PCM数据格式
1. 音频简介
经常见到这样的描述: 44100HZ 16bit stereo 或者 22050HZ 8bit mono 等等.
44100HZ 16bit stereo: 每秒钟有 44100 次采样, 采样数据用 16 位(2字节)记录, 双声道(立体声);
22050HZ 8bit mono: 每秒钟有 22050 次采样, 采样数据用 8 位(1字节)记录, 单声道;
当然也可以有 16bit 的单声道或 8bit 的立体声, 等等。
采样率是指:声音信号在“模→数”转换过程中单位时间内采样的次数。采样值是指每一次采样周期内声音模拟信号的积分值。
对于单声道声音文件,采样数据为八位的短整数(short int 00H-FFH);
而对于双声道立体声声音文件,每次采样数据为一个16位的整数(int),高八位(左声道)和低八位(右声道)分别代表两个声道。
人对频率的识别范围是 20HZ - 20000HZ, 如果每秒钟能对声音做 20000 个采样, 回放时就足可以满足人耳的需求. 所以 22050 的采样频率是常用的, 44100已是CD音质, 超过48000的采样对人耳已经没有意义。这和电影的每秒 24 帧图片的道理差不多。
每个采样数据记录的是振幅, 采样精度取决于储存空间的大小:
1 字节(也就是8bit) 只能记录 256 个数, 也就是只能将振幅划分成 256 个等级;
2 字节(也就是16bit) 可以细到 65536 个数, 这已是 CD 标准了;
4 字节(也就是32bit) 能把振幅细分到 4294967296 个等级, 实在是没必要了.
如果是双声道(stereo), 采样就是双份的, 文件也差不多要大一倍.
这样我们就可以根据一个 wav 文件的大小、采样频率和采样大小估算出一个 wav 文件的播放长度。
譬如 "Windows XP 启动.wav" 的文件长度是 424,644 字节, 它是 "22050HZ / 16bit / 立体声" 格式(这可以从其 "属性->摘要" 里看到),
那么它的每秒的传输速率(位速, 也叫比特率、取样率)是 22050*16*2 = 705600(bit/s), 换算成字节单位就是 705600/8 = 88200(字节/秒),
播放时间:424644(总字节数) / 88200(每秒字节数) ≈ 4.8145578(秒)。
但是这还不够精确, 包装标准的 PCM 格式的 WAVE 文件(*.wav)中至少带有 42 个字节的头信息, 在计算播放时间时应该将其去掉,
所以就有:(424644-42) / (22050*16*2/8) ≈ 4.8140816(秒). 这样就比较精确了.
关于声音文件还有一个概念: "位速", 也有叫做比特率、取样率, 譬如上面文件的位速是 705.6kbps 或 705600bps, 其中的 b 是 bit, ps 是每秒的意思;
压缩的音频文件常常用位速来表示, 譬如达到 CD 音质的 MP3 是: 128kbps / 44100HZ.
2. PCM数据格式
PCM(Pulse Code Modulation)也被称为 脉码编码调制。PCM中的声音数据没有被压缩,如果是单声道的文件,采样数据按时间的先后顺序依次存入。(它的基本组织单位是BYTE(8bit)或WORD(16bit))
一般情况下,一帧PCM是由2048次采样组成的( 参 http://discussion.forum.nokia.com/forum/showthread.php?129458-请问PCM格式的音频流,每次读入或输出的块的大小是必须固定为4096B么&s=e79e9dd1707157281e3725a163844c49 )。
如果是双声道的文件,采样数据按时间先后顺序交叉地存入。如图所示:
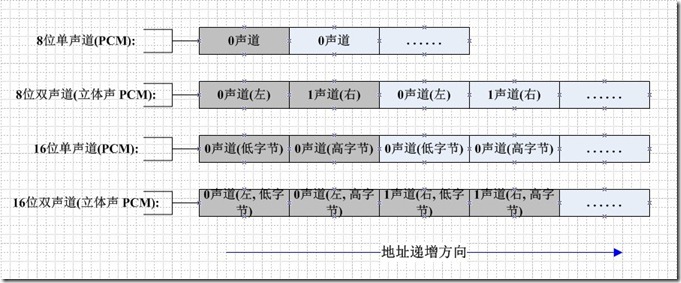
PCM的每个样本值包含在一个整数i中,i的长度为容纳指定样本长度所需的最小字节数。
首先存储低有效字节,表示样本幅度的位放在i的高有效位上,剩下的位置为0,这样8位和16位的PCM波形样本的数据格式如下所示。
样本大小 数据格式 最小值 最大值
8位PCM unsigned int 0 225
16位PCM int -32767 32767
=================================================================
转自: http://www.itgrass.com/a/cjj/C-jq/200812/06-9686.html
将PCM数据转换成WAV文件
1 perl脚本 在北大中文论坛看到一位网友问起怎样把大尾的PCM数据播放出来。我以前在工作中碰到过8K采样的PCM数据,当时不清楚wav文件的格式,正好perl模块中有个Audio::Wav模块可以写wav文件,就写了个perl脚本:
use Audio::Wav;
my $wav = new Audio::Wav;
my $sample_rate = 8000; my $bits_sample = 16;
my $details = { 'bits_sample' => $bits_sample, 'sample_rate' => $sample_rate, 'channels' => 1, };
my $write = $wav -> write( 'testout.wav', $details );
my $inputFile = "dout.txt"; open (INFILE, "<$inputFile") or die "The file $inputFile ". "could not be opened./n"; my @pcm_data = ; close(INFILE);
my $samp; foreach $samp(@pcm_data) { chomp($samp); $write -> write( $samp ); }
$write -> finish(); 这几行脚本就可以把PCM数据转换到wav文件。后来我看过wav文件格式,觉得很简单,这次又看到网友提到这个问题,就抽空写了个小程序。
2 pcm2wav 将PCM数据转换成WAV文件其实只是加个文件头。但要做给普通用户用,界面比较费时间。我找了一个以前写的html2txt工程修改一下,花了半个晚上和一个中午,完成了这个pcm2wav程序。
3 实现原理
网上有一篇曹京写的《wav文件格式分析详解》已经介绍过wav文件格式,有兴趣的读者可以查阅。wav文件通常包含4段:RIFF、格式段、FACT段 和数据段。 PCM数据就放在数据段。只要格式段设置的格式与数据段的数据一致,播放程序就可以正确解析。下面这个数组的数据其实就是一个最小的wav文件。
static const unsigned char wav_template[] = { // RIFF WAVE Chunk 0x52, 0x49, 0x46, 0x46, // "RIFF" 0x30, 0x00, 0x00, 0x00, // 总长度 整个wav文件大小减去ID和Size所占用的字节数 0x57, 0x41, 0x56, 0x45, // "WAVE"
// Format Chunk 0x66, 0x6D, 0x74, 0x20, // "fmt " 0x10, 0x00, 0x00, 0x00, // 块长度 0x01, 0x00, // 编码方式 wFormatTag 0x01, 0x00, // 声道数目 wChannels 0x80, 0x3E, 0x00, 0x00, // 采样频率 dwSamplesPerSec 0x00, 0x7D, 0x00, 0x00, // 每秒所需字节数 dwAvgBytesPerSec 0x02, 0x00, // 每个样本需要的字节数 wBlockAlign 0x10, 0x00, // 每个样本需要的位数 wBitsPerSample
// Fact Chunk 0x66, 0x61, 0x63, 0x74, // "fact" 0x04, 0x00, 0x00, 0x00, // 块长度 0x00, 0xBE, 0x00, 0x00,
// Data Chunk 0x64, 0x61, 0x74, 0x61, // "data" 0x00, 0x00, 0x00, 0x00, // 块长度 };
这个wav文件的数据长度为0。我们要增加PCM数据只要完成以下工作:
在数据段尾增加PCM数据; 修改数据段的块长度,修改RIFF段的总长度; 正确设置格式段的PCM参数。 样本长度可能不是8的整数倍,这时wav文件还是要求样本按照字节对齐。在一个样本中数据是左对齐的,右侧空位用0填充。 pcm2wav只考虑了样本长度是16位的情况。
如果有多个声道,wav文件要求先放样本1的各声道数据,再放样本2的各声道数据,依此类推。因为我没有碰到过处理多声道数据的需求,所以pcm2wav只考虑了单声道。
==========================================================
http://blog.csdn.net/jifengszf/article/details/4261058
完整正确的wav文件格式分析详解
作者:曹京
日期:2006年7月17日
一、综述
WAVE文件作为多媒体中使用的声波文件格式之一,它是以RIFF格式为标准的。
RIFF是英文Resource Interchange File Format的缩写,每个WAVE文件的头四个
字节便是“RIFF”。
WAVE文件是由若干个Chunk组成的。按照在文件中的出现位置包括:RIFF WAVE
Chunk, Format Chunk, Fact Chunk(可选), Data Chunk。具体见下图:
------------------------------------------------
| RIFF
WAVE
Chunk
|
| ID = 'RIFF' |
| RiffType = 'WAVE' |
------------------------------------------------
| Format Chunk |
| ID = 'fmt ' |
------------------------------------------------
| Fact Chunk(optional) |
| ID = 'fact' |
------------------------------------------------
| Data Chunk |
| ID = 'data' |
------------------------------------------------
图1 Wav格式包含Chunk示例
其中除了Fact Chunk外,其他三个Chunk是必须的。每个Chunk有各自的ID,位
于Chunk最开始位置,作为标示,而且均为4个字节。并且紧跟在ID后面的是Chunk大
小(去除ID和Size所占的字节数后剩下的其他字节数目),4个字节表示,低字节
表示数值低位,高字节表示数值高位。下面具体介绍各个Chunk内容。
PS:
所有数值表示均为低字节表示低位,高字节表示高位。
二、具体介绍
RIFF WAVE Chunk
==================================
| |所占字节数| 具体内容 |
==================================
| ID | 4 Bytes | 'RIFF' |
----------------------------------
| Size | 4 Bytes | |
----------------------------------
| Type | 4 Bytes | 'WAVE' |
----------------------------------
图2 RIFF WAVE Chunk
以'FIFF'作为标示,然后紧跟着为size字段,该size是整个wav文件大小减去ID
和Size所占用的字节数,即FileLen - 8 = Size。然后是Type字段,为'WAVE',表
示是wav文件。
结构定义如下:
struct RIFF_HEADER
{
char szRiffID[4]; // 'R','I','F','F'
DWORD dwRiffSize;
char szRiffFormat[4]; // 'W','A','V','E'
};
Format Chunk
====================================================================
| | 字节数 | 具体内容 |
====================================================================
| ID | 4 Bytes | 'fmt ' |
--------------------------------------------------------------------
| Size | 4 Bytes | 数值为16或18,18则最后又附加信息 |
-------------------------------------------------------------------- ----
> | FormatTag | 2 Bytes | 编码方式,一般为0x0001 | |
-------------------------------------------------------------------- |
| Channels | 2 Bytes | 声道数目,1--单声道;2--双声道 | |
-------------------------------------------------------------------- |
| SamplesPerSec | 4 Bytes | 采样频率 | |
-------------------------------------------------------------------- |
| AvgBytesPerSec| 4 Bytes | 每秒所需字节数 | |===>VE_FORMAT
-------------------------------------------------------------------- |
| BlockAlign | 2 Bytes | 数据块对齐单位(每个采样需要的字节数) | |
-------------------------------------------------------------------- |
| BitsPerSample | 2 Bytes | 每个采样需要的bit数 | |
-------------------------------------------------------------------- |
| | 2 Bytes | 附加信息(可选,通过Size来判断有无) | |
-------------------------------------------------------------------- ----
图3 Format Chunk
以'fmt '作为标示。一般情况下Size为16,此时最后附加信息没有;如果为18
则最后多了2个字节的附加信息。主要由一些软件制成的wav格式中含有该2个字节的
附加信息。
结构定义如下:
struct WAVE_FORMAT
{
WORD wFormatTag;
WORD wChannels;
DWORD dwSamplesPerSec;
DWORD dwAvgBytesPerSec;
WORD wBlockAlign;
WORD wBitsPerSample;
};
struct FMT_BLOCK
{
char szFmtID[4]; // 'f','m','t',' '
DWORD dwFmtSize;
WAVE_FORMAT wavFormat;
};
Fact Chunk
==================================
| |所占字节数| 具体内容 |
==================================
| ID | 4 Bytes | 'fact' |
----------------------------------
| Size | 4 Bytes | 数值为4 |
----------------------------------
| data | 4 Bytes | |
----------------------------------
图4 Fact Chunk
Fact Chunk是可选字段,一般当wav文件由某些软件转化而成,则包含该Chunk。
结构定义如下:
struct FACT_BLOCK
{
char szFactID[4]; // 'f','a','c','t'
DWORD dwFactSize;
};
Data Chunk
==================================
| |所占字节数| 具体内容 |
==================================
| ID | 4 Bytes | 'data' |
----------------------------------
| Size | 4 Bytes | |
----------------------------------
| data | | |
----------------------------------
图5 Data Chunk
Data Chunk是真正保存wav数据的地方,以'data'作为该Chunk的标示。然后是
数据的大小。紧接着就是wav数据。根据Format Chunk中的声道数以及采样bit数,
wav数据的bit位置可以分成以下几种形式:
---------------------------------------------------------------------
| 单声道 | 取样1 | 取样2 | 取样3 | 取样4 |
| |--------------------------------------------------------
| 8bit量化 | 声道0 | 声道0 | 声道0 | 声道0 |
---------------------------------------------------------------------
| 双声道 |
取样1 | 取样2 |
| |--------------------------------------------------------
| 8bit量化 | 声道0(左) | 声道1(右) | 声道0(左) | 声道1(右) |
---------------------------------------------------------------------
| | 取样1 | 取样2 |
| 单声道 |--------------------------------------------------------
| 16bit量化 | 声道0 | 声道0 | 声道0 | 声道0 |
| | (低位字节) | (高位字节) | (低位字节) | (高位字节) |
---------------------------------------------------------------------
| | 取样1 |
| 双声道 |--------------------------------------------------------
| 16bit量化 | 声道0(左) | 声道0(左) | 声道1(右) | 声道1(右) |
| | (低位字节) | (高位字节) | (低位字节) | (高位字节) |
---------------------------------------------------------------------
图6 wav数据bit位置安排方式
Data Chunk头结构定义如下:
struct DATA_BLOCK
{
char szDataID[4]; // 'd','a','t','a'
DWORD dwDataSize;
};
三、小结
因此,根据上述结构定义以及格式介绍,很容易编写相应的wav格式解析代码。
这里具体的代码就不给出了。
四、参考资料
1、李敏, 声频文件格式WAVE的转换, 电脑知识与技术(学术交流), 2005.
2、http://www.codeguru.com/cpp/g-m/multimedia/audio/article.php/c8935__1/
3、http://www.smth.org/pc/pcshowcom.php?cid=129276