Hibernate简介:
Hibernate是一个开放源代码的ORM(对象关系映射)框架,它对JDBC进行了非常轻量级的对象封装,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。 Hibernate可以应用在任何使用JDBC的场合,既可以在Java的客户端程序使用,也可以在Servlet/JSP的Web应用中使用。
---- 百度百科《Hibernate》
实现持久化的方法:
(1)对象的序列化
即实现了Serializable接口的类。适合于少量的对象进行暂时的持久化,适合于在网络上传输对象。但不符合企业级应用的需要。因为企业应用中对数据的要求是大量的、长时间保存的、需要进行大规模查询。
(2)JDBC
优点:功能完备、从理论上说效率是最高的;可以存储海量的数据并且适合进行大规模检索
缺点:开发效率和维护效率低;开发难度大,代码量大,占到到总代码量的1/3,或1/2
(3)ORM
ORM,即Object-Relational Mapping,对象关系映射。它是一种解决问题的思路,是一种思想。它的实质就是将关系数据库中的业务数据用对象的形式表示出来,并通过面向对象的方式将这些对象组织起来,以实现系统业务逻辑。或者说,ORM就是内存中的对象与数据库中的数据间的映射关系。

ORM的特点:开源的,实现了JDBC的封装, 实现了简单的API,轻量级解决方案,持久化对象是一个POJO类。最有名的ORM框架就是Hibernate。
JPA框架:
JPA,Java Persistence API,是Java EE 5的标准ORM接口。它是一种规范,一套接口,但不是实现。用于实现这一规范的ORM很多,其中Hibernate就是之一。
JPA、ORM、Hibernare之间的关系:
ORM是一种思想。JPA则是这种思想的具体的表现形式,是以Java语法规范表现出来的一种形式,是一套标准接口。Hibernate则是这套接口的具体实现。
Hibernate5基本jar包:略
Hibernate第一个程序:
1. Hibernate工作原理:
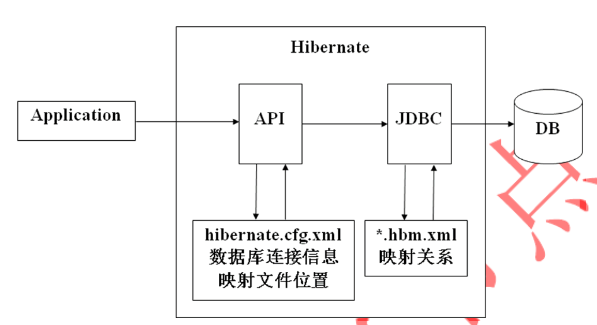
其中hibernate.cfg.xml文件名不能更改,*.hbm.xml中的*,最好用对应的类名替代。
2. 搭建Hibernate程序过程:
(1) 定义持久化对象:
1 package com.tongji.beans; 2 3 public class Student { 4 private Integer id; //定义实体的id要用Integer不能用int,因为底层要判断id == null 5 private String name; 6 private int age; 7 private double score; 8 9 public Student() { 10 super(); 11 } 12 13 public Student(String name, int age, double score) { 14 super(); 15 this.name = name; 16 this.age = age; 17 this.score = score; 18 } 19 20 public Integer getId() { 21 return id; 22 } 23 24 public void setId(Integer id) { 25 this.id = id; 26 } 27 28 public String getName() { 29 return name; 30 } 31 32 public void setName(String name) { 33 this.name = name; 34 } 35 36 public int getAge() { 37 return age; 38 } 39 40 public void setAge(int age) { 41 this.age = age; 42 } 43 44 public double getScore() { 45 return score; 46 } 47 48 public void setScore(double score) { 49 this.score = score; 50 } 51 52 @Override 53 public String toString() { 54 return "Student [id=" + id + ", name=" + name + ", age=" + age + ", score=" + score + "]"; 55 } 56 57 }
(2)配置映射文件(*.hbm.xml):
1 <?xml version="1.0" encoding="UTF-8"?> 2 <!DOCTYPE hibernate-mapping PUBLIC 3 "-//Hibernate/Hibernate Mapping DTD 3.0//EN" 4 "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> 5 6 <hibernate-mapping package="com.tongji.beans"> 7 <!-- 类到表的映射,属性到字段的映射 --> 8 <class name="Student" table="t_student"> 9 <id name="id" column="tid"> 10 <generator class="native"/> 11 </id> 12 <property name="name" column="tname"/> 13 <property name="age" column="tage"/> 14 <property name="score" column="tscore"/> 15 </class> 16 </hibernate-mapping>
其中,约束是在/org/hibernate/hibernate-mapping-3.0.dtd中查找。
<class/>标签:
name属性:指定持久化类。若<hibernate-mapping/>标签设置了package属性,那么,此处的name属性只需是类名即可;否则,需要是含包名的完整类名。
table属性:指定与持久化类对应的数据表的名称。若不指定,Hibernate将默认为表名与类名相同。
catalog属性:指定数据库。默认为主配置文件中指定的DB。
<id/>与<property/>属性:
name属性:指定持久化类的属性名
column属性:指定数据表中与name属性对应的字段名。若不指定,默认为与name属性同名。
length属性:指定属性所映射字段的长度,单位字节。
not-null属性:为指定字段添加非空约束。
unique属性:为指定字段添加唯一性约束。
type属性:指定属性所映射的字段的类型。若省略Hibernate会自动从持久化类中检测到类型。这里的类型取值支持两类:Java类型与Hibernate类型。
Java类型指的是Java代码中的类型。若是基本数据类型,如int、double等,直接写即可。但若是对象类型,则需要写上全类名,如java.lang.String。
Hibernate类型指的是Hibernate中定义的类型。在type的双引号中Alt + ?可查看到Hibernate中的所有类型。
sql-type属性:当然映射文件中字段类型还支持一种类型,即数据库中数据类型。但这种类型的使用,需要使用<column>元素,其中有一个sql-type属性用于指定字段类型。其值为所使用DBMS的数据类型。

重点,Hibernate常用的内置主键生成策略:(即generator中的class选项)
(1) increment生成策略:
该策略是Hibernate自己在维护主键的值。当准备在数据库表中插入一条新记录时,首先从数据库表中获取当前主键字段的最大值,然后在最大值基础上加1,作为新插入记录的主键值,这就是increment生成策略。
用其生成的主键字段所对应的属性类型可以是long、short、int及其封装类的类型。这种生成策略只有在没有其他进程向同一张表中插入数据时才能使用。在高并发下或集群下不能使用。
(2) identity生成策略:
该策略使用数据库自身的自增长来维护主键值。如mysql使用auto_increment来维护。用其生成的主键字段所对应的属性类型可以是long、short、int及其封装类的类型。
该策略在生成主键值时会出现以下情况:对于插入操作,即使最后的执行是回滚,DB中记录主键值的变量也会增一。因为该生成策略在发生回滚之前已经调用过DB的主键自增,所以无论是否提交,对于DB来说已经执行。
(3) sequence生成策略:
在Oracle、DB2和PostgreSQL等数据库中创建一个序列(sequence),然后Hibernate通过该序列为当前记录获取主键值,从而为实体对象赋予主键字段映射属性值。此即sequence生成策略,用其生成的主键字段映射属性值的类型可以是long、short、int及其封装类的类型。
对于MySql数据库,原本是不支持序列的。但稍作修改后,MySql也支持该生成策略。
(4) native生成策略:
由Hibernate根据所使用的数据库支持能力从identity、sequence生成策略中选择一种。
使用这种标识符属性生成策略可以根据不同的数据库采用不同的生成策略,如Oracle中使用sequence,在MySQL中使用identity便于Hibernate应用在不同的数据库之间移植。
(5) uuid生成策略:
uuid生成策略采用UUID算法来生成一个字符串类型的主键值,该值使用IP地址、JVM的启动时间(精确到1/4秒)、系统时间和一个计数器值(在当前的JVM中唯一)经过计算产生,可以用于分布式的Hibernate应用中。产生的标识符属性是一个32位长度的字符串。使用这种生成策略,要求属性的类型必须为String类型。
这种标识符属性生成策略生成的数值可以保证多个数据库之间的唯一性,并且由于其生成与具体的数据库没有关系,所以其移植性较强。但由于该值是32位长的字符串,所以占用的数据库空间较大,并且检索速度较慢。不过,实际开发中使用这种生成策略较多。
除了使用Hibernate外,在JDBC中也可以使用uuid生成主键。因为UUID是java.util包中的一个独立的类。可以打开项目的JRE System Library库中的rt.jar,在其中找到java.util包,即可看到UUID这个类。
(6) assigned生成策略:
该生成策略的主键值来自于程序员的手工设置,即通过setId()方法设置。属性类型可以是整型,也可以是String,但一般为String。此生成策略,主要应用于业务相关主键。例如学号、身份证号做主键。
(3) 配置主配置文件(hibernate.cfg.xml):
1 <?xml version="1.0" encoding="UTF-8"?> 2 <!DOCTYPE hibernate-configuration PUBLIC 3 "-//Hibernate/Hibernate Configuration DTD 3.0//EN" 4 "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"> 5 6 <hibernate-configuration> 7 <session-factory> 8 <!-- DB连接四要素 --> 9 <property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property> 10 <property name="hibernate.connection.url">jdbc:mysql:///mytest?useSSL=false</property> 11 <property name="hibernate.connection.username">root</property> 12 <property name="hibernate.connection.password">248xiaohai</property> 13 <!-- 方言 --> 14 <property name="hibernate.dialect">org.hibernate.dialect.MySQL5Dialect</property> 15 <!-- C3P0数据源 --> 16 <property name="hibernate.connection.provider_class">org.hibernate.c3p0.internal.C3P0ConnectionProvider</property> 17 <!-- 当前Session上下文 --> 18 <property name="hibernate.current_session_context_class">thread</property> 19 <!-- 自动建表 --> 20 <property name="hibernate.hbm2ddl.auto">update</property> 21 <!-- 显示SQL --> 22 <property name="hibernate.show_sql">true</property> 23 <!-- 格式化SQL --> 24 <property name="hibernate.format_sql">true</property> 25 26 <!-- 注册映射文件 --> 27 <mapping resource="com/tongji/beans/Student.hbm.xml"/> 28 </session-factory> 29 </hibernate-configuration>
约束是在/org/hibernate/hibernate-configuration-3.0.dtd种查找的;
DB连接四要素,同JDBC要求(数据库连接的基本要求),注意两点:
在DB连接四要素中的name属性名称,connection.*与hibernate.connection.*的效果是完全相同的。是为了兼容以前的版本;
在数据库连接的url属性值的设置,一般写法是jdbc:mysql://localhost:3306/test。但,localhost:3306不写也是正确的,jdbc:mysql:///test;
方言,每个数据库管理系统都有自己的方言,每个数据库管理系统的不同版本也有自己的方言,选项在hibernate-core-5.0.1.Final.jar中的org.hibernate.dialect中查找;
C3P0数据源,数据源是指数据库连接池,由于进行数据库连接比较耗时,系统就建立了一个数据路连接池,其中存放了一定数量的数据库连接,方便需要操作数据库时,直接从这个池中获取数据库连接。
Hibernate5默认使用的是其自己开发的内置(built-in)连接池。该连接池只是让调试代码时使用,在真正产品中不能使用。工业生产中,常用的数据源有DBCP、C3P0等;
当前Session上下文,指定缓存存放的位置,指定thread,表示将session放在每个线程中;
自动建表,有三个选项:
create:每次加载主配置文件时都会删除上一次的生成的表,然后再生成新表,哪怕两次表结构没有任何变化;
update:第一次加载主配置文件时创建新表,之后的每次都是更新该表,当表字段增加时,会添加字段;当表字段减少时,不会减少字段。若表结构没变化,但数据变化时,会修改数据;
create-drop:每次加载主配置文件时会生成表,但是sessionFactory一旦关闭,表就自动删除;
注册映射文件,前面配置的映射文件要在主配置文件中注册,可以有多个映射文件;
显示SQL、格式化SQL,主要为了调试,在执行Hibernate程序时,显示底层自动生成的sql语句。
(4) 定义测试类:
1 package com.tongji.test; 2 3 import org.hibernate.Session; 4 import org.hibernate.SessionFactory; 5 import org.hibernate.cfg.Configuration; 6 import org.junit.Test; 7 8 import com.tongji.beans.Student; 9 10 public class MyTest { 11 @Test 12 public void testSave() { 13 //1. 加载主配置文件 14 Configuration configure = new Configuration().configure(); 15 //2. 创建Session工厂 16 SessionFactory SessionFactory = configure.buildSessionFactory(); 17 //3. 获取Session 18 Session session = SessionFactory.getCurrentSession(); 19 try { 20 //4. 开启事务 21 session.beginTransaction(); 22 //session.getTransaction().begin(); 同样 23 //5. 操作 24 Student student = new Student("张三", 23, 93.5); 25 session.save(student); 26 //6. 事务提交 27 session.getTransaction().commit(); 28 } catch (Exception e) { 29 e.printStackTrace(); 30 //7. 事务回滚 31 session.getTransaction().rollback(); 32 } 33 } 34 }
注意:session的方法必须在事务之内执行,因为session是操作缓存中的数据,只有提交了事务之后,缓存中的数据才能写到数据库中。