实验一、词法分析实验
专业 :商业软件工程 姓名:林江绅 学号:201506110119
一、 实验目的
设计并实现C语言的词法分析程序。
二、 实验内容和要求
编写一个词法分析程序,对某源程序文件进行词法分析,将其中的所有单词经词法分析后变为由类号构成的目标文件。要求如下:
(1) 可以识别出用C语言编写的源程序中的每个单词符号,并以记号的形式输出每个单词符号。
(2) 可以识别并读取源程序中的注释。
(3) 可以统计源程序中的语句行数、单词个数和字符个数,其中标点和空格不计算为单词,并输出统计结果。
(4) 检查源程序中存在的非法字符错误,并可以报告错误所在的行列位置。
(5) 发现源程序中存在错误后,进行适当的恢复,使词法分析可以继续进行,通过一次词法分析处理,可以检查并报告源程序中存在的所有词法拼写错误。
三、 实验方法、步骤及结果测试
1. 源程序名: cifafenxi.c
可执行程序名:cifafenxi.exe
2. 原理分析及流程图
(一)待分析的简单的词法
(1)关键字:
begin if then while do end 所有的关键字都是小写。
(2)运算符和界符
:= + - * / < <= <> > >= = ; ( ) #
(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:
ID = letter (letter | digit)* NUM = digit digit*
(4)空格有空白、制表符和换行符组成。空格一般用来分隔
ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略.
(二)词法分析程序的功能:
输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;
token为存放的单词自身字符串;
sum为整型常数
3. 主要程序段及其解释:
#include <stdio.h> #include <string.h> char prog[80],token[8],ch; int syn,p,m,n,sum; char *rwtab[6]={"begin","if","then","while","do","end"}; scaner(); main() {p=0; printf("\n please input a string(end with '#'):"); do{ scanf("%c",&ch); prog[p++]=ch; }while(ch!='#'); p=0; do{ scaner(); switch(syn) {case 11:printf("( %-10d%5d )\n",sum,syn); break; case -1:printf("you have input a wrong string\n"); default: printf("( %-10s%5d )\n",token,syn); break; } }while(syn!=0); } scaner() { sum=0; for(m=0;m<8;m++)token[m++]=NULL; ch=prog[p++]; m=0; while((ch==' ')||(ch=='\n'))ch=prog[p++]; if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))) { while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch; ch=prog[p++]; } p--; syn=10; for(n=0;n<6;n++) if(strcmp(token,rwtab[n])==0) { syn=n+1; break; } } else if((ch>='0')&&(ch<='9')) { while((ch>='0')&&(ch<='9')) { sum=sum*10+ch-'0'; ch=prog[p++]; } p--; syn=11; } else switch(ch) { case '<':token[m++]=ch; ch=prog[p++]; if(ch=='=') { syn=22; token[m++]=ch; } else { syn=20; p--; } break; case '>':token[m++]=ch; ch=prog[p++]; if(ch=='=') { syn=24; token[m++]=ch; } else { syn=23; p--; } break; case '+': token[m++]=ch; ch=prog[p++]; if(ch=='+') { syn=17; token[m++]=ch; } else { syn=13; p--; } break; case '-':token[m++]=ch; ch=prog[p++]; if(ch=='-') { syn=29; token[m++]=ch; } else { syn=14; p--; } break; case '!':ch=prog[p++]; if(ch=='=') { syn=21; token[m++]=ch; } else { syn=31; p--; } break; case '=':token[m++]=ch; ch=prog[p++]; if(ch=='=') { syn=25; token[m++]=ch; } else { syn=18; p--; } break; case '*': syn=15; token[m++]=ch; break; case '/': syn=16; token[m++]=ch; break; case '(': syn=27; token[m++]=ch; break; case ')': syn=28; token[m++]=ch; break; case '{': syn=5; token[m++]=ch; break; case '}': syn=6; token[m++]=ch; break; case ';': syn=26; token[m++]=ch; break; case '\"': syn=30; token[m++]=ch; break; case '#': syn=0; token[m++]=ch; break; case ':':syn=17; token[m++]=ch; break; default: syn=-1; break; } token[m++]='\0'; }
4. 运行结果及分析
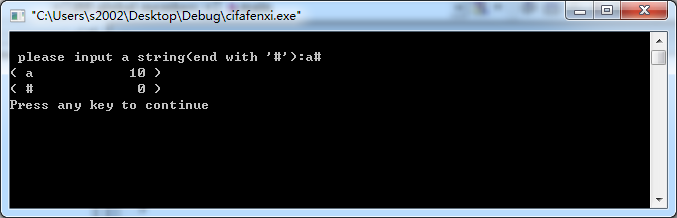
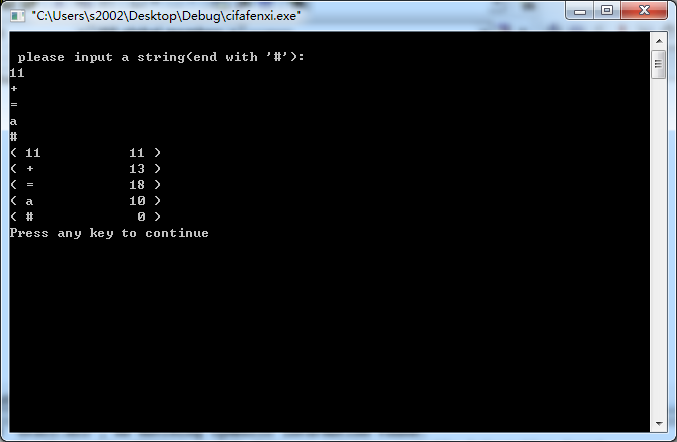
|
单词符号 |
种别码 |
单词符号 |
种别码 |
|
begin |
1 |
: |
17 |
|
if |
2 |
:= |
18 |
|
then |
3 |
< |
20 |
|
while |
4 |
<= |
21 |
|
do |
5 |
<> |
22 |
|
end |
6 |
> |
23 |
|
l(l|d)* |
10 |
>= |
24 |
|
dd* |
11 |
= |
25 |
|
+ |
13 |
; |
26 |
|
- |
14 |
( |
27 |
|
* |
15 |
) |
28 |
|
/ |
16 |
# |
0 |
四、 实验总结
在一开始接触这个实验时,觉得是个庞大的工程,因为里面涉及到算法分析,原理分析,感觉有点不熟悉。在做实验的过程中也遇到许多不懂的地方,通过询问同学和网上查阅,大的问题算是解决了,但还有一些小问题的存在,比如说,程序的简化美化,多种符号的设计等等。通过这个实验,让我进一步地了解编译原理这这门课程,需要不断的练习,从实践中发现自己不足的地方,查落补缺,反复改进,才能有更大的收获。