在创建Servlet时会覆盖service()方法,或doGet()/doPost(),这些方法都有两个参数,
一个为代表请求的request和代表响应response。
service方法中的response的类型是ServletResponse,而doGet/doPost方法的response的类型是HttpServletResponse,HttpServletResponse是ServletResponse的子接口,功能和方法更加强大。
response的运行流程

通过抓包工具抓取Http响应
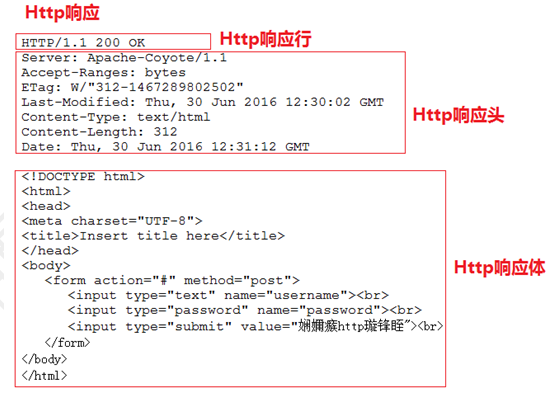
通过response设置响应行
协议版本 404/500
设置响应行的状态码
setStatus(int sc)
通过response设置响应头
addHeader(String name, String value)
addIntHeader(String name, int value)
addDateHeader(String name, long date)
setHeader(String name, String value)
setDateHeader(String name, long date)
setIntHeader(String name, int value)
其中,add表示添加,而set表示设置
重定向需要:1.状态码:302
2.响应头:location 代表重定向地址
通过response设置响应体
响应体设置文本
获得字符流,通过字符流的write(String s)方法可以将字符串设置到response缓冲区中,随后Tomcat会将response缓冲区中的内容组装成Http响应返回给浏览器端。
关于设置中文的乱码问题
原因:response缓冲区的默认编码是iso8859-1,此码表中没有中文,可以通过response的setCharacterEncoding(Stringcharset)设置response的编码
通过response的setContentType(String type)方法指定页面解析时的编码是UTF-8
response.setContentType("text/html;charset=UTF-8");
上面的代码不仅可以指定浏览器解析页面时的编码,同时也内含setCharacterEncoding的功能,所以在实际开发中只要编写 response.setContentType("text/html;charset=UTF-8");就可以解决页面输出中文乱码问题。
响应头设置字节
ServletOutputStream getOutputStream()
获得字节流,通过该字节流的write(byte[] bytes)可以向response缓冲区中写入字节,
在由Tomcat服务器将字节内容组成Http响应返回给浏览器。
文件下载案例:
代码演示:
public class DownloadServlet extends HttpServlet { public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { //获取要下载的文件名称 String filename=request.getParameter("filename"); //request解决中文乱码 filename=new String(filename.getBytes("ISO-8859-1"),"utf-8"); //获取请求头中的浏览器信息 String agent=request.getHeader("User-Agent"); //复制不同浏览器对文件名编码的代码 String filenameEncoder=""; if (agent.contains("MSIE")) { // IE浏览器 filenameEncoder = URLEncoder.encode(filename, "utf-8"); filenameEncoder = filenameEncoder.replace("+", " "); } else if (agent.contains("Firefox")) { // 火狐浏览器 BASE64Encoder base64Encoder = new BASE64Encoder(); filenameEncoder= "=?utf-8?B?" + base64Encoder.encode(filename.getBytes("utf-8")) + "?="; } else { // 其它浏览器 filenameEncoder= URLEncoder.encode(filename, "utf-8"); } System.out.println(filename);//薛之谦.txt //要下载的文件的类型—客户端会通过文件的MIME类型去区分类型 response.setContentType(getServletContext().getMimeType(filename)); //告知客户端文件的打开方式(下载) response.setHeader("Content-Disposition", "attachment;filename="+filenameEncoder); //获取文件的绝对路径 String path=getServletContext().getRealPath("download/"+filename); //获得该文件的输入流 FileInputStream fis=new FileInputStream(path); //获取文件输出流 ServletOutputStream sos=response.getOutputStream(); //文件的复制 int len=0; byte[] bytes=new byte[1024]; while((len=fis.read(bytes))!=-1){ sos.write(bytes,0,len); } fis.close(); } public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { doGet(request, response); } }
解决response中文乱码:
//request解决中文乱码 filename=new String(filename.getBytes("ISO-8859-1"),"utf-8"); //复制不同浏览器对文件名编码的代码 String filenameEncoder=""; if (agent.contains("MSIE")) { // IE浏览器 filenameEncoder = URLEncoder.encode(filename, "utf-8"); filenameEncoder = filenameEncoder.replace("+", " "); } else if (agent.contains("Firefox")) { // 火狐浏览器 BASE64Encoder base64Encoder = new BASE64Encoder(); filenameEncoder= "=?utf-8?B?" + base64Encoder.encode(filename.getBytes("utf-8")) + "?="; } else { // 其它浏览器 filenameEncoder= URLEncoder.encode(filename, "utf-8"); }
response细节点:
- response获得的流不需要手动关闭,web容器(tomcat容器)会帮助我们关闭,
- getWriter和getOutputStream不能同时调用
- 重定向语句一般作为终结代码