在同一级目录下新建 p1.py 和 run.py,添加代码


# p1.py 模块的设计者
def f1():
print("from f1")
def f2():
print("from f2")
def f3():
print("from f3")
# run.py 模块的使用者
import p1
p1.f1()
p1.f2()
p1.f3()
假设后期需要添加许多功能,可能添加的功能与已有的功能之间还有关联,这对于模块的设计者是很不方便的,于是设计者创建多个文件,把相关的功能放入同一个文件,这里我添加m1.py,m2.py,m3.py,将f1,f2,f3分别放入相关的功能文件
# m1.py
def f1():
print("from f1")
# m2.py
def f2():
print("from f2")
# m3.py
def f3():
print("from f3")
但这样对于使用者来说又不方便了,原先的使用方式固然已经改变,于是新建一个p1的文件夹,将m1.py,m2.py,m3.py放入p1,这样对于使用者看起来还是只有一个模块,使用的时候还是p1.f1(),p1.f2(),p1.f3()等
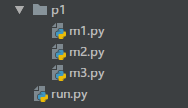
以前导入的p1是一个模块,现在导入的 p1 是一个文件夹(包),于是现在的问题是将这个包能够像之前的模块一样能够被导入和使用
一、什么是包
包就是一个包含有 __init__.py 文件的文件夹,本质就是一种模块,即包是用包导入使用的,包内部包含的文件也都是用来被导入使用
二、为何要用包
包是文件夹,那文件夹就是用来组织文件的
三、包的使用
首次导入包,发生三件事:
1、以包下的 __init__.py 文件为基准来产生一个名称空间
2、执行包下的 __init__.py 文件的代码,将执行过程中产生的名字都放入名称空间中
3、在当前执行文件中拿到一个名字,该名字就是指向__init__.py 名称空间的
注意:
1、在python3中,即使包下没有 __init__.py 文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错
2、创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包即模块
新建包 p1 和 run.py,在包下新建 m1.py,在 m1.py 中添加代码
# m1.py
def f1():
print('m1.f1')
现在我想在 run.py 中通过 p1.f1() 调用到 m1 中 f1 的功能,但此时是调用不到的,因为通过 p1 调用 f1 就是通过 __init__.py 调用 f1,__init__.py 中是没有 f1 的,f1 是在 m1 中,所以要在 __init__.py 中导入 m1,首先不能直接 import m1,因为还需要拿到 m1 下的 f1 功能,于是可能有人会想,那我直接 from m1 import f1 就行了,但这样也是不行的,因为内存中没有 m1,内置模块也没有 m1,于是在 sys.path 中查找,sys.path 是以执行文件是 run.py 为准,run.py 的 sys.path 的第一个值是上一级目录,这个目录中并没有 m1 模块(m1在p1中),所以直接 from m1 import f1 报错
又有人会想,那我把 m1 模块所在的文件夹(p1)添加到 sys.path 不就行了,于是我在 run.py(sys.path是以执行文件是run.py为准)中添加环境变量
import sys
sys.path.append(r'E:Pythonp1')
import p1
p1.f1()
这样做确实能够实现在 run.py 中通过 p1.f1() 调用到 m1 中 f1 的功能,但是这对于使用者来说是很不方便的,每次都要添加内部功能所在文件夹的环境变量,所以这样做也是不合适的。
可以在 __init__.py 中以 p1.m1 的方式导入 f1,这样在 run.py中就可以直接导入 p1 然后 p1.f1() 执行
# __init__.py
from p1.m1 import f1
# run.py
import p1
p1.f1()
假设 run.py 和 p1 不在同一级目录下,现在我新建一个 dir1,在 dir1 下新建一个 dir2,将 p1 放入 dir2,那这时在执行 run.py 时,就需要在 run.py 中添加环境变量了,有人可能有疑问,上面不是说添加环境变量不方便使用者吗,注意,我在这里添加的环境变量不是 p1 内部功能所在文件夹的环境变量,而是找到 p1 所在文件夹的环境变量,这就相当于用户下载这个程序自己选择的保存位置,在这个位置下可以找到 p1。所以我在这里只需将 dir2 的位置添加到环境变量即可
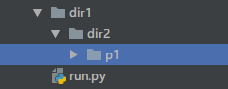
# run.py
import sys
sys.path.append(r'E:Pythondir1dir2')
import p1
p1.f1()
上面的导入也称之为绝对导入,每次都是参考执行文件的 sys.path 开始去导入
软件每次更新都有不同的版本,设计者也需要将包改名,例如 p1_v1,p1_v2 等,如果使用的是绝对导入,那包内其它的导入都需要改变一次,所以包内的模块不应该使用绝对导入,应该使用相对导入
所以,在本片博客开始留下一个问题,将包像模块一样能够被导入和使用,于是在 p1 下新建一个 __init__.py 文件,使用相对导入
# __init__.py
from .m1 import f1
from .m2 import f2
from .m3 import f3
然后直接在 run.py 中导入 p1 便可以模块一样被使用
# run.py 模块的使用者
import p1
p1.f1()
p1.f2()
p1.f3()
现在我在同一级目录新建一个包 p1 和 run.py,在 p1 下新建包 p2,m1.py 和 m2.py,在包 p2 下新建 m3.py

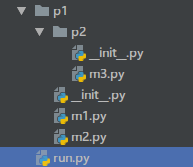
# m1.py
def f1():
print('m1.f1')
# m2.py
def f2():
print('m2.f2')
# m3.py
def f3():
print('m3.f3')
现在还是想实现与博客开始相同的功能,通过 p1.f1(),p2.f2(),p3.f3() 访问功能,做法也与上面的相同,在 p1 的 __init__.py文件中导入相关模块即可
# p1的__init__.py
from .m1 import f1
from .m2 import f2
from .p2.m3 import f3
现在我想在 m3.py 的 f3 中访问到 f1 和 f2,于是在 m3 中需要导入 m1 和 m2
# m3.py
from ..m1 import f1
from ..m2 import f2
def f3():
print('m3.f3')
f1()
f2()
这时候即便 p1 改名 p1_v1,在 run.py 中导入调用 f3,包内的导入也无需改名
# run.py
import p1_v1
p1_v1.f3()
总结:
1. 无论是 import 形式还是 from...import 形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法,点的左边都必须是一个包
2、包的本质就是一个包含 __init__.py 文件的目录,导入包就是在导包下的 __init__.py 文件
3、如果使用绝对导入,绝对导入的起始位置都是以包的顶级目录为起始点。但是包内部模块的导入通常应该使用相对导入,用一个点代表当前所在的文件(而非执行文件),两个点代表上一级,需要强调的是,相对导入只能在包内部的模块之间互相导入使用,使用多个点往上查找时不能超出顶级包