提到排名函数我们首先可能想到的是order by,这个是排序,不是排名,排名需要在前面加个名次序号的,order by是没有这个功能的。还可能会想到identity(1,1),它也给了一个序号,但是不能保证给出的序号是连续升序的。除非能够保证所有的Insert语句都能够正确成功地完成,并且没有删除操作,实际的使用中大多数的表都不能保证这样。
好在SQL Server中提供了一些排名函数来辅助实现这些功能。排名函数按照需要的顺序对数据进行排名,并提供一个值对数据。下面来了解一下这些排序函数功能。
ROW_NUMBER
ROW_NUMBER函数允许以上升,连续的顺序给每一行数据一个序号,注意ROW_NUMBER()后面一定要跟着over子句。来看语句:
use AdventureWorks
select
ROW_NUMBER() over(orderby LastName) as RowNum,
FirstName+''+ LastName as FullName
from HumanResources.vEmployee
where JobTitle='Production Technician - WC60'
这个语句对符合条件(JobTitle='Production Technician - WC60')的LastName按照升序排列,并加上排序的序号,这个序号是连续上升的。结果如下图1是部分结果。
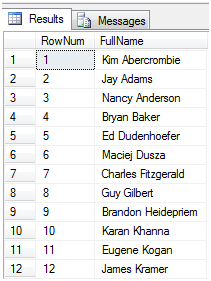
图1
我们可以看到第一个人的LastName是Abercrombie,第二个人的LastName是Adams,以次类推。
PARTITION
如果我们想再细分一下,在一个小的分组范围内排序该怎么办呢?就是说让LastName以‘A’开头的作为第一组,在这个组内进行排序。以‘B’开头的作为第二组,在这个组内排序。以‘C’开头的作为第三组,在这个组内进行排序,如此等等。这里有一个很简单的实际例子,假如上面这些人都来参加同一场马拉松比赛,其中有男子组,女子组,男子残疾组,女子残疾组,60岁以上组等等。不管参赛者以第几位触线,名次都以他们的小组为基准。
可以通过PARTITION BY选项来重新排序,给数据分区或者数据区域唯一的递增序号。来看下面的语句:
[注] partition n. 划分,分开;[数] 分割;隔墙;隔离物;vt. [数] 分割;分隔;区分
ROW_NUMBER() over(PARTITION bysubstring(LastName,1,1) orderby LastName) as RowNum,
FirstName+''+ LastName as FullName
from HumanResources.vEmployee
where JobTitle='Production Technician - WC60'
这里模拟上面的情况,首先以Last Name的第一个字母作为分组,然后以第二个字母以后的字母来分组排序。来看看结果,如图2
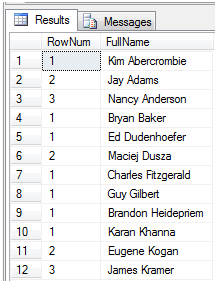
图2
假设LastName以‘A’开头的是男子组,这个组有共有三个人,Kim Abercrombie是冠军,Jay Adams是亚军,Nancy Anderson是季军。假设LastName以‘B’开头的是女子组,这个组只有一个人Bryan Baker,无论如何她都是冠军。等等如此类推。这样一眼就能看出他们的小组名次了。
这里你可能会觉得使用order by一样可以得到这样类似的结果。如下代码:
FirstName+''+ LastName as FullName
from HumanResources.vEmployee
where JobTitle='Production Technician - WC60'
orderbysubstring(LastName,1,1) ,LastName
这个把order by放在最后,排序放在最后,首先按照LastName的首字母排序,再按照剩整个LastName排序,结果如下图3
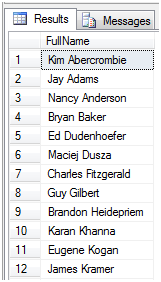
图3
结果和上面大致相同,可是少了前面的名次序号。于是我又对她进行了修改,代码如下:
ROW_NUMBER() over(orderbysubstring(LastName,1,1),LastName) as RowNum,
FirstName+''+ LastName as FullName
from HumanResources.vEmployee
where JobTitle='Production Technician - WC60'

排序没有错误,是我们想要的分组排序,但是前面的名次没有分组区分,和图1没有什么差别。可见图3和图4的做法完全是多余,纯属臆造,其实只要order by LastName都能得到正确的排序,只有partition by才是正解。通过上面的例子也可以对排序,排名这二者之间的区别有一个认识,他们虽然有相似之处,但是排名始终会产生一个名次序号,排序只要得到正确的顺序就好。
RANK
还是拿马拉松比赛来说事,如果有同时撞线的情况发生应该怎么计名次呢?例如A第一个撞线,B和C同时第二个撞线,D第三个撞线,如果我们想把D的名次计为第4名应该怎么处理呢?就是说不计顺序名次,只计人数。这时就可以使用RANK函数了。
[注] rank n. 等级;队列;排;军衔vt. 排列;把…分等vi. 列队;列为
在order by子句中定义的列上,如果返回一行数据与另一行具有相同的值,rank函数将给这些行赋予相同的排名数值。在排名的过程中,保持一个内部计数值,当值有所改变时,排名序号将有一个跳跃。
来看下面的语句:
ROW_NUMBER() over(orderby Department) as RowNum,
RANK() over(orderby Department) as Ranking,
FirstName+''+ LastName as FullName,
Department
from HumanResources.vEmployeeDepartment
orderby RowNum
rank()函数右面也要跟上一个over子句。为了看到效果我们以Department作为排序字段,可以看到RowNum作为升序连续排名,Ranking作为计同排名,当Department的值相同时,Ranking中的值保持不变,当Ranking中的值发生变化时,Ranking列中的值将跳跃到正确的排名数值。来看结果:
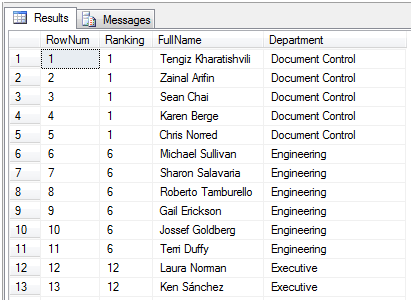
图5
从这个结果中我们可以说这次马拉松赛跑的排名是:Tengiz Kharatishvili,Zainal Arifin,Sean Chai,Karen Berge,Chris Norred并列第1,Michael Sullivan,Sharon Salavaria,Roberto Tamburello,Gail Erickson,Jossef Goldberg并列第6,如此等等。
DENSE_RANK
在上面的例子中,A第一个撞线,B和C同时第二个撞线,D第三个撞线,如果我们想把B和C的名次计位第2名,D的名次计为第3名应该怎么处理呢?就是说考虑并列名次。这里使用DENSE_RANK函数,来看下面的代码。
结果如下:

图6
按照这个结果,我们可以说这次马拉松赛跑的排名是:Tengiz Kharatishvili,Zainal Arifin,Sean Chai,Karen Berge,Chris Norred并列第1,Michael Sullivan,Sharon Salavaria,Roberto Tamburello,Gail Erickson,Jossef Goldberg,Terri Duffy并列第2,等等如此。
NTILE
在开始这个之前,先来一段小插曲。梭罗是铅笔的发明者,不过他没有申请专利。据说他天赋异禀,在父亲的铅笔厂里面打包铅笔的时候,从一堆铅笔里面抓取一把,每次都能精确地抓到一打12支。他在森林中目测两颗树之间的距离,和护林员用卷尺测量的结果相差无几。现在如果我们想从一张表中抓取多比数据,每一笔都是相同的数目,并且标明第几组该怎么办呢?NTILE函数提供了这个功能,他能。来看代码:
NTILE(30) over(orderby Department) as NTiles,
FirstName+''+ LastName as FullName,
Department
from HumanResources.vEmployeeDepartment
现在我们要抓取30个组的数据,并保证尽可能的保证每组数目相同。结果如下,
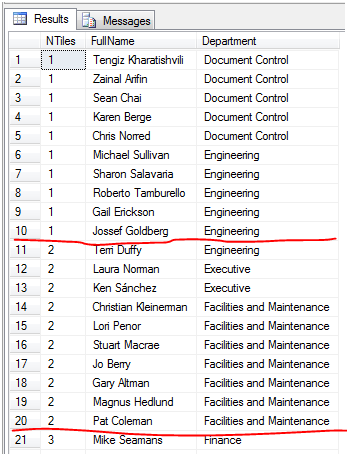
图7
这个视图中共290条数据,290/30=9.7约等于10,所以每组10条数据,如图每一条数据都有一个组号。这个结果要比索罗精确。