kaggle链接:https://www.kaggle.com/c/GiveMeSomeCredit
一、简介
kaggle上经典的风控模型:通过预测未来两年内某人将面临财务困境的可能性,提高信用评分的现有水平
1.1 比赛描述
银行在市场经济中起着至关重要的作用。他们决定谁可以获得融资以及在什么条件下获得投资决策。要使市场和社会发挥作用,个人和公司需要获得信贷。
信用评分算法,用于猜测违约概率,是银行用来确定是否应该授予贷款的方法。
该竞赛要求参与者通过预测某人在未来两年内遇到财务困境的可能性来改进信用评分的现有技术水平。
本次竞赛的目标是建立一个借款人可以用来帮助做出最佳财务决策的模型。 250,000名借款人提供历史数据,奖金池为5,000美元(第一名为3,000美元,第二名为1,500美元,第三名为500美元)。
1.2 比赛评估
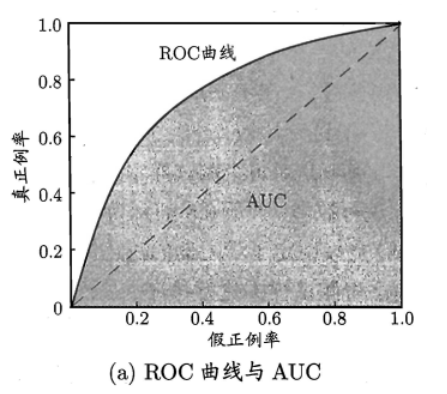
使用AUC(Area Under
ROC Curve)作为性能性能评估标准。意思是ROC曲线下的面积
ROC全称是受试者工作特征。横坐标是假正例率(False Positive
Rate),纵坐标是真正例率(True Positive
Rate)

1.3 数据描述
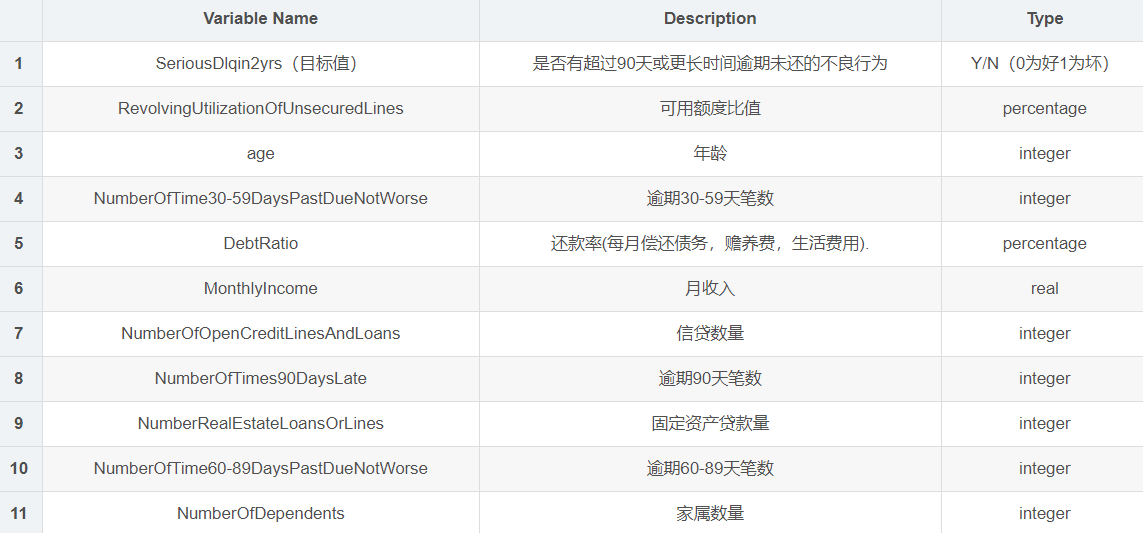
数据字典(取自Data Dictionary.xls文件):
在这里讲一下,kaggle每个竞赛都会提供
- 数据字典(可能是在介绍中也可能是单独提供一个数据字典文件,就像这个案例一样)
- 一个训练集
- 一个测试集(不含目标值)
- 一个提交文件的示例(本案例就是sampleEntry.csv文件)
2、代码
#获取数据 import os import zipfile from six.moves import urllib FILE_NAME = "GiveMeSomeCredit.zip" #文件名 DATA_PATH ="datasets/GiveMeSomeCredit" #存储文件的文件夹,取跟文件相同(相近)的名字便于区分 DATA_URL = "https://github.com/824024445/KaggleCases/blob/master/datasets/" + FILE_NAME + "?raw=true" def fetch_data(data_url=DATA_URL, data_path=DATA_PATH, file_name=FILE_NAME): if not os.path.isdir(data_path): #查看当前文件夹下是否存在"datasets/GiveMeSomeCredit",没有的话创建 os.makedirs(data_path) zip_path = os.path.join(data_path, file_name) #下载到本地的文件的路径及名称 # urlretrieve()方法直接将远程数据下载到本地 urllib.request.urlretrieve(data_url, zip_path) #第二个参数zip_path是保存到的本地路径 data_zip = zipfile.ZipFile(zip_path) data_zip.extractall(path=data_path) #什么参数都不输入就是默认解压到当前文件,为了保持统一,是泰坦尼克的数据就全部存到GiveMeSomeCredit文件夹下 data_zip.close() fetch_data() import pandas as pd import numpy as np train_df = pd.read_csv("datasets/GiveMeSomeCredit/cs-training.csv") test_df = pd.read_csv("datasets/GiveMeSomeCredit/cs-test.csv") combine=[train_df, test_df] train_df.head() train_df.info() test_df.info() train_df.describe() import matplotlib.pyplot as plt import seaborn as sns #查找关联 corr_matrix = train_df.corr() print(corr_matrix["SeriousDlqin2yrs"].sort_values(ascending=False)) #fig, ax = plt.subplots(figsize=(12,12)) #sns.heatmap(corr_matrix,xticklabels=corr_matrix.columns,yticklabels=corr_matrix.columns,annot=True) #数据处理 #缺失值处理 for data in combine: data["MonthlyIncome"].fillna(data["MonthlyIncome"].mean(), inplace=True) data["NumberOfDependents"].fillna(data["MonthlyIncome"].mode()[0], inplace=True) train_df.info() #异常值处理 train_df.NumberOfDependents.value_counts() #(家属数量居然有6670的,而且数量还不少,占到了2.6%,用0填补,因为大部分是0) #填补前先看一下家属数和目标值的相关性,以便看一下效果,没处理前相关度-0.013881 for data in combine: data["NumberOfDependents"][data["NumberOfDependents"]>30] = 0 train_df.corr()["SeriousDlqin2yrs"]["NumberOfDependents"] #修改异常值后"NumberOfDependents"的相关性达到了0.046869 train_df = train_df[train_df["age"]>18] test_df = test_df[test_df["age"]>18] combine = [train_df, test_df] #结合已有特征,创建新特征 for data in combine: data["CombinedDefaulted"] = data["NumberOfTimes90DaysLate"] + data["NumberOfTime60-89DaysPastDueNotWorse"] + data["NumberOfTime30-59DaysPastDueNotWorse"] data.loc[(data["CombinedDefaulted"] >= 1), "CombinedDefaulted"] = 1 data["CombinedCreditLoans"] = data["NumberOfOpenCreditLinesAndLoans"] + data["NumberRealEstateLoansOrLines"] data["CombinedCreditLoans"] = data["NumberOfOpenCreditLinesAndLoans"] + data["NumberRealEstateLoansOrLines"] data.loc[(data["CombinedCreditLoans"] <= 5), "CombinedCreditLoans"] = 0 data.loc[(data["CombinedCreditLoans"] > 5), "CombinedCreditLoans"] = 1 #查看新建特征效果如何 train_df.corr()["SeriousDlqin2yrs"][["CombinedDefaulted", "CombinedCreditLoans"]] #模型和预测 #数据集要再切分一下,前面的test是用来最终测试的,没有目标值,提交到kaggle之后它会返回给你一个AUC成绩,相当于评价泛化能力。而现在首先要自己评价当前模型 attributes=["SeriousDlqin2yrs", 'age','NumberOfTime30-59DaysPastDueNotWorse','NumberOfDependents','MonthlyIncome',"CombinedDefaulted","CombinedCreditLoans"] sol=['SeriousDlqin2yrs'] attributes2 = ["Unnamed: 0", 'age','NumberOfTime30-59DaysPastDueNotWorse','NumberOfDependents','MonthlyIncome',"CombinedDefaulted","CombinedCreditLoans"] sol=['SeriousDlqin2yrs'] train_df = train_df[attributes] test_df = test_df[attributes2] #####训练模型 import time import os from sklearn.model_selection import cross_validate class Tester(): def __init__(self, target): self.target = target self.datasets = {} self.models = {} self.cache = {} # 我们添加了一个简单的缓存来加快速度 def addDataset(self, name, df): self.datasets[name] = df.copy() def addModel(self, name, model): self.models[name] = model def clearModels(self): self.models = {} def clearCache(self): self.cache = {} def testModelWithDataset(self, m_name, df_name, sample_len, cv): if (m_name, df_name, sample_len, cv) in self.cache: return self.cache[(m_name, df_name, sample_len, cv)] clf = self.models[m_name] if not sample_len: sample = self.datasets[df_name] else: sample = self.datasets[df_name].sample(sample_len) X = sample.drop([self.target], axis=1) Y = sample[self.target] s = cross_validate(clf, X, Y, scoring=['roc_auc'], cv=cv, n_jobs=-1) self.cache[(m_name, df_name, sample_len, cv)] = s return s def runTests(self, sample_len=80000, cv=4): # 在所有添加的数据集上测试添加的模型 scores = {} for m_name in self.models: for df_name in self.datasets: # print('Testing %s' % str((m_name, df_name)), end='') start = time.time() score = self.testModelWithDataset(m_name, df_name, sample_len, cv) scores[(m_name, df_name)] = score end = time.time() # print(' -- %0.2fs ' % (end - start)) print('--- Top 10 Results ---') for score in sorted(scores.items(), key=lambda x: -1 * x[1]['test_roc_auc'].mean())[:10]: auc = score[1]['test_roc_auc'] print("%s --> AUC: %0.4f (+/- %0.4f)" % (str(score[0]), auc.mean(), auc.std())) from sklearn.ensemble import RandomForestClassifier from sklearn.linear_model import LogisticRegression # 我们将在所有模型中使用测试对象 tester = Tester('SeriousDlqin2yrs') # 添加数据集 tester.addDataset('Drop Missing', train_df.dropna()) # 添加模型 rfc = RandomForestClassifier(n_estimators=15, max_depth = 6, random_state=0) log = LogisticRegression() tester.addModel('Simple Random Forest', rfc) tester.addModel('Simple Logistic Regression', log) #('Simple Random Forest', 'Drop Missing') --> AUC: 0.8519 (+/- 0.0046) #('Simple Logistic Regression', 'Drop Missing') --> AUC: 0.6511 (+/- 0.0078) # 测试 tester.runTests()
#上面测试结果 随机森林 AUC高 X_train = train_df.drop(['SeriousDlqin2yrs'], axis=1) Y_train = train_df['SeriousDlqin2yrs'] X_test = test_df.drop(["Unnamed: 0"], axis=1) rfc.fit(X_train, Y_train) Y_pred = rfc.predict_proba(X_test)
#kaggle提交结果 submission = pd.DataFrame({ "Id": test_df["Unnamed: 0"], "Probability": pd.DataFrame(Y_pred)[1] }) submission.to_csv('submission.csv', index=False)