一、内置函数如何使用
help()一下:
如想看min()咋用?在shell中:help(min)
二、部分内置函数
(一).排序:sorted()


li = [(1, 2, 3, 4), (7, 8, 1, 4), (3, 4, 6, 2), (6, 5, 9, 2)] print(sorted(li, key=lambda a: a[1])) # lambda a: a[1] 以元组的第二个值作为排序依据。 # 运行结果:[(1, 2, 3, 4), (3, 4, 6, 2), (6, 5, 9, 2), (7, 8, 1, 4)]
sorted()是python3的内置函数,返回一个新列表,不改变原来的数据,如要改变需赋值。
sort()是列表的函数:list.sort(),没有返回值,直接在原数据上进行修改。
例1:以第二级路径为准,进行从小到大排序
l3 = ['/boot/grub', '/usr/local', '/home/dongwm'] print(sorted(l3, key=lambda x: x.split("/")[2])) """ ['/home/dongwm', '/boot/grub', '/usr/local'] for each in l3: print(each.split("/")) 结果:(因为第一个斜杠前没有任何内容,所以切出来是空字符) ['', 'boot', 'grub'] ['', 'usr', 'local'] ['', 'home', 'dongwm'] """
(二).枚举:enumerate()
enumerate是个迭代器。如要查看枚举中的内容,可用list(),tuple()来查看。
print(list(enumerate([1, 2, 3]))) # 运行结果:[(0, 1), (1, 2), (2, 3)] # 可指定索引的开始值: print(list(enumerate([1, 2, 3], 2))) # 运行结果:[(2, 1), (3, 2), (4, 3)] # 转换为一个字典:(这里同样指定了索引的开始值) print(dict(enumerate([1, 2, 3], 2))) # 运行结果:{2: 1, 3: 2, 4: 3}
(三).过滤器:filter(function or None,iterable)
筛选出自己想要的内容。对每个元素进行判断,返回True或False,返回False会被自动过滤掉,返回由符合条件元素组成的新迭代器对象。
第一个参数需要放一个函数体,或者写"None",因为是必备参数。
# 提取一个列表中,出大于2的元素 print(list(filter(lambda x: x > 2, [1, 2, 3, 4, 5])))
# 运行结果:[3, 4, 5]
如上运行结果:把符合条件的都提取出来了。
(四).zip(iterable1,iterable2,...)
是一个匹对的内建函数,将可迭代对象中的元素,一对一地进行匹对起来。以最短的那个iterable为参照!
# 对每个iterable中的元素进行逐一匹对 print(list(zip([1, 2, 3], ["a", "b", "c"], [10, 20, 30]))) # 运行结果:[(1, 'a', 10), (2, 'b', 20), (3, 'c', 30)] # 既然是一一对应,那么少了其中任何一个都不会再去匹对了 # 少了第二个iterable中的 "b" print(list(zip([1, 2, 3], ["a", "c"], [10, 20, 30]))) # 运行结果:[(1, 'a', 10), (2, 'c', 20)] # 少了第一个iterable中的2和第三个iterable中的10 print(list(zip([1, 3], ["a", "b", "c"], [20, 30]))) # 运行结果:[(1, 'a', 20), (3, 'b', 30)]
# 同时遍历两个或更多的序列,可以使用 zip() 组合 questions = ["what's your name", "how old", "favorite color"] answers = ["quanquan616", 30, "blue"] for i, j in zip(questions, answers): print("{}? {}".format(i, j)) """ 运行结果: what's your name? quanquan616 how old? 30 favorite color? blue """
# 将两支队伍随机打乱,然后进行两两匹对 p1 = ["猛龙", "老鹰", "公牛", "凯尔特人", "湖人"] p2 = ["魔术", "奇才", "雄鹿", "雷霆", "鹈鹕"] from random import shuffle shuffle(p1) shuffle(p2) for i, j in zip(p1, p2): print(f"{i} VS {j}") """ 湖人 VS 雷霆 猛龙 VS 奇才 公牛 VS 雄鹿 凯尔特人 VS 魔术 老鹰 VS 鹈鹕 """
(五).加工:map(func,iterable)
func是指定一个函数体,指定以什么方式去加工。把函数依次作用在序列的每个元素上,得到一个新的迭代器对象。
print(list(map(str, [1, 2, 3]))) # 远行结果:['1', '2', '3']
此例中,str是指定了加工的方式。
list()是用来查看map()对象中的元素,tuple()也可以。
(六).反复调用函数:reduce(func,iterable)
reduce()指定的函数必须接收两个参数,reduce对可迭代对象的每个元素反复调用函数,并返回最终结果值。
例1:
from functools import reduce def add(a, b): return a + b print(reduce(add, [1, 2, 3])) # 6
例1中,先把1和2传给函数add,执行并返回了3。接着刚才的结果3当做a,列表中的第三个元素3当做参数b,再去传值并调用add函数,最后返回总结果6。
例2:
from functools import reduce def add(x, b): return x + b print(reduce(add, [1, 2, 3], 10)) # 16
例2说明了reduce还可以接受第三个参数,作为计算的初始值10。
三、作用域(全局、局部变量)
全局变量定义在函数体外,可以访问,但不可以修改。
(一).global用途
(1)、如果要修改函数体外定义的全局变量,需要在对应变量名前加"global"关键字来修饰。(类似授权的概念)
(2)、函数体中的局部变量,如果要在函数体外访问到它,也需要在前加"global"
# --- global 第一种用法 --- # n = 1 # 这里是全局变量 def fun(): n += 1 print(n) fun() # 运行直接报错! # UnboundLocalError: local variable 'n' referenced before assignment # 大意:n 是局部变量,未定义,无法使用 # 需要在 n 前加上 global n = 1 def fun(): global n # 不能写成:global n += 1 会报语法错误! n += 1 print(n) fun() # 还有一种情况: n = 1 # 这里是全局变量 def fun(a, b): n = a + b # n 在这里是局部变量 print(n) fun(10, 20) print(n) # 运行结果:30 1
# --- global 第二种用法 --- # def fun(): n = 616 fun() print(n) # NameError: name 'n' is not defined // 语法错误 n 没有定义 # 在外要想访问函数体里的局部变量 n 就需要在前面加 global def fun(): # 如果 n 在 global 语句前定义,就会报错! # SyntaxError: name 'n' is assigned to before global declaration # 语法错误:n 在global声明前就分配了 global n n = 616 fun() print(n)
(二).nonlocal
当里层局部,需要修改局部外层时,用nonlocal修饰。在嵌套函数中会用到。
def outer(): num = 10 def inner(): nonlocal num # nonlocal关键字声明 # 不声明依旧是这个报错:UnboundLocalError: local variable 'num' referenced before assignment num = 100 print(num) inner() # 不调用是不会执行的 // 必须写在这里,不然未定义报错,因为函数必须先声明后使用 print(num) outer() # 运行结果:100 100
(三).总结
(1).外部不能访问函数内部的变量。
(2).函数内部能够访问函数外部的变量。
(3).函数里部不能修改函数外部的变量。
(四).作用域链
从内向外,依次去寻找变量。
在函数定义的时候,作用域链其实就已经形成了。
(五).练习
(1).练习1,选哪个?
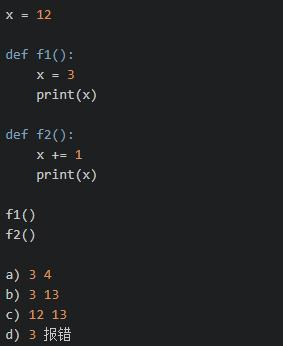
选d,变量的作用域概念。模块中x是全局变量,函数中的x是局部变量,变量的查找顺序是LEGB(L的级别最高)
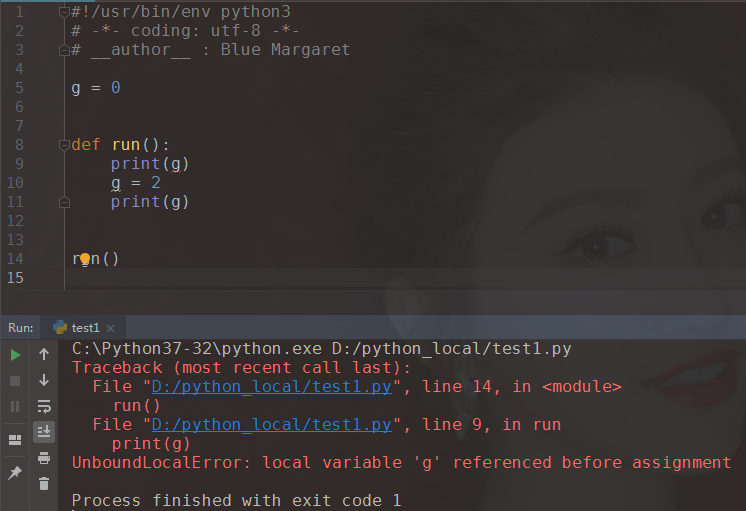
(2).练习2,为什么报错?
函数内部的变量名第一次出现,而且出现在等号前面,即被视为定义一个局部变量,不管全局域中有没有用到该变量名,函数中使用的将是局部变量。
把g=2放到函数内的第一行,那么g就是一个局部变量,整个函数内就会使用这个局部变量,变量在使用前被声明,就不会报错了。
其实,归根到底就是因为作用域的级别问题。L的级别最高,当有了L的时候,就会优先使用L。g的声明在第9行之后,在声明前就使用,必然会引起报错。
四、Python变量作用域的四个级别
BGEL,作用域的级别依次升高,级别最高的是Local,如果该变量在Local中已经声明并赋值,将优先使用Local中的变量对应的值。
(一).B:build-in 系统固定模块里面的变量,也叫系统变量,比如int,这些变量可以通过builtins模块获取。
builtins模块里面的这些函数和类等内容构成了内置作用域。这些函数和类可以直接使用,Python会从这里找到他们。
(二).G:global 全局变量,在单个程序文件里面都可用,它位于文件代码的顶级。
(三).E:enclosing 嵌套的父级函数的局部作用域,就是包含此函数的上层函数的局部作用域。
E和L是相对的,E中的变量相对上层来说也是L。E嵌套作用域,在local中取值,但是local中没有,就会去E里面找。
例1:
g = 0 def run(): g = 2 def run2(): print(g) return run2 f = run() f() # 打印结果:2
run函数内嵌套了函数run2,run2内使用变量g,但是run2里面没有,所以它从内向外找,就找到了run的作用域。
注意run函数的最后一句,它返回了run2这个函数,f=run(),就是把run2函数赋值给f,f()就是执行了run2函数,但是可以访问run函数的作用域。
(四).L:local 局部作用域,即为函数中定义的变量。
(五).案例
(1).例1
阅读代码,写出运行结果
g = 0 def run(): def run2(): g = 1 print(g) print(g) return run2 f = run() f()
结果为:0 1(先打印出0,再打印出1)
分析:
首先,return语句与第一层函数中的print(g)属于同层语句,return在print之后,所以先执行第一层函数中的print(g)这条语句。
根据作用域级别来对待,第一层函数的print语句并不在嵌套函数run2中,所以不存在L和E级别的说法,但是变量g出现在了G级别中,所以会去使用全局变量,此时全局变量g=0,所以0是第一个被打印出来。
接下来,内嵌函数run2中有了L级别的变量g,此时会根据作用域级别的约定,优先使用L级别中的变量。而f()相当于执行了run2函数,理所当然会打印出1。
五、回调函数
def test1(): print("111") def fun2(a): a() print("222") # 后面调用前面 fun2(test1) # 把函数体当作参数传过去
六、闭包
首先,闭包需要是嵌套函数。调用外层,返回里层的函数体(外层函数返回里层函数)
通俗地讲:闭包是函数里面嵌套函数,外层函数返回里层函数,这种情况称之为闭包。闭包能够维持住这个变量。
简单来说,闭包有这么3个作用:
(1).构造局部的全局变量。
(2).在没有类的情况下,封装变量。
(3).实现装饰器的基础
(一).一个简单的闭包实例
def fun1(): a = 1 print(a) def fun2(): # 封闭在函数里面 b = 2 print(b) return fun2 # 加了括号()是调用。不加括号"()",返回函数体 print(fun1()) """ 运行结果: 1 <function fun1.<locals>.fun2 at 0x0067D6F0> """
(二).Python闭包的延迟绑定
(1).问题引入
以下这段代码运行后,将会打印出什么结果?
def multipliers(): return [lambda x: i * x for i in range(4)] print([m(2) for m in multipliers()]) # [6, 6, 6, 6]
结果是四个6,为什么不是正常理解中的[0,2,4,6]?
(2).原因分析
原因是Python闭包的延迟绑定。内部函数被调用时,参数的值在闭包内进行查找。
当任何由multipliers()返回的函数被调用时,i的值将在附近的范围进行查找,是在内部函数被调用时查询得到的。那时,不管返回的函数是否被调用,for循环已经完成,i被赋予了最终的值3。
因此,每次返回的函数乘以传递过来的值3,因为上段代码传过来的值是2,它们最终返回的都是6(3*2)。
lambda表达式创造的函和def创造的函数是一样的。
将上段代码拆开来写,等价于:
def multipliers(): l1 = [] for i in range(4): def _inner(x): return i * x l1.append(_inner) return l1
这个问题说白了,就是Python的设定而已,Python就是这么设定的。那么在使用中,就需要避开这个坑。
以下的三个解决方案均可有效避开这个问题:
(3).解决方案1
利用生成器(个人认为是最简单最好理解的方式)
def multipliers(): for i in range(4): def inner(x): return i * x yield inner
当一个函数中出现了yield关键词,那么这个函数就变成了一个生成器,生成器的特性:暂停、返回信息、记住当前函数运行的所有信息。
当第一次yield,返回函数体的时候,i是0,0*2=0,所以第一个结果是0,此时函数是处于暂停状态,而且生成器记住了当前函数运行的所有信息。
当再次去操作生成器的时候,生成器会从上次的暂停处继续运行下去。由于生成器记住了函数运行的所有信息,那么它肯定会去取出range对象中的第二个元素,也就是i=1,1*2=2,
以此类推,最后的结果就是:[0, 2, 4, 6]
可以简写成:
def create_multipliers(): for i in range(4): yield lambda x: x * i
也可以是以圆括号表现的推导式:
def create_multipliers(): return (lambda x: x * i for i in range(4))
(4).解决方案2
利用默认函数立即绑定
def multipliers(): return [lambda x, i=i: i * x for i in range(4)]
拆开来写,等价于:
def multipliers(): l1 = [] for i in range(4): def inner(x, i=i): return x * i l1.append(inner) return l1
对比问题引入那段代码来看,其实就相当于给定了里层函数一个默认值,立即赋值,不让闭包再去外层找变量。
(5).解决方案3
偏函数
from functools import partial from operator import mul def multipliers(): return [partial(mul, i) for i in range(4)] print([m(2) for m in multipliers()])
(6).补充
闭包+回调函数+语法糖=装饰器
七、递归
递归的特点:
(1).自己调用自己。
(2).必须要有一个出口!
# 示例:5的阶乘 # 5! = 5*4*3*2*1 def jiec(n): if n == 1: return 1 # 如果把1写成0,结果就是0了。因为最后一个数乘以了0 else: return jiec(n - 1) * n print(jiec(5))
八、补充内容
可变的数据类型,可以在函数里面,直接进行修改:
li = [1, 2, 3] tu = ("a", "b", "c") def test(li, tu): # 元组不可变,所以tu不能直接修改 # 而li就可以在函数中直接修改 li.append("python") test(li, tu) print(li) # 原来的li被修改了 print(tu) """ 远行结果: [1, 2, 3, 'python'] ('a', 'b', 'c') """
好处:在函数中修改了,无需重新赋值,就会改变。
坏处:当不想改变原数据时,显得略坑,需要提前copy()一份。
可变的对象都有copy()这个方法。
小练习:
(1).定义一个函数,输入一个序列(序列元素是同种类型),判断序列是顺序还是逆序,顺序输出"UP",逆序输出"DOWN",乱序否则输出"None"
import re
def is_up_down_none(list_value): up = sorted(list_value) # 顺序排序 down = sorted(list_value, reverse=True) # 倒序排序 if list_value == up: # 原列表与up比较 print("顺序的,UP") # 一样的话肯定是顺序的 elif list_value == down: # 原列表与down比较 print("倒序的,DOWN") # 一样的话肯定是倒序的 else: print("乱序的,None")
while 1: strings = input("请输入内容:") list_value = list(re.findall("[a-zA-Z0-9]", strings)) # 用正则提取出每个元素,因为比较的是列表 is_up_down_none(list_value)
(2).写一个函数,对列表li = [9,8,3,2,6,4,5,7,1],进行从小到大的排序。最后返回li
# 使用内置函数:sorted() def sorting(li1): return sorted(li1) li1 = [9, 8, 3, 2, 6, 4, 5, 7, 1] g = sorting(li1) print(g)
使用冒泡排序法:
def bubbling(li1): for i in range(len(li1)): # list的下标是从0开始的,range()左闭右开,取不到最后一个数值,刚好不会造成列表index溢出 for j in range(i): # 只需比较8次就可以了,因为最后一次肯定是最小值在前面了 if li1[i] < li1[j]: li1[i], li1[j] = li1[j], li1[i] print(li1) li1 = [9, 8, 3, 2, 6, 4, 5, 7, 1] bubbling(li1) """ 每个数字都与其他的做比较,然后进行交换。 外面一层循环即是控制比较几次,也是确定当前的下标, 里面一层循环控制每个数字都与外面的那个下表进行对比。 """