【背景】
好几年没搞Hadoop了,最近需要用Flink,打算搞一搞Flink On Yarn。
下面这篇是几年前安装HBase的笔记,也包含了Hadoop的安装。
https://www.cnblogs.com/quchunhui/p/7411389.html
这次打算都选择最新的版本尝试能否安装成功。
【环境】
jdk:jdk-8u77-linux-x64.tar.gz
zookeeper:zookeeper-3.4.6.tar.gz
hadoop:hadoop-2.10.0.tar.gz
flink:flink-1.10.0-bin-scala_2.11.tgz
【系统】
Linux CentOS8(阿里云ECS服务器)
三个节点的Hostname分别为:
rexel-ids001
rexel-ids002
rexel-ids003
【安装JDK】
已经安装好了,这里不再重复记录。
JAVA_HOME=/home/radmin/jdk1.8.0_77
【安装zookeeper】
已经安装好了,这里不再重复记录。
ZK_HOME=/home/radmin/zookeeper-3.5.6
【安装Hadoop】
==解压缩并配置环境变量==
HADOOP_HOME=/home/radmin/hadoop-2.10.1

==修改配置文件==
相关配置文件,所有节点配置文件相同。可以在一个节点配置完之后,用ssh命令复制到其他节点。
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
masters
slaves
hadoop-env.sh
export JAVA_HOME=/home/radmin/jdk1.8.0_77
core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/home/radmin/data/hadoop/tmp</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://ns</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/radmin/data/hadoop/journal</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>rexel-ids001:2181,rexel-ids002:2181,rexel-ids003:2181</value> </property> </configuration>
hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/radmin/data/hadoop/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/radmin/data/hadoop/hdfs/data</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.nameservices</name> <value>ns</value> </property> <property> <name>dfs.ha.namenodes.ns</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.ns.nn1</name> <value>rexel-ids001:9000</value> </property> <property> <name>dfs.namenode.rpc-address.ns.nn2</name> <value>rexel-ids002:9000</value> </property> <property> <name>dfs.namenode.http-address.ns.nn1</name> <value>rexel-ids001:50070</value> </property> <property> <name>dfs.namenode.http-address.ns.nn2</name> <value>rexel-ids002:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://rexel-ids001:8485;rexel-ids002:8485;rexel-ids003:8485/ns</value> </property> <property> <name>dfs.ha.automatic-failover.enabled.ns</name> <value>true</value> </property> <property> <name>dfs.client.failover.proxy.provider.ns</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>~/.ssh/id_rsa</value> </property> </configuration>
mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>54</value> </property> <property> <name>mapreduce.map.memory.mb</name> <value>128</value> </property> </configuration>
yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>ns</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>rexel-ids001</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>rexel-ids002</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>rexel-ids001:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>rexel-ids002:8088</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>rexel-ids001:2181,rexel-ids002:2181,rexel-ids003:2181</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>512</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>128</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>512</value> </property>
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>The maximum number of application master execution attempts.</description>
</property>
</configuration>
其中yarn.resourcemanager.am.max-attempts这项配置是根据Flink官网上提示的修改的。
【小插曲】
后面在尝试提交一个job到集群上的时候提示了Yarn内存设置的太小,修改了以下三个配置,具体请参考后面的笔记。
<property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>1024</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>2048</value> </property>
masters
如果没有,则需要手动创建该文件>
rexel-ids001
rexel-ids002
slaves
rexel-ids001 rexel-ids002 rexel-ids003
==首次启动==
1)在rexel-ids001上
hdfs zkfc -formatZK
2)在3节点分别启动:
hadoop-daemon.sh start journalnode
3)在rexel-ids001上:
hdfs namenode -format
hadoop-daemon.sh start namenode
4)在rexel-ids002上:
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
5)在rexel-ids001和rexel-ids002上:
hadoop-daemon.sh start zkfc
6)在3个节点分别启动:
hadoop-daemon.sh start datanode
7)在rexel-ids001和rexel-ids002上:
yarn-daemon.sh start resourcemanager
8)在3个节点分别启动:
yarn-daemon.sh start nodemanager
9)在dscn1上启动:
mr-jobhistory-daemon.sh start historyserver
==日常启动==
1)在3节点分别启动:
hadoop-daemon.sh start journalnode
2)在1和2上:
hadoop-daemon.sh start namenode
3)在1和2上:
hadoop-daemon.sh start zkfc
4)在3个节点分别启动:
hadoop-daemon.sh start datanode
5)在1和d2上:
yarn-daemon.sh start resourcemanager
6)在3个节点分别启动:
yarn-daemon.sh start nodemanager
7)在1上启动:
mr-jobhistory-daemon.sh start historyserver
【安装Flink】
==下载并配置环境变量==

==配置文件==
可以参考官网提供的example
https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/jobmanager_high_availability.html
相关配置文件:
flink-conf.yaml
masters
slaves
zoo.cfg
flink-conf.xml
################################################################################ # Licensed to the Apache Software Foundation (ASF) under one # or more contributor license agreements. See the NOTICE file # distributed with this work for additional information # regarding copyright ownership. The ASF licenses this file # to you under the Apache License, Version 2.0 (the # "License"); you may not use this file except in compliance # with the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. ################################################################################ #============================================================================== # Common #============================================================================== # The external address of the host on which the JobManager runs and can be # reached by the TaskManagers and any clients which want to connect. This setting # is only used in Standalone mode and may be overwritten on the JobManager side # by specifying the --host <hostname> parameter of the bin/jobmanager.sh executable. # In high availability mode, if you use the bin/start-cluster.sh script and setup # the conf/masters file, this will be taken care of automatically. Yarn/Mesos # automatically configure the host name based on the hostname of the node where the # JobManager runs. jobmanager.rpc.address: rexel-ids001 # The RPC port where the JobManager is reachable. jobmanager.rpc.port: 6123 # The heap size for the JobManager JVM jobmanager.heap.size: 512m # The total process memory size for the TaskManager. # # Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead. taskmanager.memory.process.size: 1024m # To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'. # It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory. # taskmanager.memory.flink.size: 512m # The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline. taskmanager.numberOfTaskSlots: 4 # The parallelism used for programs that did not specify and other parallelism. parallelism.default: 1 # The default file system scheme and authority. # # By default file paths without scheme are interpreted relative to the local # root file system 'file:///'. Use this to override the default and interpret # relative paths relative to a different file system, # for example 'hdfs://mynamenode:12345' # # fs.default-scheme #============================================================================== # High Availability #============================================================================== # The high-availability mode. Possible options are 'NONE' or 'zookeeper'. # high-availability: zookeeper # The path where metadata for master recovery is persisted. While ZooKeeper stores # the small ground truth for checkpoint and leader election, this location stores # the larger objects, like persisted dataflow graphs. # # Must be a durable file system that is accessible from all nodes # (like HDFS, S3, Ceph, nfs, ...) # high-availability.storageDir: hdfs://ns/flink/recovery # The list of ZooKeeper quorum peers that coordinate the high-availability # setup. This must be a list of the form: # "host1:clientPort,host2:clientPort,..." (default clientPort: 2181) # high-availability.zookeeper.quorum: rexel-ids001:2181,rexel-ids002:2181,rexel-ids003:2181 # ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes # It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE) # The default value is "open" and it can be changed to "creator" if ZK security is enabled # # high-availability.zookeeper.client.acl: open high-availability.zookeeper.path.root: /flink #============================================================================== # Fault tolerance and checkpointing #============================================================================== # The backend that will be used to store operator state checkpoints if # checkpointing is enabled. # # Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the # <class-name-of-factory>. # state.backend: filesystem # Directory for checkpoints filesystem, when using any of the default bundled # state backends. # state.checkpoints.dir: hdfs://ns/flink/checkpoints # Default target directory for savepoints, optional. # state.savepoints.dir: hdfs://ns/flink/savepoints # Flag to enable/disable incremental checkpoints for backends that # support incremental checkpoints (like the RocksDB state backend). # # state.backend.incremental: false # The failover strategy, i.e., how the job computation recovers from task failures. # Only restart tasks that may have been affected by the task failure, which typically includes # downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption. jobmanager.execution.failover-strategy: region #============================================================================== # Rest & web frontend #============================================================================== # The port to which the REST client connects to. If rest.bind-port has # not been specified, then the server will bind to this port as well. # rest.port: 9081 # The address to which the REST client will connect to # #rest.address: 0.0.0.0 # Port range for the REST and web server to bind to. # rest.bind-port: 9100-9124 # The address that the REST & web server binds to # #rest.bind-address: 0.0.0.0 # Flag to specify whether job submission is enabled from the web-based # runtime monitor. Uncomment to disable. web.submit.enable: false #============================================================================== # Advanced #============================================================================== # Override the directories for temporary files. If not specified, the # system-specific Java temporary directory (java.io.tmpdir property) is taken. # # For framework setups on Yarn or Mesos, Flink will automatically pick up the # containers' temp directories without any need for configuration. # # Add a delimited list for multiple directories, using the system directory # delimiter (colon ':' on unix) or a comma, e.g.: # /data1/tmp:/data2/tmp:/data3/tmp # # Note: Each directory entry is read from and written to by a different I/O # thread. You can include the same directory multiple times in order to create # multiple I/O threads against that directory. This is for example relevant for # high-throughput RAIDs. # io.tmp.dirs: /home/radmin/data/flink/tmp env.log.dir: /home/radmin/data/flink/logs # The classloading resolve order. Possible values are 'child-first' (Flink's default) # and 'parent-first' (Java's default). # # Child first classloading allows users to use different dependency/library # versions in their application than those in the classpath. Switching back # to 'parent-first' may help with debugging dependency issues. # # classloader.resolve-order: child-first # The amount of memory going to the network stack. These numbers usually need # no tuning. Adjusting them may be necessary in case of an "Insufficient number # of network buffers" error. The default min is 64MB, the default max is 1GB. # taskmanager.memory.network.fraction: 0.1 taskmanager.memory.network.min: 64mb taskmanager.memory.network.max: 1gb fs.hdfs.hadoopconf: /home/radmin/hadoop-2.10.0/etc/hadoop/ #============================================================================== # Flink Cluster Security Configuration #============================================================================== # Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors - # may be enabled in four steps: # 1. configure the local krb5.conf file # 2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit) # 3. make the credentials available to various JAAS login contexts # 4. configure the connector to use JAAS/SASL # The below configure how Kerberos credentials are provided. A keytab will be used instead of # a ticket cache if the keytab path and principal are set. # security.kerberos.login.use-ticket-cache: true # security.kerberos.login.keytab: /path/to/kerberos/keytab # security.kerberos.login.principal: flink-user # The configuration below defines which JAAS login contexts # security.kerberos.login.contexts: Client,KafkaClient #============================================================================== # ZK Security Configuration #============================================================================== # Below configurations are applicable if ZK ensemble is configured for security # Override below configuration to provide custom ZK service name if configured # zookeeper.sasl.service-name: zookeeper # The configuration below must match one of the values set in "security.kerberos.login.contexts" # zookeeper.sasl.login-context-name: Client #============================================================================== # HistoryServer #============================================================================== # The HistoryServer is started and stopped via bin/historyserver.sh (start|stop) # Directory to upload completed jobs to. Add this directory to the list of # monitored directories of the HistoryServer as well (see below). jobmanager.archive.fs.dir: hdfs://ns/flink/completed_jobs/ # The address under which the web-based HistoryServer listens. historyserver.web.address: 0.0.0.0 # The port under which the web-based HistoryServer listens. historyserver.web.port: 8082 # Comma separated list of directories to monitor for completed jobs. historyserver.archive.fs.dir: hdfs://ns/flink/completed_jobs/ # Interval in milliseconds for refreshing the monitored directories. historyserver.archive.fs.refresh-interval: 10000
masters
rexel-ids001:8081 rexel-ids002:8081
slaves
rexel-ids001 rexel-ids002 rexel-ids003
zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial synchronization phase can take
initLimit=10
# The number of ticks that can pass between sending a request and getting an acknowledgement
syncLimit=5
# The directory where the snapshot is stored.
dataDir=/home/radmin/data/zk/dataDir
dataLogDir=/home/radmin/data/zk/dataLogDir
# The port at which the clients will connect
clientPort=2181
# ZooKeeper quorum peers
server.0=rexel-ids001:2888:3888
server.1=rexel-ids002:2888:3888
server.2=rexel-ids003:2888:3888
==集群启动==
启动命令:./start-cluster.sh
【小插曲1】
启动的时候,出现了如下错误
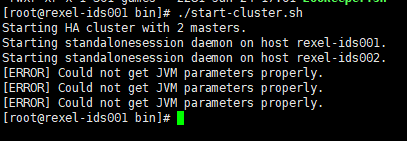
Starting HA cluster with 2 masters. Starting standalonesession daemon on host rexel-ids001. Starting standalonesession daemon on host rexel-ids002. [ERROR] Could not get JVM parameters properly. [ERROR] Could not get JVM parameters properly. [ERROR] Could not get JVM parameters properly.
具体原因尚不清楚,不过注释掉了flink-conf.xml中以下几个配置项之后,错误不在提示。
taskmanager.memory.process.size: 1024m taskmanager.memory.network.fraction: 0.1 taskmanager.memory.network.min: 64mb taskmanager.memory.network.max: 1gb
【小插曲2】
在启动日志中发现如下错误:

2020-03-12 12:42:04,933 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: parallelism.default, 1 2020-03-12 12:42:04,933 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.execution.failover-strategy, region 2020-03-12 12:42:04,936 WARN org.apache.flink.client.cli.CliFrontend - Could not load CLI class org.apache.flink.yarn.cli.FlinkYarnSessionCli. java.lang.NoClassDefFoundError: org/apache/hadoop/yarn/exceptions/YarnException at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:264) at org.apache.flink.client.cli.CliFrontend.loadCustomCommandLine(CliFrontend.java:1076) at org.apache.flink.client.cli.CliFrontend.loadCustomCommandLines(CliFrontend.java:1030) at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:957) Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.yarn.exceptions.YarnException at java.net.URLClassLoader.findClass(URLClassLoader.java:381) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) ... 5 more 2020-03-12 12:42:05,028 INFO org.apache.flink.core.fs.FileSystem - Hadoop is not in the classpath/dependencies. The extended set of supported File Systems via Hadoop is not available. 2020-03-12 12:42:05,057 INFO org.apache.flink.runtime.security.modules.HadoopModuleFactory - Cannot create Hadoop Security Module because Hadoop cannot be found in the Classpath. 2020-03-12 12:42:05,069 INFO org.apache.flink.runtime.security.modules.JaasModule - Jaas file will be created as /tmp/jaas-5195639153293838170.conf. 2020-03-12 12:42:05,071 INFO org.apache.flink.runtime.security.SecurityUtils - Cannot install HadoopSecurityContext because Hadoop cannot be found in the Classpath.
可以参考以下Flink官网的提示
https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/deployment/hadoop.html
解决办法就是在环境变量中增加
export HADOOP_CLASSPATH=`hadoop classpath`

【小插曲3】
集群启动之后,过一会jps查看flink进程,发现进程不存在了。
查看启动日志发现如下错误:
2020-03-12 14:12:07,474 ERROR org.apache.flink.runtime.taskexecutor.TaskManagerRunner - TaskManager initialization failed. java.io.IOException: Could not create FileSystem for highly available storage path (hdfs://ns/flink/recovery/default) at org.apache.flink.runtime.blob.BlobUtils.createFileSystemBlobStore(BlobUtils.java:103) at org.apache.flink.runtime.blob.BlobUtils.createBlobStoreFromConfig(BlobUtils.java:89) at org.apache.flink.runtime.highavailability.HighAvailabilityServicesUtils.createHighAvailabilityServices(HighAvailabilityServicesUtils.java:125) at org.apache.flink.runtime.taskexecutor.TaskManagerRunner.<init>(TaskManagerRunner.java:132) at org.apache.flink.runtime.taskexecutor.TaskManagerRunner.runTaskManager(TaskManagerRunner.java:308) at org.apache.flink.runtime.taskexecutor.TaskManagerRunner.lambda$runTaskManagerSecurely$2(TaskManagerRunner.java:322) at org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30) at org.apache.flink.runtime.taskexecutor.TaskManagerRunner.runTaskManagerSecurely(TaskManagerRunner.java:321) at org.apache.flink.runtime.taskexecutor.TaskManagerRunner.main(TaskManagerRunner.java:287) Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme 'hdfs'. The scheme is not directly supported by Flink and no Hadoop file system to support this scheme could be loaded. at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:450) at org.apache.flink.core.fs.FileSystem.get(FileSystem.java:362) at org.apache.flink.core.fs.Path.getFileSystem(Path.java:298) at org.apache.flink.runtime.blob.BlobUtils.createFileSystemBlobStore(BlobUtils.java:100) ... 8 more Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Hadoop is not in the classpath/dependencies. at org.apache.flink.core.fs.UnsupportedSchemeFactory.create(UnsupportedSchemeFactory.java:58) at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:446) ... 11 more
参照这个道友的博客之后。博客:https://my.oschina.net/u/2338224/blog/3101005
去下面的网站上找了相应的jar包,结果悲催的发现没有Flink1.10和hadoop2.10.0
https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/

怎么办?先尝试用2.8.3-10.0试试呢?还是把hadoop切换到2.8.3版本呢?先尝试了把包放进去
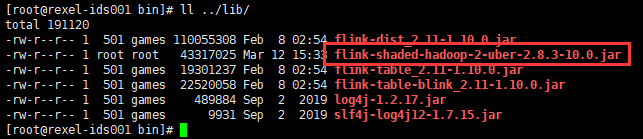
重新执行./start-cluster.sh之后,还好Flink集群正常启动起来了。
可以看到这两个进程一直都在,日志中也没有了上述错误。
==启动Web页面==
Web页面的端口号是8081。
看到这个页面真是挺开心的。毕竟挺不容易的。(先去打一把部落冲突,庆祝一下。)

==提交程序==
提交官方提供的WordCount程序试试
启动命令:flink run -m yarn-cluster -yn 1 /home/radmin/package/WordCount.jar
【小插曲1】
提交命令提示错误
Could not build the program from JAR file.
查看日志中有如下错误
2020-03-12 21:08:48,148 ERROR org.apache.flink.client.cli.CliFrontend - Invalid command line arguments. org.apache.flink.client.cli.CliArgsException: Could not build the program from JAR file. at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:203) at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:895) at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:968) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1836) at org.apache.flink.runtime.security.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:968) Caused by: java.io.FileNotFoundException: JAR file does not exist: -yn at org.apache.flink.client.cli.CliFrontend.getJarFile(CliFrontend.java:719) at org.apache.flink.client.cli.CliFrontend.buildProgram(CliFrontend.java:695) at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:200) ... 7 more
在社群里问了大牛之后,说在Flink1.10之后,取消了-yn的参数,所以才报这个错误。
【小插曲2】
删除-yn的参数之后,再次提交,又出现了以下错误
------------------------------------------------------------ The program finished with the following exception: org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: Could not deploy Yarn job cluster. at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:335) at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:205) at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:138) at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:664) at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213) at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:895) at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:968) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1836) at org.apache.flink.runtime.security.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:968) Caused by: org.apache.flink.client.deployment.ClusterDeploymentException: Could not deploy Yarn job cluster. at org.apache.flink.yarn.YarnClusterDescriptor.deployJobCluster(YarnClusterDescriptor.java:397) at org.apache.flink.client.deployment.executors.AbstractJobClusterExecutor.execute(AbstractJobClusterExecutor.java:70) at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.executeAsync(StreamExecutionEnvironment.java:1733) at org.apache.flink.streaming.api.environment.StreamContextEnvironment.executeAsync(StreamContextEnvironment.java:94) at org.apache.flink.streaming.api.environment.StreamContextEnvironment.execute(StreamContextEnvironment.java:63) at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1620) at org.apache.flink.streaming.examples.wordcount.WordCount.main(WordCount.java:96) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:321) ... 11 more Caused by: org.apache.flink.yarn.YarnClusterDescriptor$YarnDeploymentException: The cluster does not have the requested resources for the TaskManagers available! Maximum Memory: 512 Requested: 1024MB. Please check the 'yarn.scheduler.maximum-allocation-mb' and the 'yarn.nodemanager.resource.memory-mb' configuration values at org.apache.flink.yarn.YarnClusterDescriptor.validateClusterResources(YarnClusterDescriptor.java:543) at org.apache.flink.yarn.YarnClusterDescriptor.deployInternal(YarnClusterDescriptor.java:470) at org.apache.flink.yarn.YarnClusterDescriptor.deployJobCluster(YarnClusterDescriptor.java:390) ... 22 more
参考这位法力强大的道友的博客:https://www.jianshu.com/p/52da8b2e4ccc
详细从源码角度解读了job部署到yarn上的详细过程,上述错误为检查yarn资源的时候报的错误。
调大了Yarn一下两个配置的参数之后,Job正常提交完成。
调整参数:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>10240</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>10240</value>
</property>

【小插曲3】
提交Flink任务的时候告警
2020-05-25 11:21:33,627 WARN org.apache.hadoop.ipc.Client - Failed to connect to server: rexel-ids001/172.19.131.94:8032: retries get failed due to exceeded maximum allowed retries number: 0 java.net.ConnectException: Connection refused at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717) at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531) at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:685) at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:788) at org.apache.hadoop.ipc.Client$Connection.access$3500(Client.java:410) at org.apache.hadoop.ipc.Client.getConnection(Client.java:1550) at org.apache.hadoop.ipc.Client.call(Client.java:1381) at org.apache.hadoop.ipc.Client.call(Client.java:1345) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:227) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116) at com.sun.proxy.$Proxy7.getClusterNodes(Unknown Source) at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.getClusterNodes(ApplicationClientProtocolPBClientImpl.java:303) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:409) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:163) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:155) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:346) at com.sun.proxy.$Proxy8.getClusterNodes(Unknown Source) at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.getNodeReports(YarnClientImpl.java:564) at org.apache.flink.yarn.YarnClientYarnClusterInformationRetriever.getMaxVcores(YarnClientYarnClusterInformationRetriever.java:43) at org.apache.flink.yarn.YarnClusterDescriptor.isReadyForDeployment(YarnClusterDescriptor.java:278) at org.apache.flink.yarn.YarnClusterDescriptor.deployInternal(YarnClusterDescriptor.java:444) at org.apache.flink.yarn.YarnClusterDescriptor.deployJobCluster(YarnClusterDescriptor.java:390) at org.apache.flink.client.deployment.executors.AbstractJobClusterExecutor.execute(AbstractJobClusterExecutor.java:70) at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.executeAsync(StreamExecutionEnvironment.java:1733) at org.apache.flink.streaming.api.environment.StreamContextEnvironment.executeAsync(StreamContextEnvironment.java:94) at org.apache.flink.streaming.api.environment.StreamContextEnvironment.execute(StreamContextEnvironment.java:63) at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1620) at com.rexel.stream.flink.job.RexelStream.main(RexelStream.java:167) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:321) at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:205) at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:138) at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:664) at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213) at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:895) at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:968) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1836) at org.apache.flink.runtime.security.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:968)
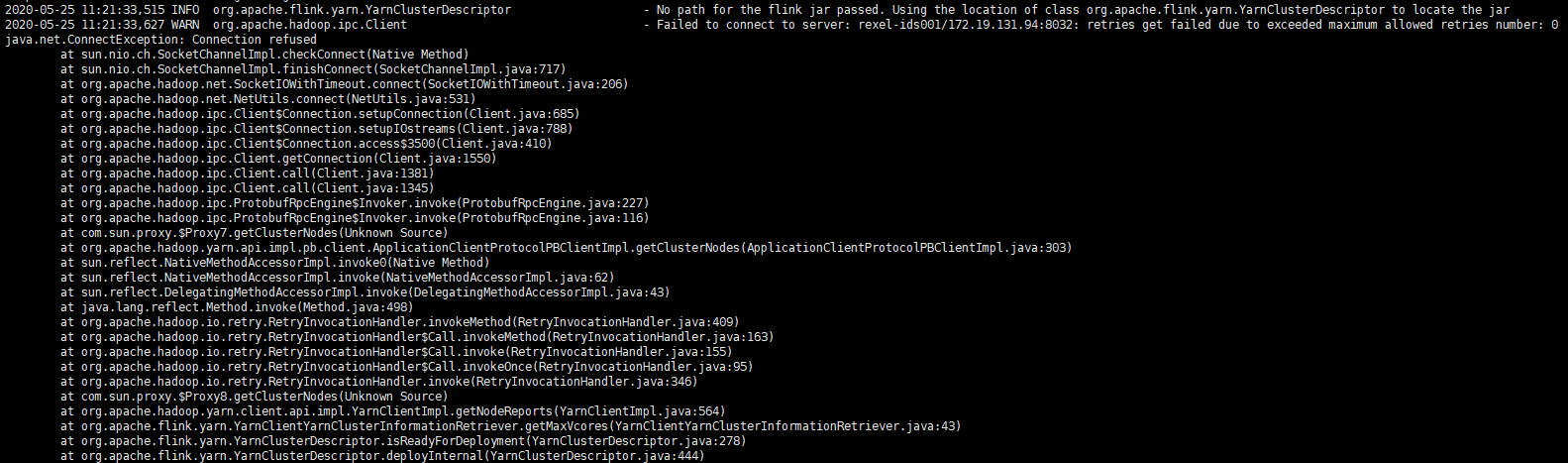
原因是Yarn的resourcemanager进行了主备切换,主节点不在当前服务器上,属于正常现象。
如果觉得不爽,可以切换一下ResourceManager的主备(把另一个节点的ResourceManager干掉,就自动切换了)
【小插曲4】
在我自己的虚机上装了一个Flink集群,运行任务的时候提示了以下错误
Note: System times on machines may be out of sync. Check system time and time zones. at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateExceptionImpl(SerializedExceptionPBImpl.java:171) at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:182) at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106) at org.apache.hadoop.yarn.client.api.impl.NMClientImpl.startContainer(NMClientImpl.java:206) at org.apache.hadoop.yarn.client.api.async.impl.NMClientAsyncImpl$StatefulContainer$StartContainerTransition.transition(NMClientAsyncImpl.java:450) at org.apache.hadoop.yarn.client.api.async.impl.NMClientAsyncImpl$StatefulContainer$StartContainerTransition.transition(NMClientAsyncImpl.java:436) at org.apache.hadoop.yarn.state.StateMachineFactory$MultipleInternalArc.doTransition(StateMachineFactory.java:385) at org.apache.hadoop.yarn.state.StateMachineFactory.doTransition(StateMachineFactory.java:302) at org.apache.hadoop.yarn.state.StateMachineFactory.access$300(StateMachineFactory.java:46) at org.apache.hadoop.yarn.state.StateMachineFactory$InternalStateMachine.doTransition(StateMachineFactory.java:448) at org.apache.hadoop.yarn.client.api.async.impl.NMClientAsyncImpl$StatefulContainer.handle(NMClientAsyncImpl.java:617) at org.apache.hadoop.yarn.client.api.async.impl.NMClientAsyncImpl$ContainerEventProcessor.run(NMClientAsyncImpl.java:676) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745)
从日志中可以看出来,提示的是系统时间不同步,尝试了对虚机的3个节点安装NTP时间同步服务
具体安装步骤可以参考我以前的博客:Linux配置ntp时间服务器(全)
配置了NTP时间同步,然后重启了zookeeper、hadoop、flink集群之后,问题解决。
--END--