Java爬虫领域最强大的框架是JSoup:可直接解析具体的URL地址(即解析对应的HTML),提供了一套强大的API,包括可以通过DOM、CSS选择器,即类似jQuery方式来取出和操作数据。主要功能有:
- 从给定的URL、文件、字符串中,获得HTML代码。
- 然后通过DOM、CSS选择器(类jQuery方式)来查找、取出数据:先找到HTML元素,然后获取其属性、文本等。
API初步学习:
上面提到了三种方式,获取HTML文档(JSoup的Document对象的结构是:<html><head></head><body></body></html>):
1、通过字符串:String html="hello"; Document doc = Jsoup.parse(html);//(此时JSoup会把hello放在doc对象中的body中。如果字符串是一个完整的html文档,那么doc对象将以字符串的html结构为准)。
2、获取URL的HTML文档(注意:这种方式下,只有当调用get或post方法时,才真正发送请求):
//通过URL获得连接:Connection对象
Connection conn = Jsoup.connect("http://www.baidu.com");
//以下为主要方法,多数返回Connection
conn.data("query", "Java"); // 请求参数
conn.userAgent("I ’ m jsoup"); // 设置 User-Agent
conn.cookie("auth", "token"); // 设置 cookie
conn.timeout(3000); // 设置连接超时时间
//发送请求,获得HTML文档:Document对象
Document doc = conn.get();
Document doc = conn.post();
获取元素:
1、通过DOM方式(与纯JavaScript方式相同):
//获取文档级信息,如:
String title = doc.title();
//获取单个HTML元素,如:<div id="content"></div>
Element content = doc.getElementById("content");
//获取多个元素,如:<a href="http://www.qunyh.cn"></a> <a href="http://cn.bing.com"></a>
Elements links = doc.getElementsByTag("a");
2、类似于jQuery的方式,这里是将$换成了select方法:
//select的参数是类似于jQuery的选择器selector
Elements allP = doc.select("p");
Element firstP = allP.first();
Element oneP = allP.get(1);//从0开始
//操作元素:
for (Element p : allP) {
//操纵元素:这里就类似于jQuery
String text = p.text();
}
当然JSoup只是模仿jQuery的方便性,并不具备jQuery的所有功能,例如jQuery的插件肯定是无法在JSoup中使用。因此如果对JS掌握很好,选择Node.js+MongoDB来处理就比较有优势(即相互之间的支持度比较大)。如果熟悉Java,那么就可以选择JSoup+MySql+Quartz,也是非常好用的(全程java实现,省心方便),再配合Java调度器Quartz,就可实现一个完整的爬虫了。
爬虫框架 Gecco:
Gecco 是用 Java 实现的,轻量化,面向主题的爬虫,与 Nutch 这种面向搜索引擎的通用爬虫不同:
- 通用爬虫通常关注三个问题:下载、排序、索引。
- 主题爬虫则关注:下载、内容抽取、灵活的业务逻辑处理。
Gecco 的目标:提供一个完善的主题爬虫框架:简化下载和内容抽取的开发;利用管道过滤器模式,提供灵活的内容清洗和持久化处理模式。故而开发可以集中精力在业务主题方面的逻辑、内容处理。
学习一个框架,首先要了解到它的用途何在:
- 简单易用,使用 jQuery 的 Selector 风格抽取元素。
- 支持页面中的异步 Ajax 请求。
- 支持页面中的 JavaScript 变量抽取。
- 利用 Redis 实现分布式抓取,可参考 Gecco-Redis。
- 支持下载时 UserAgent 随机选取。
- 支持下载代理服务器随机选取。
- 支持结合 Spring 开发业务逻辑,参考 Gecco-Spring。
- 支持 htmlUnit 扩展,参考 Gecco-htmlUnit。
- 支持插件扩展机制。
一分钟你就可以写一个简单爬虫:
先将一个基本的程序撂出来(内容以 json 格式在 console 输出):
@Gecco(matchUrl = "https://github.com/{user}/{project}", pipelines = "consolePipeline")
public class Tester implements HtmlBean {
private static final long serialVersionUID = 4538118606557597719L;
@RequestParameter("user")
private String user;
@RequestParameter("project")
private String project;
@Text
@HtmlField(cssPath = ".repository-meta-content .mr-2")
private String title;
@Text
@HtmlField(cssPath = ".pagehead-actions li:nth-child(2) .social-count")
private int star;
@Text
@HtmlField(cssPath = ".pagehead-actions li:nth-child(3) .social-count")
private int fork;
@Html
@HtmlField(cssPath = ".entry-content")
private String readme;
// 此处略去 getter and setter
public static void main(String[] args) {
GeccoEngine.create()
// Geeco搜索的包路径:即使用了@Geeco注解的类所在的包路径
.classpath("com.jackie.json.controller")
// 最开始抓取的页面地址:简单的就是一个,当然也有可变参数列表的重载(即接受多个url地址参数)
.start("https://github.com/xtuhcy/gecco")
// 开启几个爬虫线程
.thread(1)
// 对每个爬虫而言,每次抓取完一个请求之后,再次请求的间隔时间
.interval(2000)
// 与上面的start方法用途不同,用于启动爬虫线程:start方法非阻塞式运行爬虫;run方法则是阻塞式
.start();
}
}
代码说明:
- 首先爬虫类 implements 了一个 HtmlBean 接口:说明了该爬虫是一个解析 html 页面的爬虫(还可以支持 json 格式的解析,即 JsonBean)。
- @Gecco 注解:告知爬虫,匹配的 url 格式(matchUrl)和内容抽取后的 bean 处理类 pipelines(采用管道过滤器模式,可以指定多个 pipeline 处理类。例如指定为 consolePipeline,则输出在 console 中)。
- @RequestParamter:注入请求过的 url 中匹配的请求参数,如@RequestParamer("user") 则匹配到 url 中的 {user}。
- @HtmlField:表示抽取 html 中的元素,其中 cssPath 采用类似于 jQuery 的 css selector 的方式选取元素。
- @Text:表示获取 @HtmlField 抽取元素的 Text 内容。@Html:表示获取对应的 Html 内容(默认 @Html)。注意的是:若抽取的元素中没有 html 代码,则不能指定为 @Html,否则会报错;若有 html 代码,则不能指定为 @Text,否则不能获取任何内容,将会输出为空字符串。
- GeccoEngine:爬虫引擎类,通过 create() 初始化,通过 start() / run() 运行。还可以配置一些启动参数,如上代码所示,后面也会详细介绍。
软件总体架构(爬虫引擎的架构):
如图:
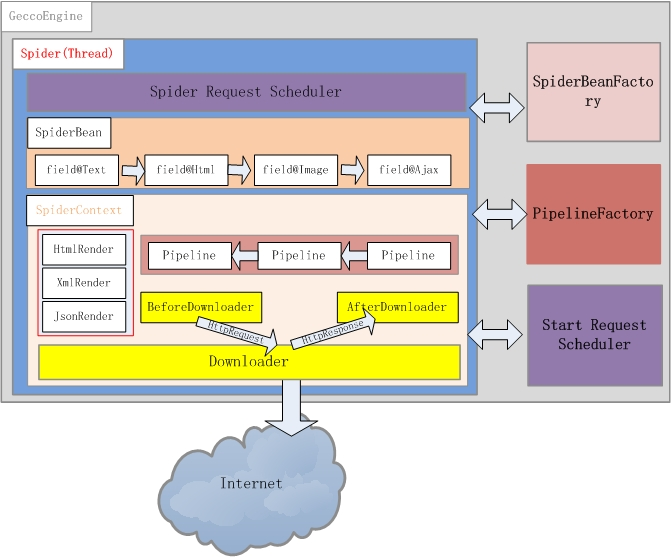
简单介绍:
- GeccoEngine:爬虫引擎,每个爬虫引擎最好是一个独立进程。在分布式爬虫场景下,建议每台爬虫服务器(物理机、虚拟机)只运行一个 GeccoEngine。爬虫引擎主要包括Scheduler、Downloader、Spider、SpiderFactory、PipelineFactory 5个模块。
- Scheduler:
GeccoEngine 的详细介绍:
Gecco 如何运行,下面是最基本的启动方法:
GeccoEngine.create() // classpath是必填项 .classpath("com.geccocrawler.gecco.demo") // 初始请求地址 .start("https://github.com/xtuhcy/gecco") .start();
GeccoEngine 的基本配置:
- loop(boolean):表示是否循环抓取,默认为 false。
- thread(int):表示开启的爬虫线程数量,默认是1。值得注意的是,线程数量要小于等于 start 方法中指定的 url 数量。
- interval(int):表示请求间隔时间,单位是毫秒 ms。假设设置的值是 x 秒,那么系统会把间隔时间随机在 [ x - 1, x + 1] 这个区间内(1 即指 1 秒)。例如,设置为 2000 ms,那么最终的间隔时间将会在 1000 ms ~ 3000 ms 内随机。
- mobile(bollean):表示使用移动端还是 pc 端的 UserAgent。默认为 false,使用 pc 端的 UserAgent。
- debug(boolean):是否开启 debug 模式,即如果开启 debug 模式,那么将会在控制台输出 JSoup 元素抽取的日志 —— 如果出了问题才能在日志中找到原因。
- pipelineFactory(PipelineFactory):设置自定义的 pipelineFactory,通过实现 PipelineFactory 接口,自定义 pipelineFactory 类。
- scheduler(Scheduler):设置自定义的请求队列管理器 Scheduler。
非阻塞式启动和阻塞式启动:
- start():非阻塞式启动,即 GeccoEngine 会单独启动线程运行。推荐以该方式运行,线程模式如下:MainThread ——> GeccoEngineThread ——> SpiderThread。
- run():阻塞式启动,GeccoEngine 在主线程中启动并运行。非循环模式 GeccoEngine 需要等待其他爬虫线程运行完毕后,run() 方法才会退出。线程模型如下:GeccoEngineThread(即在主线程中)——> SpiderThread。
Gecco 如何匹配 URL:
matchUrl 的作用:告知 Gecco,这种格式的 url 对应的网页将会被渲染成当前指定的 SpiderBean(如包装成 HtmlBean 的对象)。matchUrl 模糊匹配模式中的 {} 可以匹配任意非空字符串,除了 "/"。
如果不写 matchUrl,则为任意匹配模式,那么任意的 url 都会被匹配,可用作通用爬虫,例如官网给出的 CommonClawer。
说说下载:
下载引擎:爬虫最基本的能力就是发起 http 请求,然后下载网页。Gecco 默认采用 httpClientDownloader(httpclient4)作为下载引擎。通过实现 downloader 接口,可以自定义设置下载引擎。例如:
@Gecco(matchUrl="https://github.com/{user}/{project}", pipelines="consolePipeline", downloader="htmlUnitDownloder")
HttpRequest 和 HttpReponse:一个表示下载请求,一个表示下载响应。爬虫会模拟浏览器,将下载请求包装成 GET 或 POST 请求,分别对应 HttpGetRequest、HttpPostRequest 类。
Gecco 的请求可以支持:
- 模拟 userAgent,并支持 userAgent 的随机轮询。在 classpath 的根目录下定义 userAgents 文件,每行代表一个 UserAgent。
- cookie 定义:request.addCookie(String name, String value),可模拟用户登录。
- 代理服务器的随机轮询。在 classpath 的根目录下定义 proxys 文件,每行代表一个代理服务器的主机和端口,如 127.0.0.1:8888。
下载地址管理:
爬虫通常需要一个请求队列管理器 Scheduler,负责下载地址的管理:
Gecco 使用 StartScheduler 管理初始地址,StartScheduler 内部采用一个阻塞的 FIFO 队列(即严格的 FIFO,一个线程抓取完一个地址之后,才会去抓另一个地址);初始地址通常会派生出很多其他待抓取的地址(例如列表页是初始地址的集合页面,详情页是派生的地址),并用 SpiderScheduler 管理派生的地址,SpiderScheduler 内部采用线程安全的非阻塞 FIFO 队列(不严格的先进先出)。
这种设计使得 Gecco 对初始地址采用了深度遍历(理解还不够深刻)?的策略;对派生的地址采用了广度遍历的策略(如何派生参考下面的 “派生地址“)。此外,Gecco 的分布式抓取也是通过 Scheduler 完成,准确的说是通过实现不同的StartScheduler,来将初始地址分配到不同的服务器中来完成;Gecco 分布式抓取默认采用 redis 来实现,具体参考 gecco-redis 项目。
派生地址:
Gecco 派生地址的方式有两种:
一是使用注解,如下:
@Href(click = true) @HtmlField(cssPath = "...") private String detailUrl;
派生地址如同其他内容一样,需要使用 @HtmlField 注解,从初始地址的页面中抽取。不同的是 @Href 注解,当参数 click 为 true 时,抽取出来的 url 会继续抓取。
二是显式的加入 SpiderScheduler 的方法,如:
DeriveSchedulerContext.into(request.subRequest("subUrl"));
上面的 HttpRequest 对象可以通过 @Request 注解获得,然后通过该对象的 subRequest 方法生成对派生地址的请求,然后加入到 SpiderScheduler 队列中。可以在相应的 pipeline 类中对请求的增加进行过滤。
初始地址的配置:
可以在 classpath 根目录下,放置 starts.json 配置文件,可配置多个初始地址,如下:
[ { "charset": "GBK", "url": "http://item.jd.com/123.html" }, { "url": "https://github.com/xtuhcy/gecco" } ]
此外,如果要设置的初始地址不多,则可以如上面的程序,直接在 GeccoEngine.start(String ...) 方法中添加。
BeforeDownload 和 AfterDownload:
有一些特殊场景,可能会需要在下载的前后做一些处理,处理之后再传递给 pipeline 输出。如下:
@GeccoClass(CruiseDetail.class) public class CruiseDetailBeforeDownload implements BeforeDownload { @Override public void process(HttpRequest request) { } }
上面这个类是针对 CruiseDetail 这个 bean 的下载之前的自定义预处理。同理,下载后如下:
@GeccoClass(CruiseRedirect.class) public class CruiseRedirectAfterDownload implements AfterDownload { @Override public void process(HttpRequest request, HttpResponse response) { } }
使用 HtmlUnit 作为下载引擎:
Gecco 通过扩展 downloader 实现了对 htmlUnit 的支持,如下(使用详情参照 gecco-htmunit 项目):
<dependency> <groupId>com.geccocrawler</groupId> <artifactId>gecco-htmlunit</artifactId> <version>1.0.9</version> </dependency>
找资料的时候发现了新的、不错的爬虫框架(以后有时间尝试):
Gecco Crawler:
Gecco是一款用java语言开发的轻量化的易用的网络爬虫,不同于Nutch这样的面向搜索引擎的通用爬虫,Gecco是面向主题的爬虫。
https://github.com/xtuhcy/gecco
https://xtuhcy.gitbooks.io/geccocrawler/content/index.html
https://my.oschina.net/u/2336761/blog/688534
模板代码生成器:J2ee template(由JSoup开发而成,可借鉴其如何开发的爬虫):
https://www.oschina.net/p/jeetemp