蓝奏云的下载链接解析思路并不复杂,但网上几款真实链接解析工具,要么解析出的地址只是跳转链接,要么需要输入验证码,而蓝奏云网页版在使用是几乎是不会遇上验证码的,这实际上是因为蓝奏云在下载过程中有几个小坑。
直接上可用代码,后面再进行解释:
def downlanzou(lanzouurl, path, extracode): sess = requests.session() sess.headers = {'user-agent':"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"} req = sess.get(lanzouurl, verify=False) sign = re.search(r"action=downprocess&sign=([A-Za-z0-9_-]+?)&p=", req.text).group(1) head2 = { "referer": lanzouurl } req = sess.post("https://lanzous.com/ajaxm.php", data={ "action":"downprocess", "sign":sign, "p":extracode}, headers=head2, verify=False) res = req.json() url = res['dom']+'/file/'+res['url'] filename = res['inf'] os.makedirs(path, exist_ok=True) headnew = { "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36 OPR/28.0.1750.51", "Accept-Encoding":"gzip, deflate, lzma, sdch", # 重点1 "Accept-Language":"zh-CN,zh;q=0.8", # 重点2 "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8" # 重点3 } dreq = requests.get(url, headers=headnew, verify=False) with open(os.path.join(path, filename), 'wb') as f: f.write(dreq.content) return filename
关键在于三处重点,即最后一次请求里必须包含这三个头,虽然大多数时候,不带这类头并不会对访问产生影响,但笔者实验如果少了这几个头,就会被重定向到验证码页面,且即便输入正确也无法跳出。
但如果在Chrome的F12或者Charles里查看抓包,是不会看到这几个头的,而是如下图:
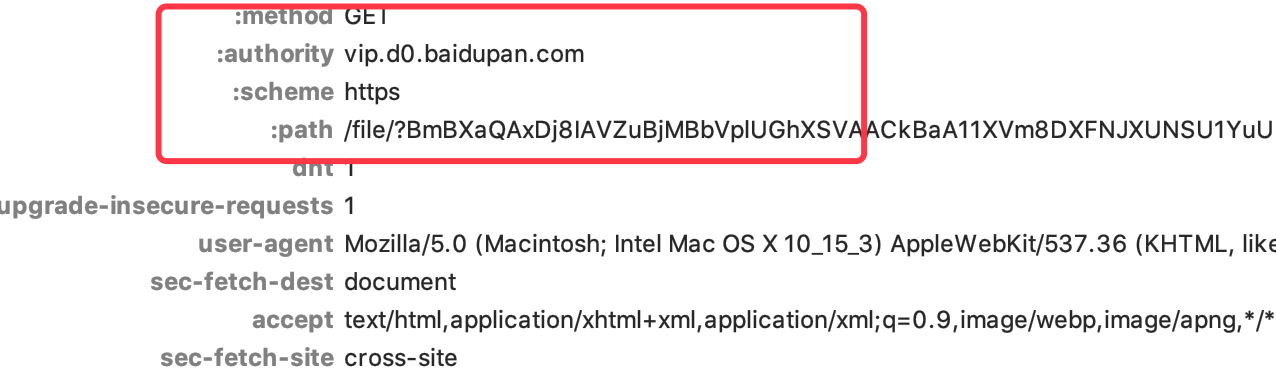
这是因为现在的浏览器基本都支持HTTP2标准,请求头里出现冒号代表服务器与浏览器协商后,使用了HTTP2标准来进行通信,但爬虫常用的requests等库都不支持HTTP2
虽然我们也可以通过另外的库让Python支持HTTP2(hyper库),但并无必要,只需要让服务器以HTTP1.1标准工作即可。可以下载各浏览器在15年或更早发布的版本,笔者使用的是欧朋28.0,再次访问即抓到了适合requests使用的请求头。
强制HTTP协议版本的方法不总是有效,比如天猫就已经开始限制HTTP1.1的使用。