1. 面向对象概念
把要研究的事物抽象成对象处理。一个对象内部含有:数据值描述其状态、操作方法即对象的行为用于改变对象的状态。面向对象具有对象唯一性、分类型、继承性、多态性。自己的理解就是将一项活动抽象成一个个角色对象,通过内部的属性和方法彼此连接,构成整个活动。
2. 面向对象三特性
继承
封装:把客观的事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的类进行信息的隐藏。
多态:指允许不同类的对象对同一消息作出响应,即同一消息可以根据发送对象的不同而采用不同的行为方式。
多态三个必要条件:继承、重写、父类引用指向子类对象。
多态实现原理:动态绑定 -静态绑定 https://www.iteye.com/blog/hxraid-428891
动态绑定具体的调用过程为:
1.首先会找到被调用方法所属类的全限定名
2.在此类的方法表中寻找被调用方法,如果找到,会将方法表中此方法的索引项记录到常量池中(这个过程叫常量池解析),如果没有,编译失败。
3.根据具体实例化的对象找到方法区中此对象的方法表,再找到方法表中的被调用方法,最后通过直接地址找到字节码所在的内存空间。
最后说明,域和静态方法都是不具有多态性的,任何的域访问操作都将由编译器解析,因此不是多态的。静态方法是跟类,而并非单个对象相关联的。对动态绑定还有不明白的请看资料链接,个人感觉分析的很到位
3. String、StringBuilder、StringBuffer比较
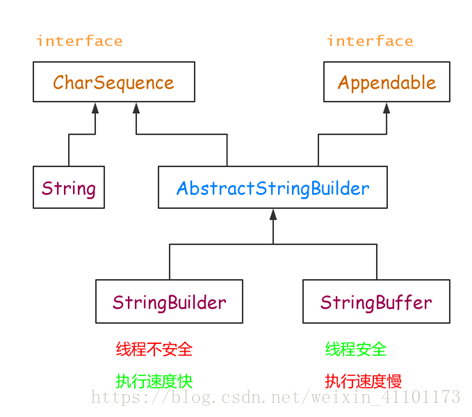
·String被final修饰,因此是线程安全类且是不可变类。
StringBuilder、StringBuffer继承AbstractStringBuilder类,添加字符串时,调用AbstractStringBuilder的append方法:
public AbstractStringBuilder append(String str) { if (str == null) return appendNull(); int len = str.length(); ensureCapacityInternal(count + len);//保证容量 str.getChars(0, len, value, count);//此处调用的是String的getChars方法,简单来说就是把str的String类对应的字符数组复制到当前字符数组内。System.arraycopy count += len; return this; }p
区别
运行速度:StringBuild>StringBuffer>String。String为字符串常量,而StringBuilder和StringBuffer均为字符串变量,即String对象一旦创建之后该对象是不可更改的,但后两者的对象是变量,是可以更改的。
线程安全:StringBuffer和String是线程安全的,StringBuilder线程不安全。
应用场景:String适用于少量字符串操作的情况;StringBuilder:适用于单线程下的字符缓冲区进行大量操作的情况;StringBuffer适用于在字符串缓冲区进行大量操作的情况。
4. 元注解
——元注解作用是负责注解其他注解
- @Target:修饰的对象范围,说明了Annotation所修饰的对象范围。
- @Retention:该注解被被保留的时间长短。
- @Documented:用于描述其它类型的annotation应该被作为被标注的程序成员的公共API。
- @Inherited:阐述了某个被标注的类型是继承的,如果一个被Inherited修饰的注解类型作用于一个class,那么这个注解将作用于class的子类
——自定义注解
//自定义注解 [@Target] [@Retention] [@Documented] [@Inherited] public @interface [名称] { // 元素 }
——Java自带的注解
@Override: 标记方法,重写父类方法
@Deprecated: 标明某个类或方法过时
@SuppressWarnings:标明要忽略的警告
——注解实现原理
5. 抽象类&接口
| 参数 | 抽象类 | 接口 |
| 默认的方法实现 | 它可以有默认的方法实现 | 接口完全是抽象的。它根本不存在方法的实现 |
| 实现 | 子类使用extends关键字来继承抽象类。如果子类不是抽象类的话,它需要提供抽象类中所有声明的方法的实现。 | 子类使用关键字implements来实现接口。它需要提供接口中所有声明的方法的实现 |
| 构造器 | 抽象类可以有构造器 | 接口不能有构造器 |
| 与正常Java类的区别 | 除了你不能实例化抽象类之外,它和普通Java类没有任何区别 | 接口是完全不同的类型 |
| 访问修饰符 | 抽象方法可以有public、protected和default这些修饰符 | 接口方法默认修饰符是public。你不可以使用其它修饰符。 |
| main方法 | 抽象方法可以有main方法并且我们可以运行它 | 接口没有main方法,因此我们不能运行它。(java8以后接口可以有default和static方法,所以可以运行main方法) |
| 多继承 | 抽象方法可以继承一个类和实现多个接口 | 接口只可以继承一个或多个其它接口 |
| 速度 | 它比接口速度要快 | 接口是稍微有点慢的,因为它需要时间去寻找在类中实现的方法。 |
| 添加新方法 | 如果你往抽象类中添加新的方法,你可以给它提供默认的实现。因此你不需要改变你现在的代码。 | 如果你往接口中添加方法,那么你必须改变实现该接口的类。 |
6. 深拷贝&浅拷贝
- 浅拷贝:仅仅复制内存地址引用,而不复制对象实体。原地址的对象改变了,那么复制的对象也将改变。
- 深拷贝:复制内存地址引用和对象实体,在计算机内新开辟了一块新的内存地址用于存放复制的对象。两个对象相互独立。
- Serializable方式:通过java对象的序列化和反序列化的操作实现对象拷贝的一种比较常见的方式。本来java对象们都待在虚拟机堆中,通过序列化,将源对象的信息以另外一种形式存放在了堆外。这时源对象的信息就存在了2份,一份在堆内,一份在堆外。然后将堆外的这份信息通过反序列化的方式再放回到堆中,就创建了一个新的对象,也就是目标对象。
- Cloneable方式:核心是Object类的native方法clone()。通过调用clone方法,可以创建出一个当前对象的克隆体,但需要注意的是,这个方法不支持深拷贝。如果对象的成员变量是基础类型,那妥妥的没问题。但是对于自定义类型的变量或者集合(集合我还没测试过)、数组,就有问题了。你会发现源对象和目标对象的自定义类型成员变量是同一个对象,也就是浅拷贝,浅拷贝就是对对象引用(地址)的拷贝。这样的话源对象和目标对象就不是彼此独立,而是纠缠不休了。为了弥补clone方法的这个不足。需要我们自己去处理非基本类型成员变量的深拷贝。
7. 异常分类及处理
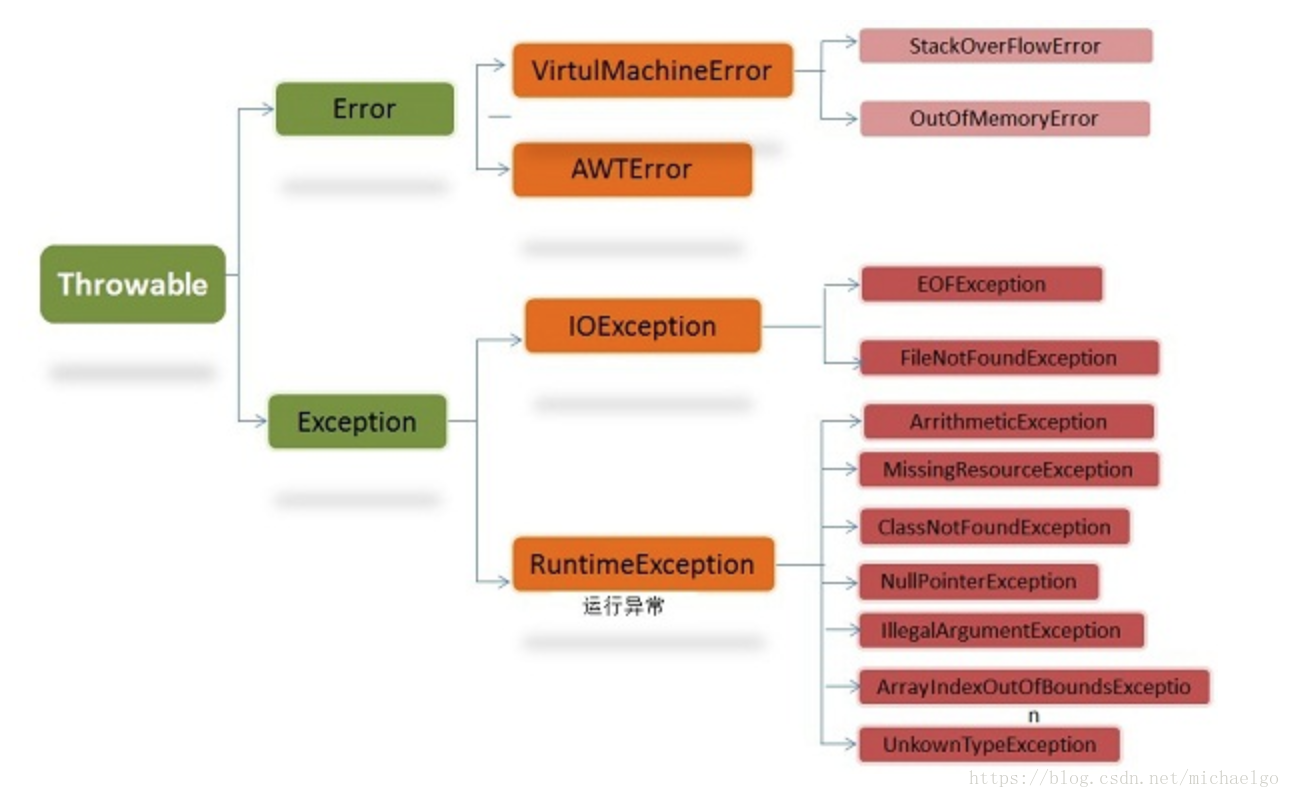
- Error:指Java运行时系统内部错误和资源耗尽错误。如果出现这样的错误,应用程序不会抛出这类对象,除了告知用户,剩下的就是让程序经理安全的终止。
- Exceprion
- RuntimeException:运行时异常,可能在Java虚拟机正常运行期间抛出的异常的超类。一般是程序错误。
- CheckedException:检查异常,一般是外部错误,发生于编译阶段。Java编译器会强制程序去捕捉此异常,即会出现要求你把这段可能出现异常的程序进行try catch。
throws & throw
- 位置:throws作用于函数上,后面跟一个或多个异常类;throw作用于函数内,后面跟着异常对象;
- 功能:throws用来声明异常,并不一定会发生。throw抛出具体的问题对象,一定会抛出某种异常对象。
8. 八种基本数据类型及所占字节数
| 类型 | byte | char | short | int | long | float | double | boolean |
| 所占字节数 | 1 | 2 | 2 | 4 | 8 | 4 | 8 | 1 |
int类型取值范围:-2^31 ~ 2^31-1
1,ASCII码:一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。
2,UTF-8编码:一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。中文标点占三个字节,英文标点占一个字节
3,Unicode编码:一个英文等于两个字节,一个中文(含繁体)等于两个字节。中文标点占两个字节,英文标点占两个字节
9. 内部类
- 静态内部类:可以访问外部类所有静态变量和方法。其他类使用静态内部类内的变量和方法需要通过“外部类.内部静态类”的方式获取。
- 成员内部类:成员内部类不能定义静态方法和变量,final修饰的除外。这是因为类初始化的时候初始化静态成员,如果允许成员内部类定义静态变量,那么初始化顺序有歧义。
- 局部内部类:定义在方法中的类就是局部类。
- 匿名内部类:匿名内部类必须继承一个父类或者实现一个接口,同时也没有class关键字。
-
new 类名或接口名(){ 重写方法; }; //注意分号 //以上就是匿名内部类的格式,其实这整体就相当于是new出来的一个对象
10. equals & ==
“==”对比两个对象时比较的是对象的内存地址,对比两个基本数据类型时,比较的是数值的大小。
equals()如果没有重写,那么Object类中默认的是“==”实现的,与==效果相同。但是一般会重写equals方法,用来比较两个对象内容是否相同。
11. equal & hashcode
equals()如果没有重写,那么Object类中默认的是“==”实现的,与==效果相同。但是一般会重写equals方法,用来比较两个对象内容是否相同。
hashcode()代表这个对象的哈希码,但是会出现哈希冲突,即两个不同的对象但是哈希码相同。
有这样的一个逻辑:如果两个对象equals相等(即对象内存地址相同),那么hashcode一定相等,反之则不然。
【扩展】哈希算法:开发定址法、再哈希法、链地址法、建立一个公共溢出区。
12. JDK8新特性
https://www.cnblogs.com/wuhenzhidu/tag/Java8%E6%96%B0%E7%89%B9%E6%80%A7/
① Lambda:Lambda允许把函数作为一个方法的参数。实现原理
② 方法引用:可以直接引用已有的Java类或对象的方法或构造器。
③ Data Time API:加强对日期和事件的处理。
④ Stream API
⑤ 接口默认方法、静态方法
⑥ Optional
13. final关键字
① 当final修改类时,该类成为最终类,无法被继承。
② 当final修饰方法时,这个方法将成为最终方法,无法被子类重写。但是,该方法仍然可以被继承。
③ 当final修饰引用时
- 如果引用为基本数据类型,则该引用为常量,该值无法修改;
- 如果引用为引用数据类型,比如对象、数组,则该对象、数组本身可以修改,但指向该对象或数组的地址的引用不能修改。
- 如果引用时类的成员变量,则必须当场赋值,否则编译会报错。
14. volatile关键字
volatile关键字用来保证有序性和可见性。我们所写的代码并不会按照我们输入的顺序来执行,编译器会做重排序,CPU也会做重排序,这样的重排序是为了减少流水线阻塞的,提高CPU的执行效率。但需要满足happens-before规则,其中有一条就是:对一个变量的写操作先行发生于读操作。有序性就是通过插入内存屏障实现的。可见性:主内存、工作内存、JMM展开叙述。
15. Comparable & Comparator (示例参考)
Comparable相当于“内部比较器”,而Comparator相当于“外部比较器”
- Comparable:排序接口,该接口只有一个compareTo(T o)函数。如果一个类实现了Comparator接口,就意味着该类支持排序。
- Comparator:比较器接口,有两个方法compare(T o1, T o2)和equals(Object o)。如果需要控制某个类的次序,而该类本身不支持排序(即没有实现Comparable接口);那么,我们可以建立一个“该类的比较器”来进行排序。这个“比较器”只需要实现Comparator接口即可。也就是说,我们可以通过“实现Comparator类来新建一个比较器”,然后通过该比较器对类进行排序。
1. top -c 命令找出当前进程的运行列表 2. 按一下 P 可以按照CPU使用率进行排序 3. top -Hp 2609 找出这个进程下面的线程,继续按P排序 4. 线程ID是十进制的,我们需要转换为十六进制
20. 代理模式
21. 泛型
1. 实现原理——类型擦除‘
Java中的泛型基本上都是在编译器这个层次来实现的。在生成的Java字节码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会在编译器在编译的时候去掉。这个过程就称为类型擦除。
java编译器是通过先检查代码中泛型的类型(类型检查:针对引用),然后再进行类型擦除,再进行编译的。
既然类型擦除转换成原始类型,为什么获取时不用转换类型呢?——一般获取元素方法都会根据泛型类型强转。
2. 上下界
上界 <? extend *>:上界定义的类只能获取元素不能添加。添加什么类型不确定,但是获取的类型可以使用父类接着。
下界 <? super *>:下界定义的类只能添加元素不能获取。可以添加当前类或者子类,但是获取的话父类有许多种不知道用什么接着。
23. 创建对象四种方式?
- 使用 new 关键字(最常用):
ObjectName obj = new ObjectName();
- 使用反射的Class类的newInstance()方法:
ObjectName obj = ObjectName.class.newInstance();
- 使用反射的Constructor类的newInstance()方法:
ObjectName obj = ObjectName.class.getConstructor.newInstance();
- 使用对象克隆clone()方法:
ObjectName obj = obj.clone();
- 使用反序列化(ObjectInputStream)的readObject()方法:
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(FILE_NAME))) {
ObjectName obj = ois.readObject();
}
1. 在try和catch中有return,finally中没有return,且finally中没有对try或catch中要 return数据进行操作的代码。
——finally代码依然会执行。方法返回try或者catch的return结果。
2. 在try和catch中有return,finally中没有return,但finally中有对try或catch中要 return数据进行操作的代码。
——方法返回的数据为基本数据类型,则finally中对要返回数据操作无影响。
——方法返回的数据为基本数据类型,则finally中对要返回数据操作无影响。
3. 在try和catch中有return,finally中也有return
——try或catch中return后面的代码会执行,但最终返回的结果为finally中return的值,需要注意的是try或catch中return后面的代码会执行,只是存起来了,并没有返回,让finally捷足先登先返回了。
4.在try中有return,在catch中新抛出异常,finally中有return
——如果catch块中捕获了异常, 并且在catch块中将该异常throw给上级调用者进行处理, 但finally中有return, 那么catch块中的throw就失效了, 上级方法调用者是捕获不到异常
25. Static关键字
- 修饰成员变量和成员方法(不能修饰局部变量)
- 静态代码块
- 修饰类(只能修饰内部类)———— 它的创建是不需要依赖外围类的创建。它不能使用任何外围类的非static成员变量和方法。
- 静态导包(用来导入类中的静态资源,1.5之后的新特性)
static修饰的成员被所有的对象共享。static修饰的数据是共享数据,对象中的存储的是特有的数据。 ————成员变量和静态变量的区别: 1、生命周期的不同: 成员变量随着对象的创建而存在随着对象的回收而释放。 静态变量随着类的加载而存在随着类的消失而消失。 2、调用方式不同: 成员变量只能被对象调用。 静态变量可以被对象调用,也可以用类名调用。(推荐用类名调用)3、数据存储位置不同: 成员变量数据存储在堆内存的对象中,所以也叫对象的特有数据。 静态变量数据存储在方法区(共享数据区)的静态区,所以也叫对象的共享数据。 (3)静态使用时需要注意的事项: 1、静态方法只能访问静态成员。(非静态既可以访问静态,又可以访问非静态) 2、静态方法中不可以使用this或者super关键字。 3、主函数是静态的
26. transient关键字
保证被修饰的变量不被序列化到磁盘内,例如ArrayList的数组elementData,数组容量并不是列表实际大小,序列化到磁盘浪费空间。
https://blog.csdn.net/zero__007/article/details/52166306
https://baijiahao.baidu.com/s?id=1636557218432721275&wfr=spider&for=pc、
27. 内存泄漏
https://zhuanlan.zhihu.com/p/62908157
28. 编译型语言 解释型语言
编译型:只需一次就将源代码编译成机器语言,后面无需再次编译。执行效率高,例如C、C++。但依赖编译器,跨平台比较差。
解释型:源代码不能直接翻译成机器语言,而是先翻译成中间代码,再由解释器对中间代码进行解释运行;程序在运行时才翻译成机器语言,每执行一次都要翻译一次;运行效率一般相对比较低,依赖解释器,跨平台性好;
Java是哪种?既是编译型也是解释型:java文件先编译成与平台无关的.class的字节码文件,jvm的类加载器首先加载字节码文件,然后通过解释器逐行解释执行,每次执行都需要加载、解析,速度慢,还有热点代码重复加载问题。所以引进了JIT编译器(运行时编译),JIT完成一次编译后会将字节码对应的机器码保存下来,下次直接执行,这就是为什么经常说java是解释性语言也是编译型语言。
29. linux 命令:
找出文件里的match的一行
grep [选项] PATTERN [FILE]
[选项:]
-c:只输出匹配行的计数。
-i:不区分大小写
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-n:显示匹配行及行号。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
找出文件某几行内容:sed -n 'start,endp' ** file;
sed -n 'a,bp' song.txt读取自第a行到第b行的数据
sed -n '100,1p' wang.txt //只查看第一百行
29. 多线程下载文件
1. 要知道服务端资源大小(通过URLConnection请求服务器url获取)
UrlConnection.getContentLength();//资源的大小
2. 在本地创建一个与服务端大小相同的文件
//file : 文件; mode:文件的模式,rwd:直接写到底层设备,硬盘 RandomAccessFile randomfile =new RandomAccessFile(File file,String mode) randomfile.setLength(long size);//创建一个文件和服务器资源一样大小
3. 分配每个线程开始位置和结束位置
4. 开启线程去下载
//需要Range头字段,key:Range value:bytes:0-499 urlconnection.setRequestPropety("Range","bytes:0-499") randomfile.seek(int startPostion);//本次线程下载保存的开始位置。
5. 要知道每个线程下载完毕
public void download(View v){ EditText et_url = (EditText) findViewById(R.id.et_url); String url = et_url.getText().toString().trim(); //1.创建httpUtils对象 HttpUtils httpUtils = new HttpUtils(); //2.调用download方法 url:下载的地址 target:下载的目录 callback:回调 httpUtils.download(url, "/sdcard/feiqiu/feiq.exe", new RequestCallBack<File>() { @Override public void onLoading(long total, long current, boolean isUploading) { System.out.println("total:"+total+";current:"+current); super.onLoading(total, current, isUploading); } @Override public void onSuccess(ResponseInfo<File> responseInfo) { System.out.println(responseInfo.result); } @Override public void onFailure(HttpException error, String msg) { // TODO Auto-generated method stub } }); }
30. 泛型
https://blog.csdn.net/lonelyroamer/article/details/7868820