Kubernetes集群搭建
准备4台虚拟机,以二进制方式,通过ansible脚本,自动化搭建一个多主多节点的高可用集群。
Ansible脚本安装kubernetes集群:https://github.com/gjmzj/kubeasz
kubernetes官方github地址:https://github.com/kubernetes/kubernetes/releases
环境准备
软硬件限制:
1. CPU和内存 master:至少1c2g,推荐2c4g;node:至少1c2g
2. linux系统 内核版本3.10以上,推荐CentOS7或RHEL7
3. docker 至少1.9版本,推荐1.12+
4. etcd 至少2.0版本,推荐3.0+
节点规划:
deploy节点---数量1:运行这份ansible脚本的节点
etcd节点---数量3:注意etcd集群必须是1,3,5,7...奇数个节点
master节点---数量2:根据实际集群规模可以增加节点数,需要额外规划一个master VIP
lb节点---数量2:负载均衡节点2个,安装haproxy和keepalived
node节点---数量3:真正应用负载的节点,根据需要提升机器配置和增加节点数
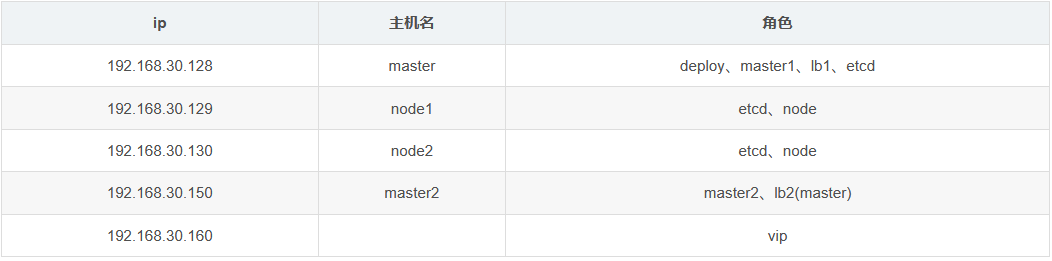
机器规划:
准备工作:
4台机器,全部执行
# yum install -y epel-release
# yum update -y
# yum install -y python
开始安装
deploy节点安装和准备ansible:
[root@master ~]# yum install git python-pip -y
[root@master ~]# pip install pip --upgrade -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
[root@master ~]# pip install --no-cache-dir ansible -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
deploy节点配置免密码登录:
[root@master ~]# ssh-keygen
[root@master ~]# for ip in 128 129 130 150 ; do ssh-copy-id 192.168.30.$ip; done
[root@master ~]# for ip in 128 129 130 150 ; do ssh 192.168.30.$ip; done #登录验证
deploy节点上编排k8s:
[root@master ~]# git clone https://github.com/gjmzj/kubeasz.git
[root@master ~]# mkdir -p /etc/ansible
[root@master ~]# mv kubeasz/* /etc/ansible/
- 下载二进制文件:
地址:百度云链接,根据自己所需版本,下载对应的tar包,下载解压到/etc/ansible/bin目录。这里我下载1.11版本。
[root@master ~]# tar zxf k8s.1-11-6.tar.gz
[root@master ~]# mv bin/* /etc/ansible/bin/
配置集群参数:
[root@master ~]# cd /etc/ansible && cp example/hosts.m-masters.example hosts
[root@master ansible]# vim hosts #根据实际情况修改
[root@master ansible]# ansible all -m ping #验证是否节点正常
192.168.30.150 | SUCCESS => {
"changed": false,
"ping": "pong"
}
192.168.30.129 | SUCCESS => {
"changed": false,
"ping": "pong"
}
192.168.30.130 | SUCCESS => {
"changed": false,
"ping": "pong"
}
192.168.30.128 | SUCCESS => {
"changed": false,
"ping": "pong"
}
创建证书和安装准备:
[root@master ansible]# ansible-playbook 02.etcd.yml
[root@master ansible]# bash #如果提示etcdctl命令不存在则执行该步
[root@master ansible]# for ip in 128 129 130; do
ETCDCTL_API=3 etcdctl \
--endpoints=https://192.168.30.$ip:2379 \
--cacert=/etc/kubernetes/ssl/ca.pem \
--cert=/etc/etcd/ssl/etcd.pem \
--key=/etc/etcd/ssl/etcd-key.pem \
endpoint health; done #验证集群状态
预期结果:
https://192.168.30.128:2379 is healthy: successfully committed proposal: took = 3.376468ms
https://192.168.30.129:2379 is healthy: successfully committed proposal: took = 2.518545ms
https://192.168.30.130:2379 is healthy: successfully committed proposal: took = 3.091893ms
安装docker:
[root@master ansible]# ansible-playbook 03.docker.yml
安装master节点:
[root@master ansible]# ansible-playbook 04.kube-master.yml
安装node节点:
[root@master ansible]# ansible-playbook 05.kube-node.yml
查看node节点
[root@master ansible]# kubectl get node
NAME STATUS ROLES AGE VERSION
192.168.30.129 Ready node 28s v1.11.6
192.168.30.130 Ready node 39s v1.11.6
192.168.30.128 Ready,SchedulingDisabled master 4m v1.11.6
192.168.30.150 Ready,SchedulingDisabled master 4m v1.11.6
部署集群网络:
[root@master ansible]# ansible-playbook 06.network.yml
查看是否有flannel相关的pod
[root@master ansible]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-amd64-5dfgb 1/1 Running 0 1m
kube-flannel-ds-amd64-6w22r 1/1 Running 0 1m
kube-flannel-ds-amd64-bn6xl 1/1 Running 0 1m
kube-flannel-ds-amd64-chg9q 1/1 Running 0 1m
安装集群相关的插件(dns、dashboard):
[root@master ansible]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.68.0.2 <none> 53/UDP,53/TCP,9153/TCP 1m
kubernetes-dashboard NodePort 10.68.235.201 <none> 443:38679/TCP 1m
metrics-server ClusterIP 10.68.241.153 <none> 443/TCP 1m
一步安装:
上面是分步骤安装的,如果不想这么麻烦,可以一步安装。
# ansible-playbook 90.setup.yml
查看集群信息:
[root@master ansible]# kubectl cluster-info
Kubernetes master is running at https://192.168.30.160:8443
CoreDNS is running at https://192.168.30.160:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
kubernetes-dashboard is running at https://192.168.30.160:8443/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy
查看node/pod使用资源情况:
[root@master ansible]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
192.168.30.129 95m 2% 1136Mi 5%
192.168.30.130 92m 2% 1569Mi 9%
192.168.30.128 174m 4% 2868Mi 14%
192.168.30.150 121m 3% 1599Mi 8%
[root@master ansible]# kubectl top pod --all-namespaces
NAMESPACE NAME CPU(cores) MEMORY(bytes)
kube-system coredns-695f96dcd5-7rsl5 5m 13Mi
kube-system coredns-695f96dcd5-v5zkg 5m 13Mi
kube-system kube-flannel-ds-amd64-5dfgb 4m 14Mi
kube-system kube-flannel-ds-amd64-6w22r 3m 12Mi
kube-system kube-flannel-ds-amd64-bn6xl 4m 13Mi
kube-system kube-flannel-ds-amd64-chg9q 4m 15Mi
kube-system kubernetes-dashboard-68bf55748d-qmgrh 1m 12Mi
kube-system metrics-server-75df6ff86f-qf56f 2m 14Mi
测试DNS
创建nginx service:
[root@master ansible]# kubectl run nginx --image=nginx --expose --port=80 # --export 暴露一个端口
service/nginx created
deployment.apps/nginx created
[root@master ansible]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 35m
nginx ClusterIP 10.68.185.11 <none> 80/TCP 2s
[root@master ansible]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-6f858d4d45-tfnhv 1/1 Running 0 27s
创建busybox,测试pod:
[root@master ansible]# kubectl run busybox --rm -it --image=busybox sh # --rm 退出时删除容器
/ # nslookup nginx.default.svc.cluster.local
Server: 10.68.0.2
Address: 10.68.0.2:53
*** Can't find nginx.default.svc.cluster.local: No answer
master2上面查看
[root@master2 ~]# kubectl get svc --all-namespaces
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 52m
default nginx ClusterIP 10.68.185.11 <none> 80/TCP 17m
kube-system kube-dns ClusterIP 10.68.0.2 <none> 53/UDP,53/TCP,9153/TCP 38m
kube-system kubernetes-dashboard NodePort 10.68.235.201 <none> 443:38679/TCP 38m
kube-system metrics-server ClusterIP 10.68.241.153 <none> 443/TCP 38m
这里dns service的cluster ip就是刚刚查到的server ip 。
增加node节点
deploy节点免密码登录node:
# ssh-copy-id 新nodeip
修改hosts:
# vim /etc/ansible/hosts
[new-node]
新nodeip
执行安装脚本:
# ansible-playbook /etc/ansible/20.addnode.yml
验证:
# kubectl get node
# kubectl get pod -n kube-system -o wide
修改/etc/ansible/hosts,将[new-node]中的ip移到[kube-node]中。
增加master节点与增加node节点类似,此处省略。
升级集群
备份etcd:
# ETCDCTL_API=3 etcdctl snapshot save backup.db
查看备份文件信息
# ETCDCTL_API=3 etcdctl --write-out=table snapshot status backup.db
拉取新的代码:
# cd kubeasz/ #到本项目的根目录kubeasz
# git pull origin master
- 下载升级目标版本的kubernetes二进制包:
百度网盘地址:https://pan.baidu.com/s/1c4RFaA#list/path=%2FK8S
解压并替换/etc/ansible/bin/下的二进制文件。
- docker升级(略):
除非特别需要,否则不建议升级docker 。
如果业务可以中断:
# ansible-playbook -t upgrade_k8s,restart_dockerd 22.upgrade.yml
如果业务不能中断:
# ansible-playbook -t upgrade_k8s 22.upgrade.yml
到所有node上逐一操作
# kubectl cordon;kubectl drain #迁移业务pod
# systemctl restart docker
# kubectl uncordon #恢复pod
集群备份和恢复
备份:
备份,从运行的etcd集群中备份数据到磁盘文件。
恢复:
恢复,把etcd的备份文件恢复到etcd集群中,然后据此恢复整个集群。
另外:
另外,如果是使用kubeasz项目创建的集群,除了备份etcd数据外,还需要备份CA证书文件,以及ansible的hosts文件。
操作步骤
查看pod:
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-6f858d4d45-tfnhv 1/1 Running 0 18h
创建备份目录:
[root@master ~]# mkdir -p /backup/k8s
备份etcd数据:
[root@master ~]# ETCDCTL_API=3 etcdctl snapshot save /backup/k8s/snapshot.db
Snapshot saved at /backup/k8s/snapshot.db
备份ca证书:
[root@master ~]# cp /etc/kubernetes/ssl/ca* /backup/k8s/
[root@master ~]# cp -r /backup/ /backup1/ #这一步不要省略,多备份一份
模拟集群崩溃:
[root@master ~]# ansible-playbook /etc/ansible/99.clean.yml
恢复CA证书:
[root@master ~]# cp -r /backup1/k8s/ /backup/
[root@master ~]# mkdir -p /etc/kubernetes/ssl
[root@master ~]# cp /backup/k8s/ca* /etc/kubernetes/ssl/
重建集群:
[root@master ~]# cd /etc/ansible/
[root@master ansible]# ansible-playbook 01.prepare.yml
[root@master ansible]# ansible-playbook 02.etcd.yml
[root@master ansible]# ansible-playbook 03.docker.yml
[root@master ansible]# ansible-playbook 04.kube-master.yml
[root@master ansible]# ansible-playbook 05.kube-node.yml
检查集群状态:
[root@master ansible]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 1h
[root@master ansible]# kubectl cluster-info
Kubernetes master is running at https://192.168.30.150:8443
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
[root@master ansible]# for ip in 128 129 130; do ETCDCTL_API=3 etcdctl --endpoints=https://192.168.30.$ip:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/etcd/ssl/etcd.pem --key=/etc/etcd/ssl/etcd-key.pem endpoint health; done
https://192.168.30.128:2379 is healthy: successfully committed proposal: took = 2.147777ms
https://192.168.30.129:2379 is healthy: successfully committed proposal: took = 3.092867ms
https://192.168.30.130:2379 is healthy: successfully committed proposal: took = 2.992882ms
[root@master ansible]# kubectl get componentstatus
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
恢复etcd数据:
停止服务
[root@master ansible]# ansible etcd -m service -a 'name=etcd state=stopped'
清空文件
[root@master ansible]# ansible etcd -m file -a 'name=/var/lib/etcd/member state=absent'
登录所有的etcd节点,参考本etcd节点/etc/systemd/system/etcd.service服务文件,执行
[root@master k8s]# ETCDCTL_API=3 etcdctl snapshot restore snapshot.db --name etcd1 --initial-cluster etcd1=https://192.168.30.128:2380,etcd2=https://192.168.30.129:2380,etcd3=https://192.168.30.130:2380 --initial-cluster-token etcd-cluster-0 --initial-advertise-peer-urls https://192.168.30.128:2380
[root@master k8s]# cp -r etcd1.etcd/member/ /var/lib/etcd/
[root@master k8s]# systemctl restart etcd
[root@master k8s]# rsync -av /backup/ 192.168.30.129:/backup/
[root@node1 ~]# cd /backup/k8s/ # node1节点上执行
[root@node1 k8s]# ETCDCTL_API=3 etcdctl snapshot restore snapshot.db --name etcd2 --initial-cluster etcd1=https://192.168.30.128:2380,etcd2=https://192.168.30.129:2380,etcd3=https://192.168.30.130:2380 --initial-cluster-token etcd-cluster-0 --initial-advertise-peer-urls https://192.168.30.129:2380
[root@node1 k8s]# cp -r etcd2.etcd/member/ /var/lib/etcd/
[root@node1 k8s]# systemctl restart etcd
[root@master k8s]# rsync -av /backup/ 192.168.30.130:/backup/
[root@node2 ~]# cd /backup/k8s/ # node2节点上执行
[root@node2 k8s]# ETCDCTL_API=3 etcdctl snapshot restore snapshot.db --name etcd3 --initial-cluster etcd1=https://192.168.30.128:2380,etcd2=https://192.168.30.129:2380,etcd3=https://192.168.30.130:2380 --initial-cluster-token etcd-cluster-0 --initial-advertise-peer-urls https://192.168.30.130:2380
[root@node2 k8s]# cp -r etcd3.etcd/member/ /var/lib/etcd/
[root@node2 k8s]# systemctl restart etcd
再次检查集群状态:
[root@master k8s]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 21h
nginx ClusterIP 10.68.185.11 <none> 80/TCP 21h
[root@master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-6f858d4d45-tfnhv 1/1 Running 0 21h
[root@master k8s]# kubectl get svc --all-namespaces
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 21h
default nginx ClusterIP 10.68.185.11 <none> 80/TCP 21h
kube-system kube-dns ClusterIP 10.68.0.2 <none> 53/UDP,53/TCP,9153/TCP 21h
kube-system kubernetes-dashboard NodePort 10.68.235.201 <none> 443:38679/TCP 21h
kube-system metrics-server ClusterIP 10.68.241.153 <none> 443/TCP 21h
service和pod以及dns等都已经恢复回来。
重建网络:
[root@master k8s]# ansible-playbook /etc/ansible/tools/change_k8s_network.yml
一键备份和恢复
如果不想手动恢复,可以选择这样。
- 一键备份:
# ansible-playbook /etc/ansible/23.backup.yml
检查文件:
# tree /etc/ansible/roles/cluster-backup/files/ #如下
/etc/ansible/roles/cluster-backup/files/
├── ca #集群CA相关备份
│ ├── ca-config.json
│ ├── ca.csr
│ ├── ca-csr.json
│ ├── ca-key.pem
│ └── ca.pem
├── hosts # ansible hosts备份
│ ├── hosts #最近的备份
│ └── hosts-201902201420
├── readme.md
└── snapshot # etcd数据备份
├── snapshot-201902201420.db
└── snapshot.db #最近的备份
模拟故障:
# ansible-playbook /etc/ansible/99.clean.yml
修改文件:
修改文件/etc/ansible/roles/cluster-restore/defaults/main.yml,指定要恢复的etcd快照备份,如果不修改就是最近一次。
一键恢复:
# ansible-playbook /etc/ansible/24.restore.yml
# ansible-playbook /etc/ansible/tools/change_k8s_network.yml
更多参考资料:
https://blog.frognew.com/2018/08/kubeadm-install-kubernetes-1.11.html#32-%E4%BD%BF%E7%94%A8helm%E9%83%A8%E7%BD%B2nginx-ingress