爬虫
概念:编写程序模拟浏览器上网,让其去互联网上获取数据的过程
- 通用爬虫:一整张页面
- 聚焦爬虫:页面中局部的内容
反爬机制:对应的载体是门户网站
反反爬策略:对应的载体是爬虫程序
robots 协议:“防君子不防小人”
User-Agent:请求载体的身份标识
requests 模块
requests 模块代码编写的流程
- 指定 URL
- 发起请求
- 获取响应对象中的数据
- 持久化存储
import requests
# 指定URL
url = 'https://www.sogou.com/'
# 发起请求
response = requests.get(url=url)
# 获取响应对象中的数据
page_text = response.text # response.text是字符串
# 持久化存储
with open('./sougou.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
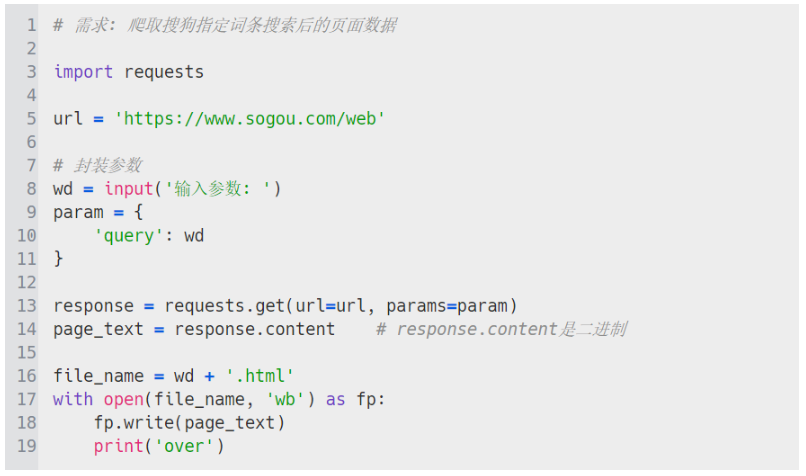
需求:爬取搜狗指定词条搜索后的页面数据
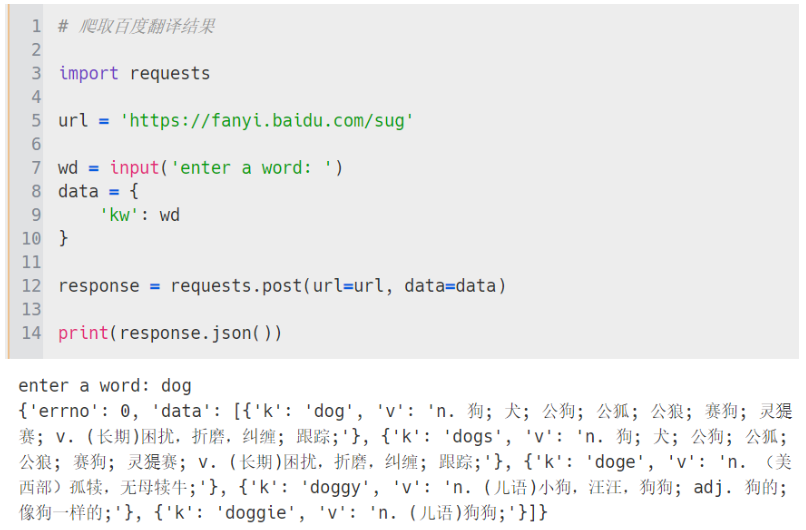
需求:爬取百度翻译结果(百度翻译是一个局部的页面刷新,因此发起的是一个基于 ajax 的异步请求)
response.text :返回字符串格式
response.content :返回二进制格式
response.json() :返回 json 格式(要保证返回是 json 数据才能调用该方法)
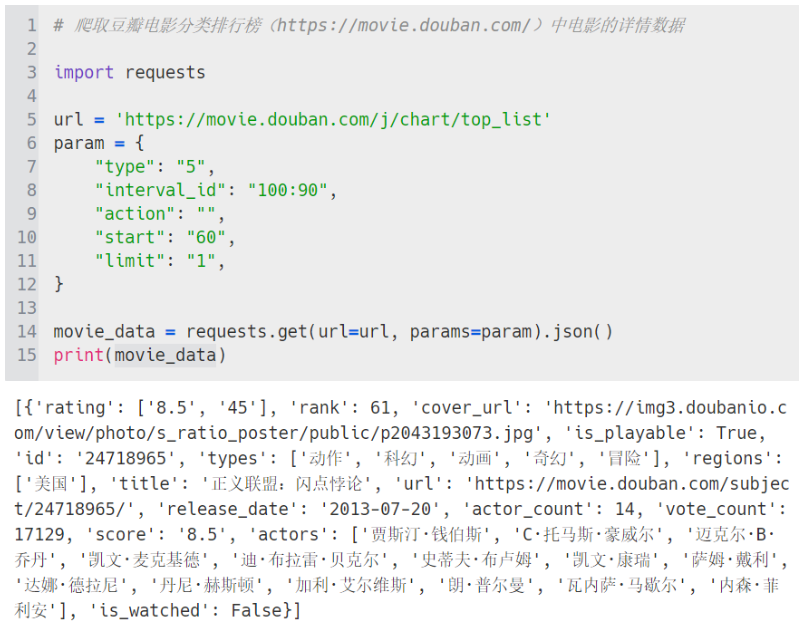
爬取豆瓣电影分类排行榜(https://movie.douban.com/)中电影的详情数据
豆瓣电影在鼠标滚轮下滑时会自动刷新更多的电影,也是局部页面的 ajax 请求
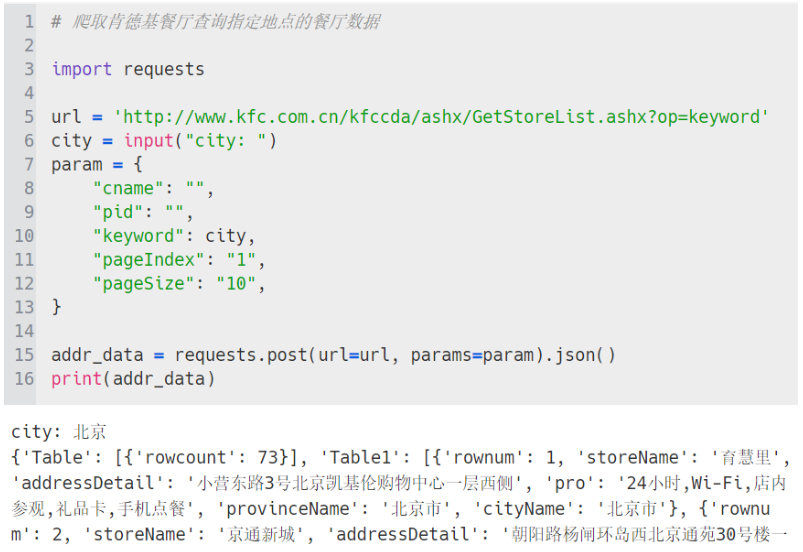
爬取肯德基餐厅查询(http://www.kfc.com.cn/kfccda/index.aspx)中指定地点的餐厅数据
爬取国家药品监督管理总局中基于中国化妆品生产许可证相关数据(http://125.35.6.84:81/xk/)
每家公司都是一个跳转页面,因此要拿到这些跳转的 a 标签,因为要获取的是点击 a 标签中的详细信息。点击翻页时 URL 并没有变化,因此是 ajax 请求,但是在获取到响应对象的数据时,数据中并没有 a 标签。但是这些数据中有 ID
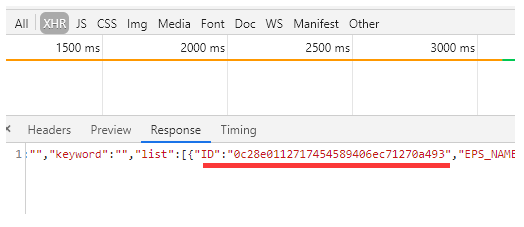
当点进这些 a 标签进入详情页时,该页的 URL 也并不能获取到详细信息,因此这些详细信息是动态加载出来的,目前所掌握的动态加载只有 ajax,在 Response 中就是该企业的详情信息,发现该 URL 携带的参数是一个 ID,也就是上面所获取的 ID,可以使用循环获取每一个 ID

'''
循环产生字典作为请求的参数,使用 requests 发的是 post 请求
会用到第三个参数 headers,这个参数涉及到 User-Agent,它是请求载体的身份标识
也就是说使用浏览器发请求和使用 requests 发请求,对应的请求载体不同,即身份标识不同
大部分的网站都会检测对应请求的身份标识,正常用户访问都会通过浏览器发起请求
这里使用的是爬虫程序,它发的载体就不是基于某一款浏览器
如果使用 requests 发请求,服务器端是可以检测对应请求的身份标识,可能就拿不到想要的数据
反爬机制:UA(User-Agent)检测 ----> UA 伪装
可以对当前使用 requests 发的请求载体进行伪装成基于某一浏览器的
这里的 headers 就是请求头信息
'''
import requests
url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"
}
id_list = []
for page in range(1, 11):
data = {
"on": "true",
"page": str(page),
"pageSize": "15",
"productName": "",
"conditionType": "1",
"applyname": "",
"applysn": "",
}
json_data = requests.post(url=url, data=data, headers=headers).json()
for dic in json_data['list']:
id = dic['ID']
id_list.append(id)
detail_url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById'
for id in id_list:
detail_data = {
"id": id
}
detail_json = requests.post(url=detail_url, data=detail_data, headers=headers).json()
print(detail_json)
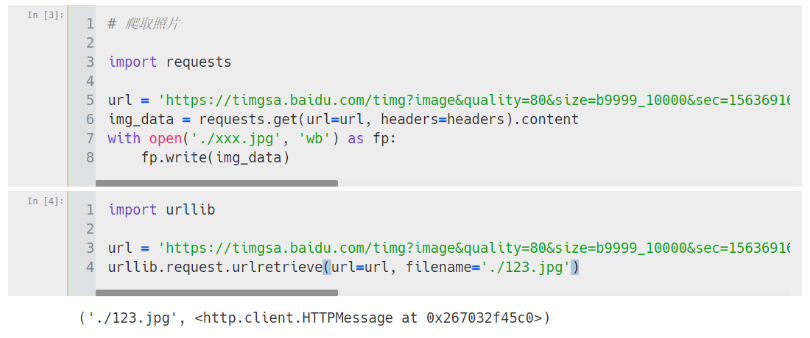
图片爬取