import time import threading def sing(): """唱歌5秒""" for i in range(5): print("--正在唱---") time.sleep(1) def dance(): 子线程 for i in range(5): print("--正在跳舞---") time.sleep(1) def main(): t1 = threading.Thread(target=sing) t2 = threading.Thread(target=dance) 创建对象 t1.start() t2.start() 主线程 创建子线程 print(threading.enumerate()) #运行时查看有几个线程 如果没有延时不确定包含几个线程
if __name__ == '__main__':
main()
调用start()的时候子线程开启 函数代买执行完子线程结束
并行:真的多任务 并发:假的多任务
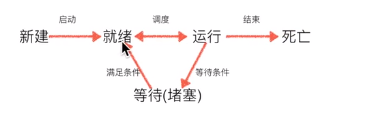
线程:程序运行起来 执行代码的东西
主线程 子线程:https://www.bilibili.com/video/av73705797?p=2
通过集成thread来创建线程
import threading import time class MyThread(thrading.Thread): def run(self): #必须写run for i in range(3): time.sleep(1) msg = "I'm"+self.name+@+str(i) print(msg) if __name__='__main__': t = MyThread() t.start 自动调用 run 方法
多个线程之间共享全局变量
num= 100 num=[11,22] def test(): global num num += 100 def test1(): nums.append(33) #nums+=[100,200]#需要加global print(num,nums) test() test1() print(num,nums) #改变其本身(内存地址)时需要加global 当改变其里面内容(不改变id)b不用加global
import time import threading g_num = 100 def test1(): global g_num g_num +=1 print("---->%d"%g_num) def test2(): print("---->%d"%g_num) def main(): t1 = threading.Thread(target=test1) t2 = threading.Thread(target=test2) t1.start() time.sleep(1) t2.start() if __name__ == '__main__': main() -->101 --->101
多线程共享全局变量--args参数 需要元组类型 join()
import time import threading g_num = 100 def test1(num): global g_num
for i in num: g_num +=1 print("---->%d"%g_num) def test2(): print("---->%d"%g_num) def main(): t1 = threading.Thread(target=test1,args=(100,)) t2 = threading.Thread(target=test2) t1.start() time.sleep(1) t2.start() if __name__ == '__main__': main()
import time
import random
from threading import Thread,currentThread
dic = {}
def func(i):
t = currentThread()
time.sleep(random.random())
dic[t.ident] = i**2
t_lst = []
for i in range(1,11):
t = Thread(target=func,args=(i,))
t.start()
t_lst.append(t)
for t in t_lst:
t.join()
print(dic[t.ident])
多线程可以有多个锁
死锁 可以添加超时时间解决
import json import time from multiprocessing import Process,Lock def search_ticket(name): with open('ticket',encoding='utf-8') as f: dic = json.load(f) print('%s查询余票为%s'%(name,dic['count'])) def buy_ticket(name): with open('ticket',encoding='utf-8') as f: dic = json.load(f) time.sleep(2) if dic['count'] >= 1: print('%s买到票了'%name) dic['count'] -= 1 time.sleep(2) with open('ticket', mode='w',encoding='utf-8') as f: json.dump(dic,f) else: print('余票为0,%s没买到票' % name) def use(name,lock): search_ticket(name) print('%s在等待'%name) # lock.acquire() # print('%s开始执行了'%name) # buy_ticket(name) # lock.release() with lock: print('%s开始执行了'%name) buy_ticket(name) if __name__ == '__main__': lock = Lock() l = ['alex','wusir','baoyuan','taibai'] for name in l: Process(target=use,args=(name,lock)).start()
from threading import Lock,Thread
noodle_lock = Lock()
fork_lock = Lock()
def eat1(name):
noodle_lock.acquire() # 阻塞 宝元等面
print('%s拿到面了'%name)
fork_lock.acquire()
print('%s拿到叉子了' % name)
print('%s吃面'%name)
fork_lock.release()
print('%s放下叉子了' % name)
noodle_lock.release()
print('%s放下面了' % name)
def eat2(name):
fork_lock.acquire() # 阻塞 wu‘sir等叉子
print('%s拿到叉子了' % name)
noodle_lock.acquire()
print('%s拿到面了'%name)
print('%s吃面'%name)
noodle_lock.release()
print('%s放下面了' % name)
fork_lock.release()
print('%s放下叉子了' % name)
Thread(target=eat1,args = ('alex',)).start()
Thread(target=eat2,args = ('wusir',)).start()
Thread(target=eat1,args = ('baoyuan',)).start()
多线程版聊天 udp:
https://www.bilibili.com/video/av73705797?p=10
进程:运行起来的程序 资源分配的单位
进程状态 : processing.Process
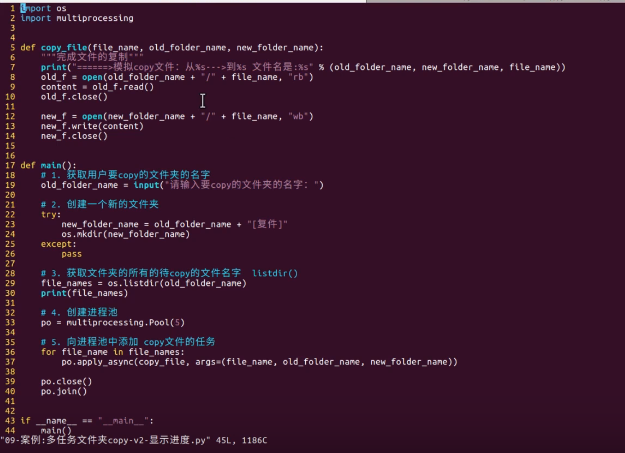
import time import threading import multiprocessing g_num = 100 def test1(): global g_num g_num += 1 print("---->%d" % g_num) def test2(): print("---->%d" % g_num) def main(): t1 = multiprocessing.Process(target=test1) t2 = multiprocessing.Process(target=test2) t1.start() time.sleep(1) t2.start() if __name__ == '__main__': main()
import os import time def func(i): time.sleep(5) print(i,os.getpid()) print('主 :',os.getpid()) func(0) func(1) func(2) 2.使用Process类创建一个子进程 import os import time from multiprocessing import Process def func(a,b,c): time.sleep(1) print(a,b,c,os.getpid(),os.getppid()) # pid : processid ppid : parent process id # # Process进程类 if __name__ == '__main__': # windows操作系统下开启子进程子进程中的代码是通过import这种方式被导入到子进程中的 print('主 :', os.getpid()) Process(target=func,args=(1,2,3)).start() Process(target=func).start() Process(target=func).start() 几个概念 子进程 父进程 主进程 if __name__ == '__main__' func的参数怎么传递 func的返回值能返回到父进程中么? 不行 进程之间数据 隔离,所以子进程中的返回值父进程获取不到 3.进程中的其他几个方法 import os import time from multiprocessing import Process def func(a,b,c): time.sleep(1) print(a,b,c,os.getpid(),os.getppid()) # # Process进程类 if __name__ == '__main__': p = Process(target=func,args=(1,2,3)) p.start() # p是一个进程操作符 print(p.is_alive()) p.terminate() # 异步非阻塞 print(p.is_alive()) time.sleep(0.1) print(p.is_alive()) print(p.name) print(p.pid) 4.如何开启多个子进程 import os import time from multiprocessing import Process def func(a,b,c): time.sleep(1) print(a,b,c,os.getpid(),os.getppid()) if __name__ == '__main__': # Process(target=func,args=(1,2,3)).start() # Process(target=func,args=(2,3,4)).start() # Process(target=func,args=(3,4,5)).start() for i in range(1,4): Process(target=func, args=(i, i+1, i+2)).start() join import time import random from multiprocessing import Process def send_mail(name): time.sleep(random.uniform(1,3)) print('已经给%s发送邮件完毕'%name) if __name__ == '__main__': lst = ['alex','yuan','宝元','太白'] #阻塞等待一个子进程结束 p = Process(target=send_mail, args=('alex',)) p.start() p.join() # 阻塞,直到p对应的进程结束之后才结束阻塞 print('所有的信息都发送完毕了') p_l = [] for name in lst: p = Process(target=send_mail,args=(name,)) p.start() p_l.append(p) for p in p_l : p.join() print('所有的信息都发送完毕了') # 守护进程 import time from multiprocessing import Process def func(): for i in range(20): time.sleep(0.5) print('in func') def func2(): print('start : func2') time.sleep(5) print('end : func2') if __name__ == '__main__': p = Process(target=func) p.daemon = True # 表示设置p为一个守护进程 p.start() p2 =Process(target=func2) #p2.daemon = True1 p2.start() print('in main') # time.sleep(3) print('finished') # p2.join() # 主进程和子进程互不干扰 # 主进程执行完毕之后程序不会结束,会等待所有的子进程结束之后才结束 # 为什么主进程要等待子进程结束之后才结束? # 因为主进程要负责给子进程回收一些系统资源 # 守护进程 : # 是一个子进程,守护的是主进程 # 结束条件 : 主进程的代码结束,守护进程也结束 # 进程 # 主进程的代码结束,守护进程结束 # 主进程要回收守护进程(子进程)的资源 # 主进程等待其他所有子进程结束 # 主进程回收所有子进程的资源
1.开启子进程 tartget args if __name__ == '__main__' start() 2.其他的方法 方法 : terminate() is_alive() 属性 pid name 3.开启多个子进程 4.join 阻塞等待一个子进程结束 阻塞等待多个子进程结束 5.守护进程 p.daemon= True 6.面向对象的方式实现多进程 import os from multiprocessing import Process class MyProcess(Process): def run(self): # 希望在子进程中执行的代码就放在run方法中 print(os.getpid()) if __name__ == '__main__': for i in range(10): MyProcess().start() import os from multiprocessing import Process class MyProcess(Process): def __init__(self,a,b): super().__init__() self.a = a self.b = b def run(self): # 希望在子进程中执行的代码就放在run方法中 print(os.getpid(),self.a,self.b) self.func() if __name__ == '__main__': for i in range(10): MyProcess(1,2).start() # 通知操作系统开进程,执行run方法
锁
import json import time from multiprocessing import Process,Lock def search_ticket(name): with open('ticket',encoding='utf-8') as f: dic = json.load(f) print('%s查询余票为%s'%(name,dic['count'])) def buy_ticket(name): with open('ticket',encoding='utf-8') as f: dic = json.load(f) time.sleep(2) if dic['count'] >= 1: print('%s买到票了'%name) dic['count'] -= 1 time.sleep(2) with open('ticket', mode='w',encoding='utf-8') as f: json.dump(dic,f) else: print('余票为0,%s没买到票' % name) def use(name,lock): search_ticket(name) print('%s在等待'%name) # lock.acquire() # print('%s开始执行了'%name) # buy_ticket(name) # lock.release() with lock: print('%s开始执行了'%name) buy_ticket(name) if __name__ == '__main__': lock = Lock() l = ['alex','wusir','baoyuan','taibai'] for name in l: Process(target=use,args=(name,lock)).start()
进程之间数据是隔离的
# 多个进程之间的数据是隔离的 # 进程之间的数据交互 # 是可以通过网络/文件来实现的 # socket来实现 # IPC - inter process communication # 通过python的模块实现的 # 基于原生socket # 基于进程队列的 ***** # 第三方的软件/工具来实现 : 基于网络的 # memcache redis rabbitMQ kafka - 软件名 from multiprocessing import Queue # 可以完成进程之间通信的特殊的队列 # from queue import Queue # 不能完成进程之间的通信 # q = Queue() # q.put(1) # q.put(2) # print(q.get()) # print(q.get()) # from multiprocessing import Queue,Process # # def son(q): # print('-->',q.get()) # # # if __name__ == '__main__': # q = Queue() # Process(target=son,args=(q,)).start() # q.put('wahaha') # 生产者消费者模型 # 获得数据 生产者 # 处理数据 消费者 # 调节生产者的个数或者消费者的个数来让程序的效率达到最平衡和最大化 # 解耦思想 import time import random from multiprocessing import Process,Queue def producer(q): for i in range(10): time.sleep(random.random()) food = '泔水%s'%i print('%s生产了%s'%('taibai',food)) q.put(food) def consumer(q,name): while True: food = q.get() # food = 食物/None if not food : break time.sleep(random.uniform(1,2)) print('%s 吃了 %s'%(name,food)) if __name__ == '__main__': q = Queue() p1 = Process(target=producer,args=(q,)) p1.start() c1 = Process(target=consumer,args=(q,'alex')) c1.start() c2 = Process(target=consumer,args=(q,'wusir')) c2.start() p1.join() q.put(None) q.put(None) #有多少个consumer 就有多少个put(none) # 如何结束整个程序 import time import random from multiprocessing import JoinableQueue,Process def consumer(jq,name): while True: food = jq.get() time.sleep(random.uniform(1,2)) print('%s吃完%s'%(name,food)) jq.task_done() def producer(jq): for i in range(10): time.sleep(random.random()) food = '泔水%s'%i print('%s生产了%s'%('taibai',food)) jq.put(food) jq.join() if __name__ == '__main__': jq = JoinableQueue(5) c1 = Process(target=consumer,args=(jq,'alex')) p1 = Process(target=producer,args=(jq,)) c1.daemon = True c1.start() p1.start() p1.join() # 锁 同一时刻同一段代码,只能有一个进程来执行这段代码 # 保证数据的安全 # 多进程中,只有去操作一些 进程之间可以共享的数据资源的时候才需要进行加锁 # lock = Lock() # acquire release # with lock: # Lock 互斥锁 # IPC # 队列 # PUT # GET # 生产者消费者模型 基于队列把生产数据和消费数据的过程分开了 # 补充 # 队列 是进程安全的 自带了锁 # 队列基于什么实现的 文件家族的socket服务 # 基于文件家族的socket服务实现的ipc机制不止队列一个,管道Pipe # 队列 = 管道 + 锁 # 管道 是基于文件家族的socket服务实现 # from multiprocessing import Pipe
from multiprocessing import Process,Manager,Lock def func(dic,lock): with lock: dic['count'] -= 1 if __name__ == '__main__': lock = Lock() m = Manager() dic = m.dict({'count':100}) p_l = [] for i in range(100): p = Process(target=func,args=(dic,lock)) p.start() p_l.append(p) for p in p_l:p.join() print(dic)
守护线程
import time from threading import Thread def daemon_func(): while True: time.sleep(0.5) print('守护线程') def son_func(): print('start son') time.sleep(5) print('end son') t = Thread(target=daemon_func) t.daemon = True t.start() Thread(target=son_func).start() time.sleep(3) print('主线程结束')
# 1.主线程会等待子线程的结束而结束
# 2.守护线程会随着主线程的结束而结束
# 守护线程会守护主线程和所有的子线程
# 进程会随着主线程的结束而结束
# 问题
# 1.主线程需不需要回收子线程的资源
# 不需要,线程资源属于进程,所以进程结束了,线程的资源自然就被回收了
# 2.主线程为什么要等待子线程结束之后才结束
# 主线程结束意味着进程进程,进程结束,所有的子线程都会结束
# 要想让子线程能够顺利执行完,主线程只能等
# 3.守护线程到底是怎么结束的
# 主线程结束了,主进程也结束,守护线程被主进程的结束结束掉了
# 守护进程 :只会守护到主进程的代码结束
# 守护线程 :会守护所有其他非守护线程的结束
线程池
import os import time from concurrent.futures import ProcessPoolExecutor def make(i): time.sleep(1) print('%s 制作螺丝%s'%(os.getpid(),i)) return i**2 if __name__ == '__main__': p = ProcessPoolExecutor(4) # 创建一个进程池 for i in range(100): p.submit(make,i) # 向进程池中提交任务 p.shutdown() # 阻塞 直到池中的任务都完成为止 print('所有的螺丝都制作完了') p.map(make,range(100)) # submit的简便用法 # 接收返回值 ret_l = [] for i in range(100): ret = p.submit(make,i) ret_l.append(ret) for r in ret_l: print(r.result()) ret = p.map(make, range(100)) for i in ret: print(i) # 回调函数 # import time # import random # def func1(n): # time.sleep(random.random()) # print('in func1 %s'%n) # return n*2 # # def call_back(arg): # print(arg.result()) # # if __name__ == '__main__': # p = ProcessPoolExecutor(4) # for i in range(10): # ret = p.submit(func1,i) # ret.add_done_callback(call_back) # ret_l = [] # for i in range(10): # ret = p.submit(func1, i) # ret_l.append(ret) # for r in ret_l: # call_back(r) # 1.不能有多少个任务就开多少个进程,这样开销太大了 # 2.用有限的进程执行无限的任务,多个被开启的进程重复利用,节省的是开启销毁多个进程切换的时间 # 3.回调函数是谁执行的?(主进程?子进程)
from urllib.request import urlopen from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor def get_html(name,addr): ret = urlopen(addr) return {'name':name,'content':ret.read()} def parser_page(ret_obj): dic = ret_obj.result() with open(dic['name']+'.html','wb') as f: f.write(dic['content']) url_lst = { '协程':'http://www.cnblogs.com/Eva-J/articles/8324673.html', '线程':'http://www.cnblogs.com/Eva-J/articles/8306047.html', '目录':'https://www.cnblogs.com/Eva-J/p/7277026.html', '百度':'http://www.baidu.com', 'sogou':'http://www.sogou.com' } t = ThreadPoolExecutor(20) for url in url_lst: task = t.submit(get_html,url,url_lst[url]) task.add_done_callback(parser_page) # task.result() # t.map() # t.shutdown() # 使用多线程去执行get_html获取网页对应的内容 # 一旦get_html执行结束之后,立即使用parser_page来分析获取的页面结果 # 进程池 除非高计算型的场景否则几乎不用 CPU的个数*2 # 线程池 cpu的个数*5 # 4 cpu 4*20 = 80
协程
协程(本质是一条线程,操作系统不可见) # 是由程序员操作的,而不是由操作系统调度的 # 多个协程的本质是一条线程,所以多个协程不能利用多核 # 出现的意义 : 多个任务中的IO时间可以共享,当执行一个任务遇到IO操作的时候, # 可以将程序切换到另一个任务中继续执行 # 在有限的线程中,实现任务的并发,节省了调用操作系统创建销毁线程的时间 # 并且协程的切换效率比线程的切换效率要高 # 协程执行多个任务能够让线程少陷入阻塞,让线程看起来很忙 # 线程陷入阻塞的次数越少,那么能够抢占CPU资源就越多,你的程序效率看起来就越高 # 1.开销变小了 # 2.效率变高了 # 两个任务,一个任务执行过程中遇到io操作就切到另一个任务执行 # 直到所有的任务都遇到IO操作了,才进入阻塞,其中有任何一个任务结束阻塞,都会回到就绪队列里 # 协程的本质 - 就是在多个任务之间能够来回切换
import time from greenlet import greenlet # 协程模块 def eat(): # 协程任务 协程函数 print('start eating') g2.switch() time.sleep(1) print('end eating') g2.switch() def sleep(): # 协程任务 协程函数 print('start sleeping') g1.switch() time.sleep(1) print('end sleeping') g1 = greenlet(eat) g2 = greenlet(sleep) g1.switch()
import time import gevent #不能用time.sleep 需要 gevent.sleep() def eat(): # 协程任务 协程函数 print('start eating') gevent.sleep(1) print('end eating') def sleep(): # 协程任务 协程函数 print('start sleeping') gevent.sleep(1) print('end sleeping') g1 = gevent.spawn(eat) g2 = gevent.spawn(sleep) # g1.join() # 阻塞,直到g1任务执行完毕 # g2.join() # 阻塞,直到g2任务执行完毕 gevent.joinall([g1,g2]) from gevent import monkey monkey.patch_all() import time import gevent def eat(): # 协程任务 协程函数 print('start eating') time.sleep(1) print('end eating') def sleep(): # 协程任务 协程函数 print('start sleeping') time.sleep(1) print('end sleeping') g1 = gevent.spawn(eat) # 创建协程 g2 = gevent.spawn(sleep) gevent.joinall([g1,g2]) # 阻塞 直到协程任务结束 # 请求网页 url_dic = { '协程':'http://www.cnblogs.com/Eva-J/articles/8324673.html', '线程':'http://www.cnblogs.com/Eva-J/articles/8306047.html', '目录':'https://www.cnblogs.com/Eva-J/p/7277026.html', '百度':'http://www.baidu.com', 'sogou':'http://www.sogou.com', '4399':'http://www.4399.com', '豆瓣':'http://www.douban.com', 'sina':'http://www.sina.com.cn', '淘宝':'http://www.taobao.com', 'JD':'http://www.JD.com' } import time from gevent import monkey;monkey.patch_all() from urllib.request import urlopen import gevent def get_html(name,url): ret = urlopen(url) content = ret.read() with open(name,'wb') as f: f.write(content) start = time.time() for name in url_dic: get_html(name+'_sync.html',url_dic[name]) ret = time.time() - start print('同步时间 :',ret) start = time.time() g_l = [] for name in url_dic: g = gevent.spawn(get_html,name+'_async.html',url_dic[name]) g_l.append(g) gevent.joinall(g_l) ret = time.time() - start print('异步时间 :',ret)
server: import socket import gevent from gevent import monkey monkey.patch_all() #这句话只要写上就会自动检查io 并自动换成gevent.sleep() 和gevent.joinall([ ])配套使用 sk = socket.socket() sk.bind(('127.0.0.1',9001)) sk.listen() def talk(conn): while True: msg = conn.recv(1024).decode('utf-8') conn.send(msg.upper().encode('utf-8')) while True: conn,_ = sk.accept() gevent.spawn(talk,conn) # 一条线程抗500个并发 # 进程 高计算型的场景下 # 线程 对于IO操作的检测是更加全面且灵敏的 # 协程 能够检测到的io操作是有限的 # 20 * 500 = 10000 # 5个进程 * 20 * 500 = 50000 client: import socket from threading import Thread def client(i): sk = socket.socket() sk.connect(('127.0.0.1',9001)) while True: sk.send(b'hello') print(sk.recv(1024)) for i in range(500): Thread(target=client,args=(i,)).start()