.same_level import work print(myfunc.money) myfunc.deal(1,2,3,4) work() # 找包的路径 for item in sys.path: print(item)
7> 导入包时,会执行__init__.py文件:
a> python包的标识,不能删除;
b> 配置模块的初始化操作;
c> 简化模块导入操作,即在此文件中,将包自己需要提供给外部其他模块使用的模块/函数/变量都导入;
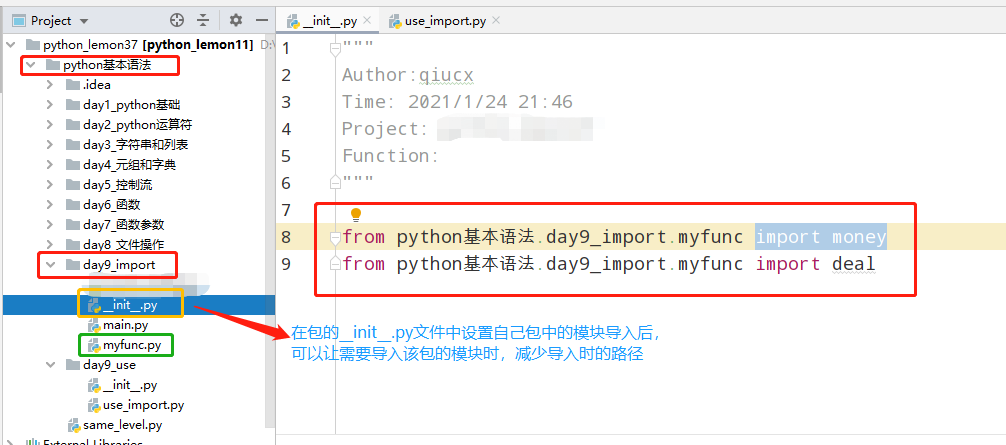
8> __init__.py中导入自己包的模块/函数/变量后,被导入时可以减少导入路径,简化模块导入操作;
a> python基本语法.day9_import的模块myfunc.py脚本内容如下
1 money = 200 2 3 4 def deal(*args): 5 sum = 1 6 print(args) 7 for item in args: 8 sum *= item 9 left = sum % 20 10 print("对20取余结果为: {}".format(left)) 11 12 def myprint(): 13 print("随便打印点什么!")
b> 以下是python基本语法.day9_import包的__init__.py文件
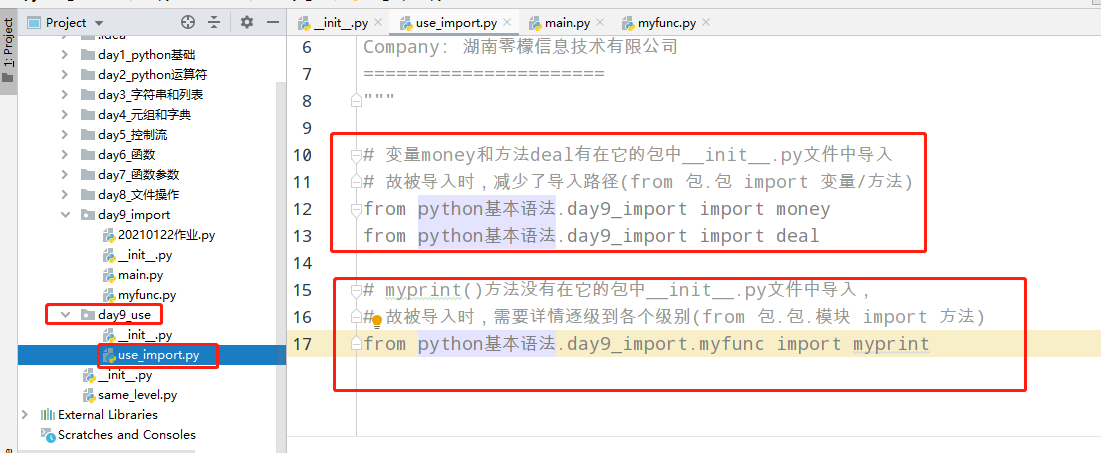
1 from python基本语法.day9_import.myfunc import money 2 from python基本语法.day9_import.myfunc import deal
c> 另一个模块导入上面模块的变量/方法:
1 # 变量money和方法deal有在它的包中__init__.py文件中导入 2 # 故被导入时,减少了导入路径(from 包.包 import 变量/方法) 3 from python基本语法.day9_import import money 4 from python基本语法.day9_import import deal 5 6 # myprint()方法没有在它的包中__init__.py文件中导入, 7 # 故被导入时,需要详情逐级到各个级别(from 包.包.模块 import 方法) 8 from python基本语法.day9_import.myfunc import myprint
13. 测试代码
1 if __name__ == '__main__': 2 # 测试代码 3 # 当我们运行当前文件的时候,是以当前文件作为主入口,就会进入这里。 4 # 好处:当前文件被其它模块导入使用时,此处的代码不会执行。 5 deal(66,66,66,66)
14. os模块
1> 代码中直接使用变量定义工程目录(硬编码),移植性特别差,可能会出现路径找不着(把代码放到其它电脑上),跨平台支持不友好(windows linux路径表达有差异)
import os basedir = r'D:python_lemon37python基本语法' # 硬编码 files = os.listdir(basedir) print(files) # 获取基础目录basedir当前下一级的所有文件或文件夹名称 # 怎么拼接路径 for file in files: print(basedir + "\" + file)
2> 一般代码中使用相对路径,不会使用绝对路径;
a> 动态获取当前文件的绝对路径:os.path.abspath();
b> 动态获取所给目录/文件 所在的目录:os.path.dirname(文件/目录);
c> 动态拼接路径(根据操作系统处理路径拼接符 - win是 linux是/ ):os.path.join(顶级目录,要追加的顶级目录之后的目录/文件) 连接二个部分路径,组成一个完整的路径
d> 获取基础目录basedir当前下一级的所有文件或文件夹名称:os.listdir() ;
3> os模块方法介绍链接: https://www.runoob.com/python/os-file-methods.html
4> os.path模块方法介绍链接: https://www.runoob.com/python/python-os-path.html
1 # 1、动态获取当前文件的绝对路径 2 print(__file__) # 当前执行文件的文件名(带完整路径返回) 3 file_full_path = os.path.abspath(__file__) 4 print(f"当前文件的绝对路径: {file_full_path}") 5 6 # 2、动态获取所给目录/文件 所在的目录 7 file_dir = os.path.dirname(file_full_path) 8 print(file_dir) 9 10 upper_dir = os.path.dirname(file_dir) 11 print(upper_dir) 12 13 # 3、得到作业讲解的目录 14 new_path = os.path.join(upper_dir,"作业讲解") 15 print(new_path) 16 17 new_path = os.path.join(upper_dir,"作业讲解","控制流作业.py") 18 print(new_path) 19 20 new_path = os.path.join(upper_dir,"作业讲解","函数参数","a.py") 21 print(new_path)
15. 异常处理
1> 捕获异常的语法:
try:
代码块;
except [异常类型 as e]:
try里的代码块A发生异常时,会执行这里的代码;
raise 用于抛出异常;
except 后面不写具体的异常类型,默认捕获所有的异常类型;
如果想打印出捕获的异常信息,可以用except 异常类型 as e
print(e)
else:
try里的代码块没有异常时,才会执行这里的代码;
可以没有else;
finally:
try里的代码不管是否异常,这里的代码都会被执行;
可以没有finally;
1 num = input("请输入一个数字:") 2 3 try: 4 res = 100 / int(num) 5 except Exception as e: # try的代码块 6 # 你抓到了异常,你自己额外添加的处理 7 print("输入有误!请输入非0的数字!不要输入0或者其它非数字。") 8 print(e) # 打印出捕获的异常信息 Exception为常规错误的基类 9 raise # 上面处理完之后,把错误又抛出给python解释器,程序就会在这里被终止 10 else: 11 print(res) # try里面的语句没报错,则会执行这个代码块 12 finally: 13 # 不管try里面有没有报错。最后一定会执行的收尾代码。 14 print("我是一定要执行的收尾代码!") 15 16 print("66666666666") #捕获异常,增加日志记录后,不raise,程序就不会被终止,后面的代码而可以正常执行
2> 异常类型
a> BaseException:所有异常规则的基类;
b> BufferError:当与 缓冲区 相关的操作无法执行时将被引发
c> KeyboardInterrupt:用户中断执行;
d> GeneratorExit:生成器(generator)发生异常来通知退出;
e> Exception:常规错误的基类,一般常见如下:
AssertionError:断言语句失败;
AttributeError:对象没有这个属性
ModuleNotFoundError:找不到模块
IndexError:序列中没有此索引(index)
KeyError:映射中没有这个键
NameError:未声明、初始化对象
IndentationError:缩进错误
TabError:Tab 和空格混用
TypeError:对类型无效的操作
ValueError:传入无效的参数
UnicodeDecodeError:Unicode 解码时的错误
UnicodeEncodeError:Unicode 编码时错误
3> 捕获具体异常:
1 num = input("请输入一个数字:") 2 3 try: 4 res = 100 / int(num) 5 except ZeroDivisionError as e: 6 print("输入有误,请不要输入0!") 7 print(e) 8 raise 9 except ValueError as e: 10 print("输入有误,请输入数字!") 11 print(e) 12 except Exception as e: 13 print("未加的错误") 14 print(e) 15 else: 16 print("算出了结果!") 17 finally: 18 print("我是一定要执行的收尾代码!")