本文简要介绍Java并发编程方面常用的类和集合,并介绍下其实现原理。
AtomicInteger
可以用原子方式更新int值。类 AtomicBoolean、AtomicInteger、AtomicLong 和 AtomicReference 的实例各自提供对相应类型单个变量的访问和更新。基本的原理都是使用CAS操作:
boolean compareAndSet(expectedValue, updateValue);
如果此方法(在不同的类间参数类型也不同)当前保持expectedValue,则以原子方式将变量设置为updateValue,并在成功时报告true。
循环CAS,参考AtomicInteger中的实现:

public final int getAndIncrement() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return current;
}
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
ABA问题
因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进 行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加 一,那么A-B-A 就会变成1A-2B-3A。
从Java1.5开始JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的
compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的
值设置为给定的更新值。
public boolean compareAndSet(
V expectedReference,//预期引用
V newReference,//更新后的引用
int expectedStamp, //预期标志
int newStamp) //更新后的标志
ArrayBlockingQueue
一个由数组支持的有界阻塞队列。此队列按 FIFO(先进先出)原则对元素进行排序。队列的头部是在队列中存在时间最长的元素。队列的尾部是在队列中存在时间最短的元素。新元素插入到队列的尾部, 队列获取操作则是从队列头部开始获得元素。这是一个典型的“有界缓存区”,固定大小的数组在其中保持生产者插入的元素和使用者提取的元素。一旦创建了这样 的缓存区,就不能再增加其容量。试图向已满队列中放入元素会导致操作受阻塞;试图从空队列中提取元素将导致类似阻塞。
此类支持对等待的生产者线程和使用者线程进行排序的可选公平策略。默认情况下,不保证是这种排序。然而,通过将公平性(fairness)设置为true而构造的队列允许按照 FIFO 顺序访问线程。公平性通常会降低吞吐量,但也减少了可变性和避免了“不平衡性”。
一些源代码参考:
/** Main lock guarding all access */
final ReentrantLock lock;
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
insert(e);
} finally {
lock.unlock();
}
}
private void insert(E x) {
items[putIndex] = x;
putIndex = inc(putIndex);
++count;
notEmpty.signal();
}
final int inc(int i) {
return (++i == items.length) ? 0 : i;
}
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return extract();
} finally {
lock.unlock();
}
}
private E extract() {
final Object[] items = this.items;
E x = this.<E>cast(items[takeIndex]);
items[takeIndex] = null;
takeIndex = inc(takeIndex);
--count;
notFull.signal();
return x;
}
final int dec(int i) {
return ((i == 0) ? items.length : i) - 1;
}
@SuppressWarnings("unchecked")
static <E> E cast(Object item) {
return (E) item;
}
ArrayBlockingQueue只使用了一个lock来控制互斥访问,所有的互斥访问都在这个lock的try finally中实现。
LinkedBlockingQueue
一个基于已链接节点的、范围任意的blocking queue。此队列按 FIFO(先进先出)排序元素。队列的头部是在队列中时间最长的元素。队列的尾部是在队列中时间最短的元素。新元素插入到队列的尾部,并且队列获取操作会 获得位于队列头部的元素。链接队列的吞吐量通常要高于基于数组的队列,但是在大多数并发应用程序中,其可预知的性能要低。
可选的容量范围构造方法参数作为防止队列过度扩展的一种方法。如果未指定容量,则它等于Integer.MAX_VALUE。除非插入节点会使队列超出容量,否则每次插入后会动态地创建链接节点。
如果构造一个LinkedBlockingQueue对象,而没有指定其容量大小,LinkedBlockingQueue会默认一个类似无限大小 的容量(Integer.MAX_VALUE),这样的话,如果生产者的速度一旦大于消费者的速度,也许还没有等到队列满阻塞产生,系统内存就有可能已被 消耗殆尽了。
一些实现代码:
/** The capacity bound, or Integer.MAX_VALUE if none */
private final int capacity;
/** Current number of elements */
private final AtomicInteger count = new AtomicInteger(0);
/** Lock held by take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock();
/** Wait queue for waiting takes */
private final Condition notEmpty = takeLock.newCondition();
/** Lock held by put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
/** Wait queue for waiting puts */
private final Condition notFull = putLock.newCondition();
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
// Note: convention in all put/take/etc is to preset local var
// holding count negative to indicate failure unless set.
int c = -1;
Node<E> node = new Node(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
/*
* Note that count is used in wait guard even though it is
* not protected by lock. This works because count can
* only decrease at this point (all other puts are shut
* out by lock), and we (or some other waiting put) are
* signalled if it ever changes from capacity. Similarly
* for all other uses of count in other wait guards.
*/
while (count.get() == capacity) {
notFull.await();
}
enqueue(node);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
}
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {
notEmpty.await();
}
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
从源代码实现来看,LinkedBlockingQueue使用了2个lock,一个takelock和一个putlock,读和写用不同的lock来控制,这样并发效率更高。
ConcurrentLinkedQueue
ArrayBlockingQueue和LinkedBlockingQueue都是使用lock来实现的,也就是阻塞式的队列,而ConcurrentLinkedQueue使用CAS来实现,是非阻塞式的“lock-free”实现。
ConcurrentLinkedQueue源代码的实现有点复杂,具体的可看这篇文章的分析:
http://www.infoq.com/cn/articles/ConcurrentLinkedQueue
ConcurrentHashMap
HashMap不是线程安全的。
HashTable容器使用synchronized来保证线程安全,在线程竞争激烈的情况下HashTable的效率非常低下。
ConcurrentHashMap采用了Segment分段技术,容器里有多把锁,每把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率。
ConcurrentHashMap结构:
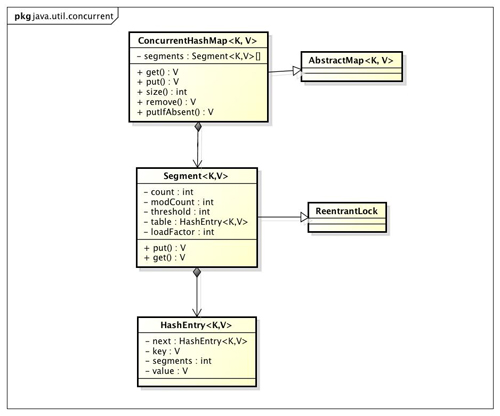
ConcurrentHashMap的实现原理分析:
http://www.infoq.com/cn/articles/ConcurrentHashMap
CopyOnWriteArrayList
CopyOnWrite容器即写时复制的容器。往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容 器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是可以对CopyOnWrite容器进行并发的读,而不需要加 锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。类似的有 CopyOnWriteArraySet。
public boolean add(T e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// 复制出新数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 把新元素添加到新数组里
newElements[len] = e;
// 把原数组引用指向新数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
final void setArray(Object[] a) {
array = a;
}
读的时候不需要加锁,如果读的时候有多个线程正在向ArrayList添加数据,读还是会读到旧的数据,因为写的时候不会锁住旧的ArrayList。
public E get(int index) {
return get(getArray(), index);
}
AbstractQueuedSynchronizer
为实现依赖于先进先出 (FIFO) 等待队列的阻塞锁和相关同步器(信号量、事件,等等)提供一个框架。此类的设计目标是成为依靠单个原子 int 值来表示状态的大多数同步器的一个有用基础。子类必须定义更改此状态的受保护方法,并定义哪种状态对于此对象意味着被获取或被释放。假定这些条件之后,此 类中的其他方法就可以实现所有排队和阻塞机制。子类可以维护其他状态字段,但只是为了获得同步而只追踪使用 getState()、setState(int) 和 compareAndSetState(int, int) 方法来操作以原子方式更新的 int 值。
使用示例
以下是一个非再进入的互斥锁类,它使用值 0 表示未锁定状态,使用 1 表示锁定状态。当非重入锁定不严格地需要当前拥有者线程的记录时,此类使得使用监视器更加方便。它还支持一些条件并公开了一个检测方法:
class Mutex implements Lock, java.io.Serializable {
// Our internal helper class
private static class Sync extends AbstractQueuedSynchronizer {
// Report whether in locked state
protected boolean isHeldExclusively() {
return getState() == 1;
}
// Acquire the lock if state is zero
public boolean tryAcquire(int acquires) {
assert acquires == 1; // Otherwise unused
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
// Release the lock by setting state to zero
protected boolean tryRelease(int releases) {
assert releases == 1; // Otherwise unused
if (getState() == 0) throw new IllegalMonitorStateException();
setExclusiveOwnerThread(null);
setState(0);
return true;
}
// Provide a Condition
Condition newCondition() { return new ConditionObject(); }
// Deserialize properly
private void readObject(ObjectInputStream s)
throws IOException, ClassNotFoundException {
s.defaultReadObject();
setState(0); // reset to unlocked state
}
}
// The sync object does all the hard work. We just forward to it.
private final Sync sync = new Sync();
public void lock() { sync.acquire(1); }
public boolean tryLock() { return sync.tryAcquire(1); }
public void unlock() { sync.release(1); }
public Condition newCondition() { return sync.newCondition(); }
public boolean isLocked() { return sync.isHeldExclusively(); }
public boolean hasQueuedThreads() { return sync.hasQueuedThreads(); }
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
public boolean tryLock(long timeout, TimeUnit unit)
throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(timeout));
}
}
ThreadPoolExecutor
ThreadPoolExecutor 的内部工作原理,整个思路总结起来就是 5 句话:
1. 如果当前池大小 poolSize 小于 corePoolSize ,则创建新线程执行任务。
2. 如果当前池大小 poolSize 大于 corePoolSize ,且等待队列未满,则进入等待队列
3. 如果当前池大小 poolSize 大于 corePoolSize 且小于 maximumPoolSize ,且等待队列已满,则创建新线程执行任务。
4. 如果当前池大小 poolSize 大于 corePoolSize 且大于 maximumPoolSize ,且等待队列已满,则调用拒绝策略来处理该任务。
5. 线程池里的每个线程执行完任务后不会立刻退出,而是会去检查下等待队列里是否还有线程任务需要执行,如果在 keepAliveTime 里等不到新的任务了,那么线程就会退出。
排队有三种通用策略:
直接提交。工作队列的默认选项是SynchronousQueue,它将任务直接提交给线程而不保持它们。在此,如果不存在可用于立即运行任务的线 程,则试图把任务加入队列将失败,因此会构造一个新的线程。此策略可以避免在处理可能具有内部依赖性的请求集时出现锁。直接提交通常要求无界 maximumPoolSizes 以避免拒绝新提交的任务。当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
无界队列。使用无界队列(例如,不具有预定义容量的LinkedBlockingQueue)将导致在所有 corePoolSize 线程都忙时新任务在队列中等待。这样,创建的线程就不会超过 corePoolSize。(因此,maximumPoolSize 的值也就无效了。)当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web 页服务器中。这种排队可用于处理瞬态突发请求,当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
有界队列。当使用有限的 maximumPoolSizes 时,有界队列(如ArrayBlockingQueue)有助于防止资源耗尽,但是可能较难调整和控制。队列大小和最大池大小可能需要相互折衷:使用大型 队列和小型池可以最大限度地降低 CPU 使用率、操作系统资源和上下文切换开销,但是可能导致人工降低吞吐量。如果任务频繁阻塞(例如,如果它们是 I/O 边界),则系统可能为超过您许可的更多线程安排时间。使用小型队列通常要求较大的池大小,CPU 使用率较高,但是可能遇到不可接受的调度开销,这样也会降低吞吐量。
ThreadFactory 和 RejectedExecutionHandler是ThreadPoolExecutor的两个属性,也 可以 认为是两个简单的扩展点. ThreadFactory 是创建线程的工厂。默认的线程工厂会创建一个带有“ pool-poolNumber- thread-threadNumber ”为名字的线程,如果我们有特别的需要,如线程组命名、优先级等,可以定制自己的 ThreadFactory 。
RejectedExecutionHandler 是拒绝的策略。常见有以下几种:
AbortPolicy :不执行,会抛出 RejectedExecutionException 异常。
CallerRunsPolicy :由调用者(调用线程池的主线程)执行。
DiscardOldestPolicy :抛弃等待队列中最老的。
DiscardPolicy: 不做任何处理,即抛弃当前任务。
ScheduleThreadPoolExecutor 是对ThreadPoolExecutor的集成。增加了定时触发线程任务的功能。需要注 意从内部实现看,ScheduleThreadPoolExecutor 使用的是 corePoolSize 线程和一个无界队列的固定大小的池, 所以调整 maximumPoolSize 没有效果。无界队列是一个内部自定义的 DelayedWorkQueue 。
FixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
实际上就是个不支持keepalivetime,且corePoolSize和maximumPoolSize相等的线程池。
SingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
实际上就是个不支持keepalivetime,且corePoolSize和maximumPoolSize都等1的线程池。
CachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
实际上就是个支持keepalivetime时间是60秒(线程空闲存活时间),且corePoolSize为0,maximumPoolSize无穷大的线程池。
SingleThreadScheduledExecutor
public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1, threadFactory));
}
实际上是个corePoolSize为1的ScheduledExecutor。上文说过ScheduledExecutor采用无界等待队列,所以maximumPoolSize没有作用。
ScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
实际上是corePoolSize课设定的ScheduledExecutor。上文说过ScheduledExecutor采用无界等待队列,所以maximumPoolSize没有作用。
参考:
《java并发编程的艺术》