1、概念
在传统Linux集群种类,主要分了三类,一类是LB集群,这类集群主要作用是对用户的流量做负载均衡,让其后端每个server都能均衡的处理一部分请求;这类集群有一个特点就是前端调度器通常是单点,后端server有很多台,即便某一台后端server挂掉,也不影响用户的请求;其次就是HA集群,所谓ha集群就是高可用集群,这类集群的主要作用是对集群中的单点做高可用,所谓高可用就是在发生故障时,能够及时的将故障转移,从而使故障修复时间最小;这类集群的特点是在多台节点上,各空闲节点会一直盯着工作节点,工作节点也会基于多播或广播的方式把自己的心跳信息发送给其他空闲节点,一旦工作节点的心跳信息在一定时间内空闲节点没有收到,那么此时就会触发资源抢占,先抢到资源的成为新的工作节点,而其他节点又会一直盯着新的工作节点,直到它挂掉,然后再次触发资源抢占;这类集群的特点就是一个节点工作,其他节点看着它工作,一旦工作节点挂了,立刻会有其他节点上来顶替它的工作;最后就是HP集群,HP集群主要用于在复杂计算中场景中,把多台server的算力综合一起,对复杂计算要求比较高的环境中使用;在生产环境中常见的LB和HA集群较多;
2、衡量系统的可用性
A=MTBF/(MTBF+MTTR)
MTBF(Mean Time Between Failure)平均无故障工作时间;MTTR(Mean Time to Repair)平均修复时长;也就是说衡量一个系统的可用性是系统无故障运行时间除以系统无故障运行时间+故障修复时间;我们知道一个系统完全没有故障,这是不可能的,这也意味着A的取值是小于1;如果说一个系统的可用性为0,那么我们会认为该系统没有任何用,所以系统可用性通常是大于0小于1,通常我们用一个百分比来描述系统的可用性;从上面的公式,如果我们要提升系统的可用性我们有两种办法,第一种就是无限提升mtbf的值,让mtbf的值大到可以忽略mttr的值,当然这种方式理想中可行,在现实中,我们的系统一旦发生故障,修复的时间都不会是很少,也就说这种增大MTBF的方式,不是可行的;其次就是降低MTTR的值,降低MTTR的值就是缩短故障修复时间;通常我们降低MTTR的方式是通过冗余主机的方式;就是在容易发生故障的关键性业务上,提前给它配置好相同的服务,然后这台空闲的server就一直盯着工作的server,一旦工作server发生故障,此时空闲的server就立刻把工作的server的IP 地址给抢过来,然后把服务启动了,后端如果有共享存储,此时把共享存储挂载到自己对应的目录;如果有必要我们还需要通过某些机制让之前的server“爆头”,以免发生死灰复燃的场景;
3、HA解决方案
我们知道高可用的是服务,但是通常一个服务该有的多组件也会高可用,比如httpd服务,对于httpd对外它一定会有一个ip地址在对外提供服务,其次就是httpd服务自身的进程,如果业务需要,我们可能还会用到共享存储;通过上述描述,对于高可用httpd服务,我们需要在备份节点上对httpd的ip地址做高可用,服务进程,以及后端的共享存储;对于ip地址的高可用通常是在备份节点上探测到活动节点故障时,第一时间把活动节点的ip地址配置到备份节点上,通常这个ip地址是一个虚拟的ip地址,所以我们叫它vip;对应用程序进程的高可用,通常是我们在备份节点上直接把对应服务提前启动起来;后端共享存储的高可用也是通过某种机制探测活动节点发生故障后,然后把共享存储挂载到备份节点,使得整个httpd服务可用;我们把httpd从一个节点迁移到另一个节点的过程叫故障转移(failover);这里需要注意,在发生故障转移后,之前活动节点有可能发生故障恢复的情况,此时为了不让之前活动的节点对现有的服务资源发生争用,我们在发生故障转移时,应该让其之前的节点“死”的更彻底一些,我们会让备份节点对活动节点“开一枪”,让发生故障的节点更彻底的故障;这种是为了避免资源争用而导致服务的不可用;
vrrp协议的实现:keepalived
基于OpenAIS规范的实现:corosync;所谓AIS(application interface standard)是指用来定义应用程序接口标准,openais就是开放的应用程序接口标准,它是有SA Forum发布的一套规范;这些规范的主要目的就是为了提高中间件可移植和应用程序的高可用;
4、corosync+pacemaker架构
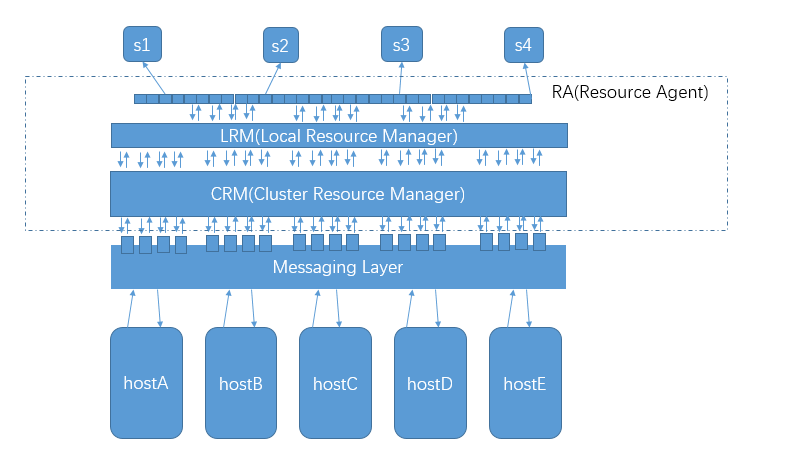
corosync的主要作用是提供messaging Layer,这个消息传递层的主要作用是,把个主机间的各状态信息,空闲信息等等一系列信息通过消息传递层互相传递,使得托管在corosync上的服务能够根据底层各主机传递的消息来决定该服务该运行到那台主机上,一旦运行的服务所在主机发生故障时,它们又能够根据消息传递层的消息来判断该把服务迁移到那台主机上运行;这样一来托管在corosync上的服务能够高可用;简单点讲,托管在corosync之上的服务对底层主机上不可见的,这也意味着托管在corosync上的服务是能够调用和理解Messaging Layer中的消息;这样一来托管在上面的服务就必须得提供接口来调用messaging Layer对外提供的接口,然后实现服务的迁移;而对于大多数程序来讲,它根本就没有这样的接口,这样一来我们要使用corosync实现服务高可用变得困难;为了解决托管在corosync的服务能够调用corosync提供的接口,我们需要开发一个中间件,让这个中间件能够向下理解和调用coroysnc提供的接口,向上能够托管服务;这个中间层就是pacemaker;它的主要作用是通过调用corosync提供的接口,来判断把集群资源该怎么分配,服务该怎么迁移和运行;同时pacemaker还提供一个管理界面,能够让管理员来管理这些集群资源;而对于pacemaker来讲,它主要有3各层次,其中CRM(cluster resource manager)的主要作用是通过调用messaging Layer提供的接口和各节点的状态信息来决策集群资源的管理;然后通过接口把决策信息传递给LRM(local resource manager);LRM的主要作用是对本地的资源做各种管理;而对于LRM来讲,它要怎么管理本地资源呢?它通常不会自己去管理本地的资源,而是通过RA去管理,所谓RA(resource agent)就是资源代理;它会根据LRM发送的信息来对本地的资源进行管理,而这种管理通常是基于各种服务提供的起停脚本来实现的;比如,我们要把httpd服务托管在corosync+pacemaker这个架构上,首先我们得提供一个管理httpd的服务的脚本,比如centos7上的httpd.service,centos6上的/etc/init.d/httpd来实现;而这些脚本通常在我们使用yum安装都会提供,这样一来,我们要托管httpd服务就变得尤为简单,我们只需要在pacemaker上配置,把httpd识别成集群资源即可;只要配置httpd为集群的资源,此时我们就可以在各主机上迁移httpd服务来实现httpd服务的高可用;要实现httpd服务在各节点主机上迁移,我们需要要注意各主机上必须有httpd服务;对于其他服务也是同样的逻辑;简单讲corosync主要提供底层各主机消息状态,集群状态信息,而pacemaker主要对托管在其上的服务进行管理;当然pacemaker也可以通过调用corosync的接口来管理底层的主机,比如让某一台主机下线上线等等操作;
5、corosync集群的投票系统
在集群发生网络分区以后,怎样确定该那一方继续代表集群工作呢?所谓集群分区就表示,集群中的某一台主机或一些主机不能检测到其他主机的心跳;当集群发生分区以后,到底哪一方能够继续代表集群工作呢?如果是2台主机组成的集群,当其中一台host不能够正常检测到另一台host的心跳时,它们都会认为对方故障了,此时就会存在一个资源争用的问题,A认为B挂了,B认为A挂了,此时集群资源就会来回在A和B上飘动,使得整个服务都不可用;为了解决这样的问题,我们必须有一个系统来来决定到底谁该代表集群工作;通常情况在一个分布式集群中,投票系统尤为重要,它决定了整个集群是否能够正常工作;假如我们的集群有3台主机组成,当其中一台主机挂掉了,那么到底谁来代表集群工作呢?如果是A那么整个集群将不可用,那么是B C,谁来当领导呢?这个时候就需要投票系统来决策了;默认情况我们的集群各host都会有选票在自己手中,当发生分区以后,各host会根据自己检测到的心跳信息发送给集群其他节点,根据选票的数量来决定谁故障了,谁能够代表集群工作,如上面的例子,如果A挂了,那么B会把对A的检测的心跳信息,发送给C,然后C也会把对A的检测心跳信息发送给B,此时投票就是A挂了2票,而整个集群总共3票,已经有过半的选票都认为A挂了,那么A此时就不会继续代表集群工作了;剩下的B和C可继续代表集群工作;我们把能够继续代表集群工作的一方叫with quorum,就是选票大于总选票一半的一方;而对于选票小于或等于总选票的一方我们称为without quorum;此时A就是without quorum一方,它会遵循no_quorum_policy指定的行为,通常no_quorum_policy默认是stop行为,意思就是without quorum一方会停止代表集群工作,当然它还有ignore、suicide、freeze行为;ignore表示忽略自己是without quorum一方的选票结果,继续代表集群工作,suicide表示自杀,就是一旦不是with quorum一方就自我毁灭,freeze表示冻结,所谓冻结就是继续服务老的请求,拒绝新的请求;B和C就是with quorum一方,它们会利用某种机制来挑选一个领导,然后根据消息传递层的消息决定把A上的资源抢过来跑在那个节点上继续代表集群工作;而对于BC来讲它们只是联系不到A,A是否真的挂了呢?如果A没有真的挂,那么BC此时把A上的ip地址抢过来,继续代表集群工作,A可能再把ip地址抢过去,这样一来集群就不能够正常工作,为了解决BC的后顾之忧,BC会通过其他机制把A干掉(比如爆头,stonith机制“shoot the other node in the head”),让A即便是存活的也让其挂掉,这样做的目的就是为了保证集群资源不再受A的干扰,正常提供服务;在corosync+pacemaker这种架构中,领导的角色称为DC(disignated coordinator指派的协调员);DC的主要作用是接收管理员的配置信息和更新集群各状态事务信息,并指派对应节点上的LRM对其集群资源操作,并通过消息传递层把管理配置信息同步给集群其他节点;这样一来,在下一次集群发生分区以后,能够在集群其他节点上选出新的DC,从而继续代表集群工作;集群中的各状态事务、配置信息,通常保存在CIB(cluster information base)中,而对于CIB中的各状态事务信息由DC去更新,然后再同步到集群各节点中去;通常DC节点上会运行CRM、CIB、PE(policy engine)、LRM这四个组件;而非DC节点会运行CRM、CIB、LRM这三个组件;而PE的作用就是调度指挥DC把配置信息应用后的结果通过消息传递层发送给其他非DC节点并保存至各非DC节点的CIB中;
6、资源类型
在corosync+pacemaker架构上,最为核心的就是资源,前边说了那么多,最终目的是为了管理托管在上面的资源;而对于资源来讲资源是有类型的;简单讲就是可以用来调配的服务称为资源,比如一个httpd服务,一个ip地址,一个后端共享存储等等,这些都叫做资源;而对于一个完整的服务来讲,它是由多个单一的资源组合而成;比如一个完整的httpd服务它应该由ip地址、httpd服务进程、在特殊场景中很有可能会有后端共享存储;而这些资源在corosync+pacemaker上每个资源是有类型的,不同的类型运行方式个不相同;
primitive:基本资源,主资源;通常仅能运行为一份,运行在单个节点上的资源;
group:组;将一个或多个资源组织成一个可统一管理的单一单位资源;什么意思呢?默认情况托管在corosync+pacemaker上的资源会负载均衡的运行在多个主机之上,如果我们不将这些资源逻辑的关联在一起,就会存在,ip地址在A主机上,服务进程在B主机上,后端存储在C主机上,这样一来,我们托管的服务就没有办法向外提供服务,为了解决各依赖资源分散的问题,我们需要将多个有关联依赖的资源逻辑的组织成一个组,然后根据这个组为单位进行调度和管理;
clone:克隆;一个资源可以在集群中运行多个副本,可以运行于多个节点;
mutil-state(master/slave):是clone类型的资源的特殊表现,可以存在多个副本,副本间存在主从关系;
7、资源倾向性
什么叫资源倾向性呢?我们知道一个资源托管在corosync+pacemaker上,最终都会把资源落在某一个节点上运行,而我们怎么来限制这些资源在那个或那些各节点上运行呢?这个就需要我们配置资源对节点的倾向性了;所谓倾向性就是该资源更加倾向在那个节点运行或更加讨厌在那个几点上运行;在corosync+pacemaker集群上运行资源的方式有3中,N-1、N-M、N-N,其中N表示节点数量,M表示资源数量;N-1表示N个几点上运行1各资源;这也意味这有N减1各节点上处于空先状态,这对于服务器的资源利用率有点浪费;所以对于corosync+pacemaker集群和keepalived来讲,keepalived更加轻量化;N-M表示N个几点上运行M个资源通常M小于N;这意味着有N减M个节点冗余;N-N表示N个节点上运行N个资源,没有冗余节点,这意味着一旦一个资源挂掉,那么对应就会迁移到其他节点,对于其他节点迁移到的节点只要提供的ip地址,进程,端口不冲突就不会有很大的问题,只不过相对压力要大一点;对于不同运行方式,冗余的节点数量也是不同的;而对于资源该运行到那个节点我们可以通过定义资源对节点的倾向性来决定;默认情况每个资源都能够在任意节点上运行;也就说默认情况当A资源挂掉以后,它的故障转移范围是其他节点,为了不让A服务运行到B节点,我们可以定义A资源的对B资源的倾向性为负无穷,所谓负无穷就是只要有其他节点可运行就绝不在B节点上运行;通过定义资源对节点的倾向性,从而来限制资源在那些节点上进行转移;这种限制资源对节点的倾向性我们叫做定义资源的故障转移域;除了能够定义资源对节点的倾向性,我们还可以定义资源与资源的倾向性,其逻辑都是相似的;对于资源倾向性通常我们会用分数来表示,其取值范围是真无穷到负无穷;正无穷表示无限喜欢到某个节点或资源,只要对应节点正常存在就一定在该节点上,负无穷相反;
8、资源代理
所谓资源代理,就是指帮助去启动一个资源的;在corosync+pacemaker集群上,资源代理就是指的是能够帮助我们去启动一个资源的脚本或程序,对于不同的资源代理,用到的脚本或程序不同;对于不同的资源在不同的系统,资源代理的类型也有不同,比如在centos6上,各服务的启动脚本通常在/etc/init.d/下,所以通常会把/etc/init.d/目录下的各脚本当作资源代理的脚本;这种资源类型叫做LSB的资源类型,通常这些脚本都支持start|stop|restart|status等等参数;对于LSB类型的资源代理,前提是代理的资源一定不能开机启动,如果开机启动对于托管corosync+pacemaker就无意义了,所以资源的启动一定要交给corosync+pacemaker来管理不能开机启动;对于centos7来说,它使用的是systemd方式来管理各服务的启动,停止;它默认的存放unit file的路径是/usr/lib/systemd/system/目录下;而对于systemd类型的资源代理,我们一定要把托管为集群的服务 enable起来,可以理解为corosync+pacemaker它会到/etc/systemd/system/目录下对应资源启动脚本;而只有把对应服务enable来以后,它才会在/etc/systemd/system/目录下存在;除了以上两种资源代理还有OCF和stonith,OCF类型资源代理类似LSB脚本,当支持start,stop,status,monitor,mata-data等参数;stonith类型的资源代理专用配置stonith设备RA;service类型,以上4种都不符合的其他类型的资源代理;
9、corosync+pacemaker的安装配置
前提:
1、各host时间同步;
2、各hosts文件能够解析其他节点的主机名;选择一各不和其他集群冲突的多播地址;
3、有需要可配置各节点ssh互信;
| 主机名 | ip地址 | 多播地址 |
| node01 | 192.168.0.41 | 239.255.100.12 |
| node02 | 192.168.0.42 | 239.255.100.12 |
验证:各主机上的时间和主机名以及hosts文件;


提示:为这里以两主机演示特殊的两节点集群;node01和node02都把时间服务器地址指向内网192.168.0.99这个时间服务器上;有关时间服务器的配置请参考https://www.cnblogs.com/qiuhom-1874/p/12079927.html;有关ssh互信配置可以参考https://www.cnblogs.com/qiuhom-1874/p/11783371.html;
配置好时间同步和ssh户型以及host主机名解析以后,接下来安装pacemaker
[root@node01 ~]# yum install pacemaker 已加载插件:fastestmirror, langpacks base | 3.6 kB 00:00:00 docker-ce-stable | 3.5 kB 00:00:00 epel | 4.7 kB 00:00:00 extras | 2.9 kB 00:00:00 updates | 2.9 kB 00:00:00 (1/3): epel/x86_64/updateinfo | 1.0 MB 00:00:00 (2/3): epel/x86_64/primary_db | 6.9 MB 00:00:01 (3/3): updates/7/x86_64/primary_db | 4.5 MB 00:00:01 Loading mirror speeds from cached hostfile * base: mirrors.aliyun.com * extras: mirrors.aliyun.com * updates: mirrors.aliyun.com 正在解决依赖关系 --> 正在检查事务 ---> 软件包 pacemaker.x86_64.0.1.1.21-4.el7 将被 安装 --> 正在处理依赖关系 pacemaker-libs(x86-64) = 1.1.21-4.el7,它被软件包 pacemaker-1.1.21-4.el7.x86_64 需要 --> 正在处理依赖关系 pacemaker-cluster-libs(x86-64) = 1.1.21-4.el7,它被软件包 pacemaker-1.1.21-4.el7.x86_64 需要 --> 正在处理依赖关系 pacemaker-cli = 1.1.21-4.el7,它被软件包 pacemaker-1.1.21-4.el7.x86_64 需要 --> 正在处理依赖关系 libqb > 0.17.0,它被软件包 pacemaker-1.1.21-4.el7.x86_64 需要 --> 正在处理依赖关系 resource-agents,它被软件包 pacemaker-1.1.21-4.el7.x86_64 需要 --> 正在处理依赖关系 libquorum.so.5(COROSYNC_QUORUM_1.0)(64bit),它被软件包 pacemaker-1.1.21-4.el7.x86_64 需要 --> 正在处理依赖关系 libcmap.so.4(COROSYNC_CMAP_1.0)(64bit),它被软件包 pacemaker-1.1.21-4.el7.x86_64 需要 --> 正在处理依赖关系 libcfg.so.6(COROSYNC_CFG_0.82)(64bit),它被软件包 pacemaker-1.1.21-4.el7.x86_64 需要 --> 正在处理依赖关系 corosync,它被软件包 pacemaker-1.1.21-4.el7.x86_64 需要 ……省略部分内容…… 依赖关系解决 ==================================================================================================== Package 架构 版本 源 大小 ==================================================================================================== 正在安装: pacemaker x86_64 1.1.21-4.el7 base 478 k 为依赖而安装: corosync x86_64 2.4.5-4.el7 base 221 k corosynclib x86_64 2.4.5-4.el7 base 136 k libqb x86_64 1.0.1-9.el7 base 96 k pacemaker-cli x86_64 1.1.21-4.el7 base 362 k pacemaker-cluster-libs x86_64 1.1.21-4.el7 base 163 k pacemaker-libs x86_64 1.1.21-4.el7 base 637 k perl-TimeDate noarch 1:2.30-2.el7 base 52 k resource-agents x86_64 4.1.1-46.el7_8.2 updates 455 k 事务概要 ==================================================================================================== 安装 1 软件包 (+8 依赖软件包) 总下载量:2.5 M 安装大小:6.5 M Is this ok [y/d/N]: y Downloading packages: (1/9): corosynclib-2.4.5-4.el7.x86_64.rpm | 136 kB 00:00:00 (2/9): corosync-2.4.5-4.el7.x86_64.rpm | 221 kB 00:00:00 (3/9): libqb-1.0.1-9.el7.x86_64.rpm | 96 kB 00:00:00 (4/9): pacemaker-1.1.21-4.el7.x86_64.rpm | 478 kB 00:00:00 (5/9): pacemaker-cli-1.1.21-4.el7.x86_64.rpm | 362 kB 00:00:00 (6/9): pacemaker-libs-1.1.21-4.el7.x86_64.rpm | 637 kB 00:00:00 (7/9): perl-TimeDate-2.30-2.el7.noarch.rpm | 52 kB 00:00:00 (8/9): pacemaker-cluster-libs-1.1.21-4.el7.x86_64.rpm | 163 kB 00:00:00 (9/9): resource-agents-4.1.1-46.el7_8.2.x86_64.rpm | 455 kB 00:00:00 ---------------------------------------------------------------------------------------------------- 总计 2.0 MB/s | 2.5 MB 00:00:01 Running transaction check Running transaction test Transaction test succeeded Running transaction 正在安装 : libqb-1.0.1-9.el7.x86_64 1/9 正在安装 : corosynclib-2.4.5-4.el7.x86_64 2/9 正在安装 : corosync-2.4.5-4.el7.x86_64 3/9 正在安装 : pacemaker-libs-1.1.21-4.el7.x86_64 4/9 正在安装 : pacemaker-cluster-libs-1.1.21-4.el7.x86_64 5/9 正在安装 : 1:perl-TimeDate-2.30-2.el7.noarch 6/9 正在安装 : pacemaker-cli-1.1.21-4.el7.x86_64 7/9 正在安装 : resource-agents-4.1.1-46.el7_8.2.x86_64 8/9 正在安装 : pacemaker-1.1.21-4.el7.x86_64 9/9 验证中 : pacemaker-cli-1.1.21-4.el7.x86_64 1/9 验证中 : pacemaker-libs-1.1.21-4.el7.x86_64 2/9 验证中 : libqb-1.0.1-9.el7.x86_64 3/9 验证中 : corosynclib-2.4.5-4.el7.x86_64 4/9 验证中 : pacemaker-1.1.21-4.el7.x86_64 5/9 验证中 : corosync-2.4.5-4.el7.x86_64 6/9 验证中 : pacemaker-cluster-libs-1.1.21-4.el7.x86_64 7/9 验证中 : resource-agents-4.1.1-46.el7_8.2.x86_64 8/9 验证中 : 1:perl-TimeDate-2.30-2.el7.noarch 9/9 已安装: pacemaker.x86_64 0:1.1.21-4.el7 作为依赖被安装: corosync.x86_64 0:2.4.5-4.el7 corosynclib.x86_64 0:2.4.5-4.el7 libqb.x86_64 0:1.0.1-9.el7 pacemaker-cli.x86_64 0:1.1.21-4.el7 pacemaker-cluster-libs.x86_64 0:1.1.21-4.el7 pacemaker-libs.x86_64 0:1.1.21-4.el7 perl-TimeDate.noarch 1:2.30-2.el7 resource-agents.x86_64 0:4.1.1-46.el7_8.2 完毕! [root@node01 ~]#
提示:安装pacemaker会依赖corosync这个包,所以直接安装pacemaker这一个包就可以了;对于node02也是同样的操作;
配置corosync
查看corosync的程序环境
[root@node01 ~]# rpm -ql corosync /etc/corosync /etc/corosync/corosync.conf.example /etc/corosync/corosync.conf.example.udpu /etc/corosync/corosync.xml.example /etc/corosync/uidgid.d /etc/dbus-1/system.d/corosync-signals.conf /etc/logrotate.d/corosync /etc/sysconfig/corosync /etc/sysconfig/corosync-notifyd /usr/bin/corosync-blackbox /usr/bin/corosync-xmlproc /usr/lib/systemd/system/corosync-notifyd.service /usr/lib/systemd/system/corosync.service /usr/sbin/corosync /usr/sbin/corosync-cfgtool /usr/sbin/corosync-cmapctl /usr/sbin/corosync-cpgtool /usr/sbin/corosync-keygen /usr/sbin/corosync-notifyd /usr/sbin/corosync-quorumtool /usr/share/corosync /usr/share/corosync/corosync /usr/share/corosync/corosync-notifyd /usr/share/corosync/xml2conf.xsl /usr/share/doc/corosync-2.4.5 /usr/share/doc/corosync-2.4.5/LICENSE /usr/share/doc/corosync-2.4.5/SECURITY /usr/share/man/man5/corosync.conf.5.gz /usr/share/man/man5/corosync.xml.5.gz /usr/share/man/man5/votequorum.5.gz /usr/share/man/man8/cmap_keys.8.gz /usr/share/man/man8/corosync-blackbox.8.gz /usr/share/man/man8/corosync-cfgtool.8.gz /usr/share/man/man8/corosync-cmapctl.8.gz /usr/share/man/man8/corosync-cpgtool.8.gz /usr/share/man/man8/corosync-keygen.8.gz /usr/share/man/man8/corosync-notifyd.8.gz /usr/share/man/man8/corosync-quorumtool.8.gz /usr/share/man/man8/corosync-xmlproc.8.gz /usr/share/man/man8/corosync.8.gz /usr/share/man/man8/corosync_overview.8.gz /usr/share/snmp/mibs/COROSYNC-MIB.txt /var/lib/corosync /var/log/cluster [root@node01 ~]#
提示:/etc/corosync这个目录用来存放corosync配置文件;其中corosync.conf.example是corosync的文本格式配置文件示例;corosync.conf.example.udpu这个是corosync使用udpu方式提供服务的配置文件示例;corosync.xml.example是xml格式的配置文件示例;/usr/lib/systemd/system/corosync.service这个是corosync unit file文件;/usr/sbin/corosync二进制程序文件;/usr/sbin/corosync-keygen这个工具用于生成corosync的密钥文件;/var/lib/corosync这个目录主要存放CIB数据库文件;/var/log/cluster/目录用于存放日志相关文件;
复制/etc/corosync/corosync.conf.example文件为/etc/corosync.conf
[root@node01 ~]# cp /etc/corosync/corosync.conf.example /etc/corosync/corosync.conf
编辑配置文件

提示:对于totem这个配置段主要用于配置totem协议的相关属性,其中version表示使用的版本,默认是2这个不用更改,保持默认就好;下面的crypto_cipher和crypto_hash这两项用于配置是否启用加密,这里默认是none,这意味这只要是在相同多播域内,它都会识别成集群成员;所以为了安全建议启用集群事务消息通信加密;默认情况crypto_cipher支持aes256, aes192, aes128 and 3des这些加密算法,随便配置一个加密算法即可;crypto_hash支持md5, sha1, sha256, sha384,sha512这些加密算法,随便选一个即可;如果启用以上两项加密,我们需要在/etc/corosync/目录下创建一个密钥文件,且权限是600或着400的权限;并且集群各节点的密钥文件必须相同;
创建密钥文件
[root@node01 ~]# corosync-keygen Corosync Cluster Engine Authentication key generator. Gathering 1024 bits for key from /dev/random. Press keys on your keyboard to generate entropy. Press keys on your keyboard to generate entropy (bits = 920). Press keys on your keyboard to generate entropy (bits = 1000). Writing corosync key to /etc/corosync/authkey. [root@node01 ~]# ll /etc/corosync/ 总用量 20 -r-------- 1 root root 128 8月 30 23:30 authkey -rw-r--r-- 1 root root 2886 8月 30 23:30 corosync.conf -rw-r--r-- 1 root root 2881 4月 2 21:28 corosync.conf.example -rw-r--r-- 1 root root 767 4月 2 21:28 corosync.conf.example.udpu -rw-r--r-- 1 root root 3278 4月 2 21:28 corosync.xml.example drwxr-xr-x 2 root root 6 4月 2 21:28 uidgid.d [root@node01 ~]#
提示:可以现在把密钥文件复制给node02也可以待会把配置文件配置好以后一并复制给node02都行;
继续编辑配置文件
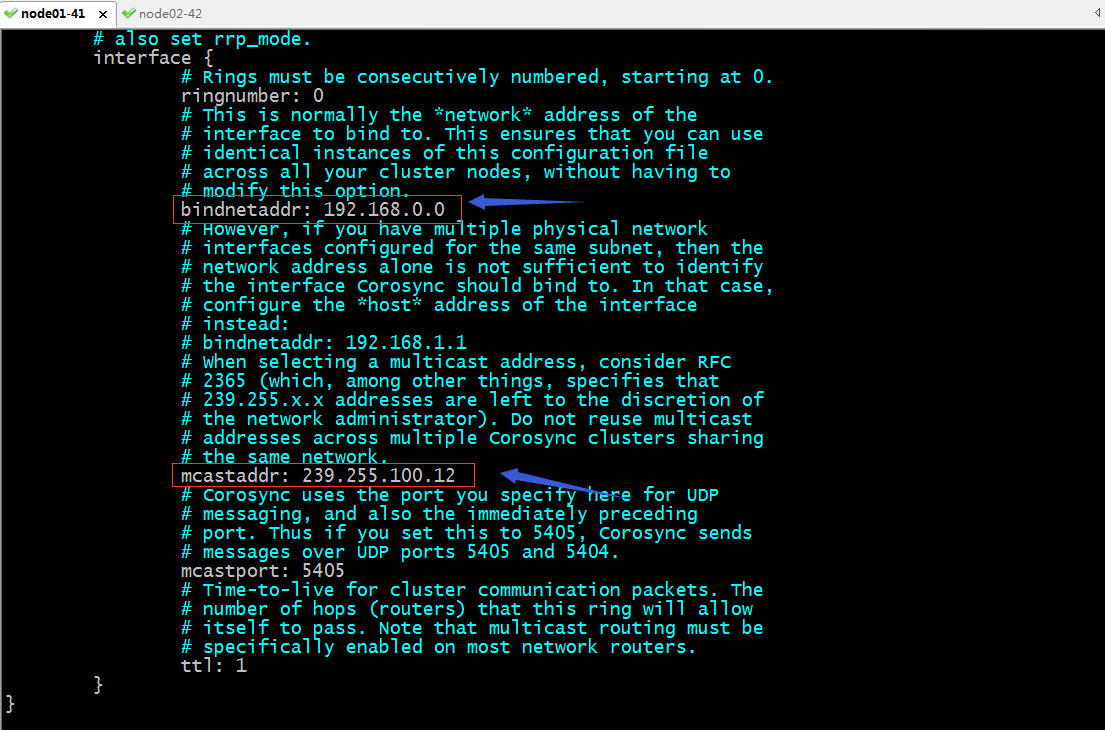
提示:interface配置段主要用于定义集群事务信息通信接口相关参数;其中ringnumber: 0表示第一块网卡,如果有第二卡和第三块,可以在totem配置段继续用interface配置段来指定;bindnetaddr: 192.168.0.0用于配置用于集群事务信息通信的网络地址,它默认会根据我们配置的网络地址去本地主机上找对应的网卡;当然我们也可以配置ip地址也行,通常建议使用网络地址;mcastaddr:是用来指定多播通信地址;这个如果在实验环境中可以不用该,只要在集群中的各节点都是同一个多播地址即可;在生产中一定要注意不能和其他集群的多播通信地址冲突;mcastport用于指定多播通信的端口,默认是5405,这个通常不需要更改,保持默认即可;ttl: 1这个是配置多播通信的报文生存时长,默认配置为1,是为了防止其他节点收到多播报文后再次转发;
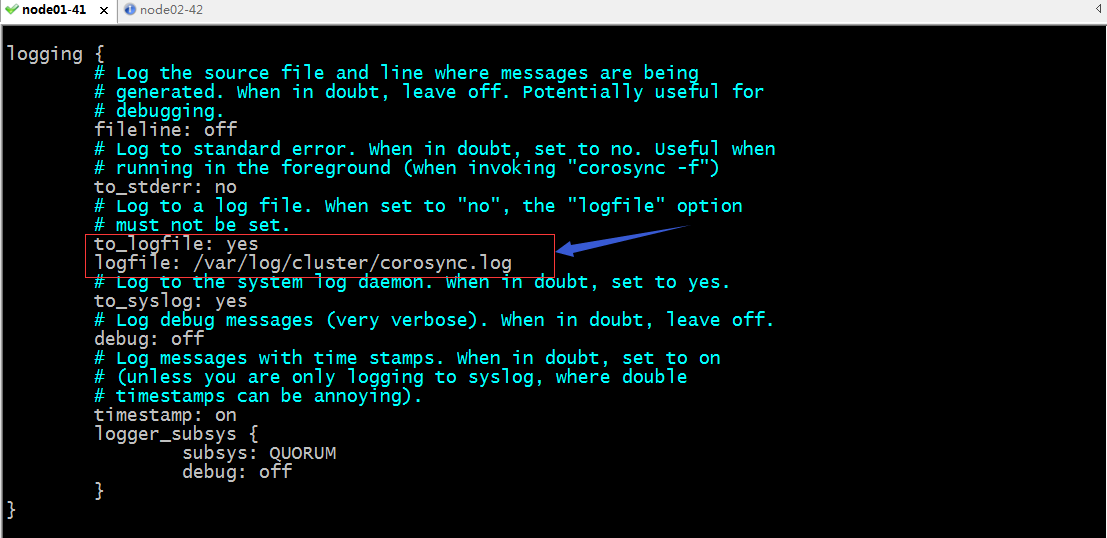
提示:logging配置段主要用于定义日志相关;其中fileline: off表示不开启fileline;所谓fileline就是记录源文件和消息所在的行; to_stderr: no表示不把日志输出到标准错误控制台;to_logfile: yes表示把日志输出到文件;logfile: /var/log/cluster/corosync.log用于指定日志文件路径; to_syslog: yes是否将日志发送给syslog,默认是允许;debug: off是否关闭调试信息;默认是关闭的;timestamp: on是否加上时间戳,默认是开启;如果我们只玩syslog中发送日志,可以将这一项关闭,因为syslog会自动将时间给我们补上;logger_subsys用于定义日志子系统,subsys指子系统的名称,debug指定是否开启调试信息;上面的subsys: QUORUM 表示开启记录quorum的日志信息;

提示:quorum用于配置投票系统相关配置,这里面默认是注释了,我们只需要打开provider: corosync_votequorum即可;

提示:nodelist这段配置在默认的配置文件中没有,我们加上这段配置就是告诉corosync我们期望的集群中的节点有两个,他们的ip地址是那些;这里的ip地址可以写主机名,也可以写ip地址,建议使用主机名;
复制/etc/corosync/corosync.conf 和authkey文件到其他节点

启动corosync
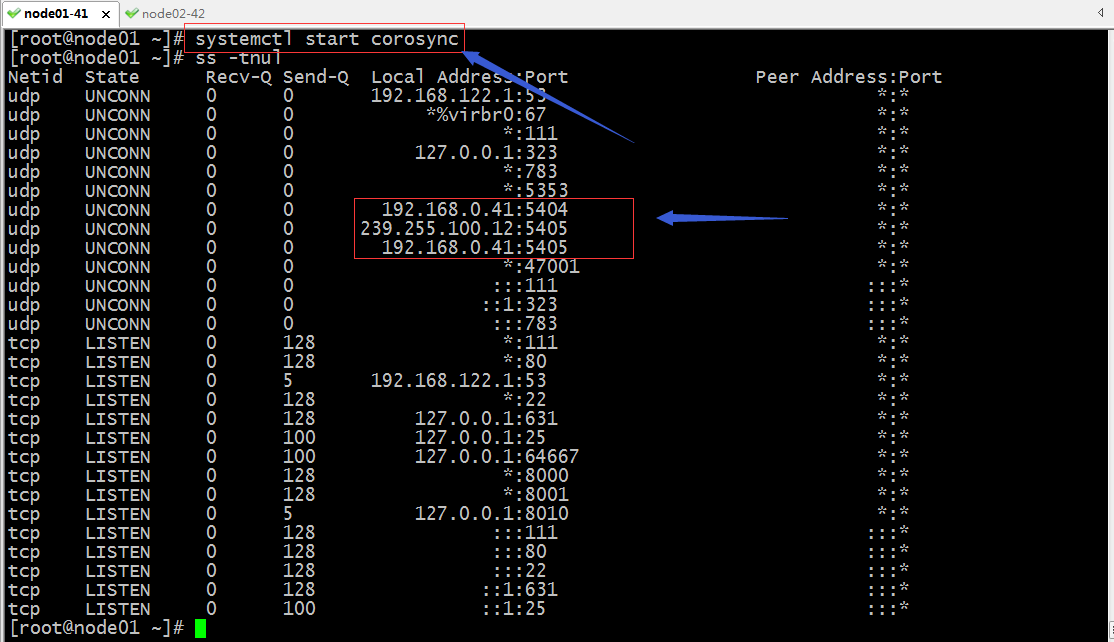

提示:如果启动corosync服务以后,能够看到udp的5405端口和5404端口处于监听状态和我们配置的多播地址,则说明corosync服务就配置好了;
验证:查看corosync的日志,看看是否识别到两个节点
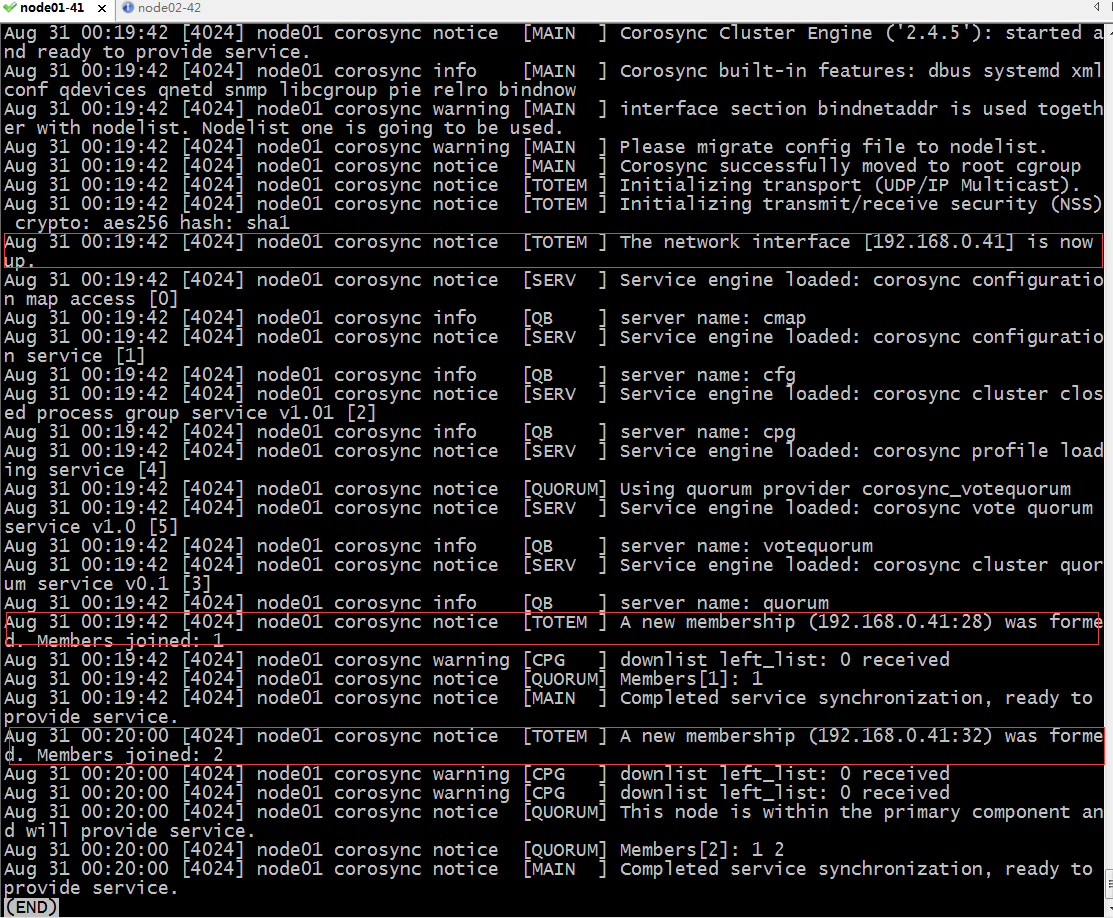
提示:在node01上可以看到对应的集群成员有2个;
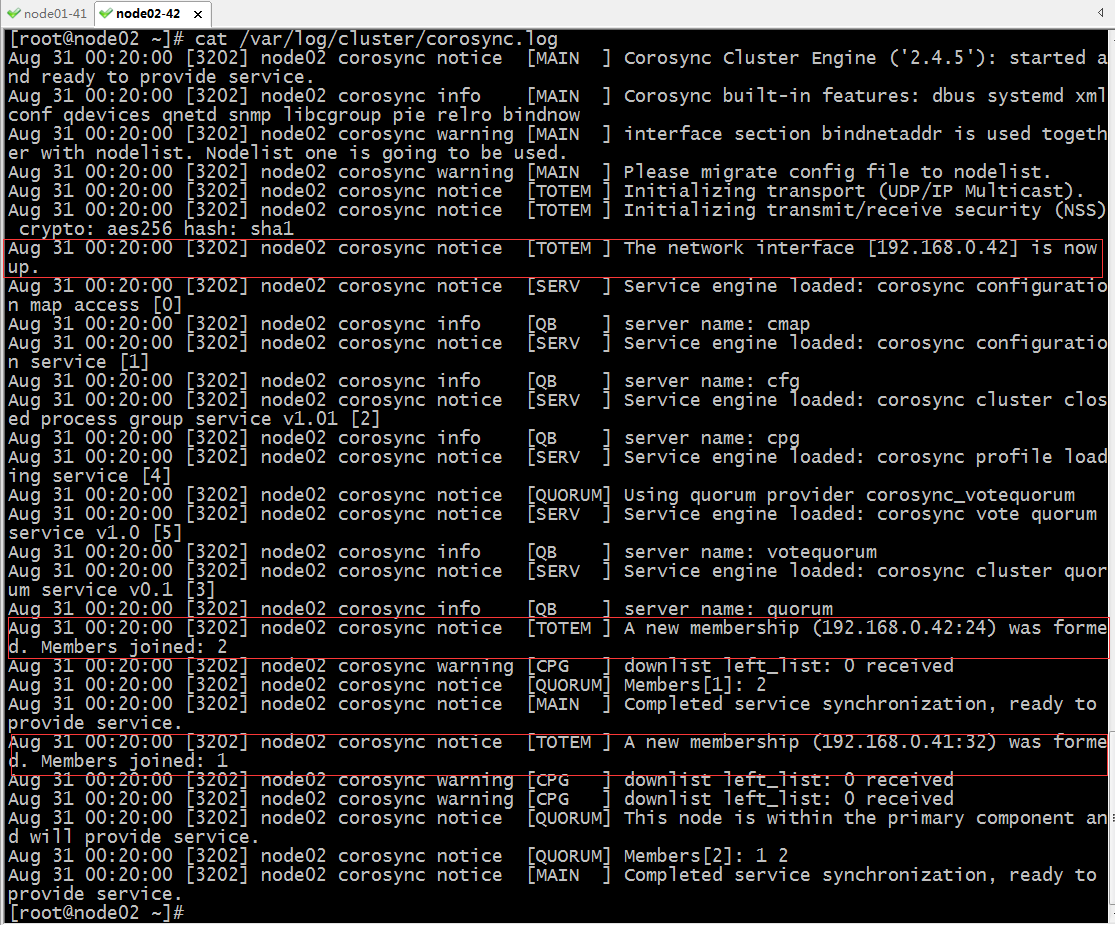
提示:在node02的日志文件中也能看到node01加入到集群,对应集群成员有两个;
验证:使用corosync-cfgtool命令来查看当前节点的初始化信息
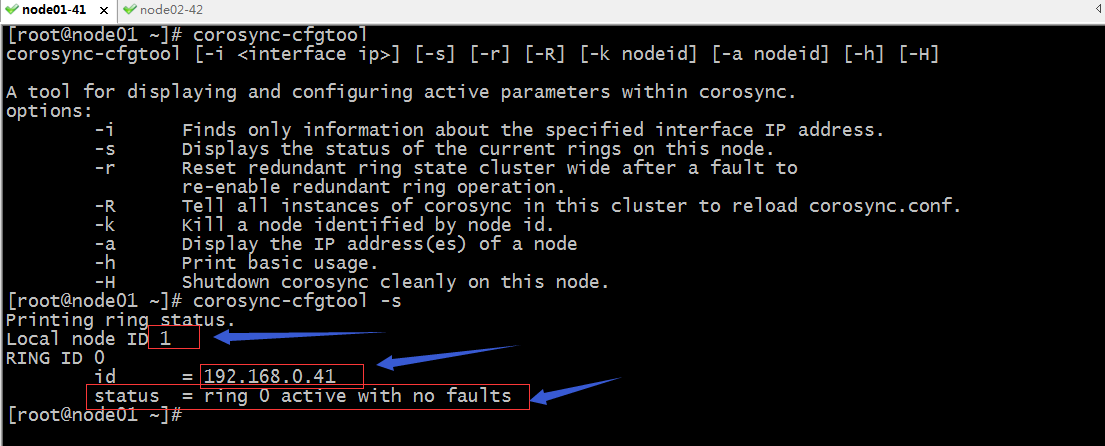
提示:-s表示查看当前节点各ring上的状态信息;从上面的信息可以看到node01上节点id为1,ring0上的id为192.168.0.41,状态是活跃没有发现错误;

提示:同样在node02上使用corosync-cfgtool -s 可以看到当前node02上的ring0的状态信息;从上面的截图可以看到两个节点都已经处于活跃状态;
验证:使用corosync-cmaptools查看成员
[root@node01 ~]# corosync-cmapctl config.totemconfig_reload_in_progress (u8) = 0 internal_configuration.service.0.name (str) = corosync_cmap internal_configuration.service.0.ver (u32) = 0 internal_configuration.service.1.name (str) = corosync_cfg internal_configuration.service.1.ver (u32) = 0 internal_configuration.service.2.name (str) = corosync_cpg internal_configuration.service.2.ver (u32) = 0 internal_configuration.service.3.name (str) = corosync_quorum internal_configuration.service.3.ver (u32) = 0 internal_configuration.service.4.name (str) = corosync_pload internal_configuration.service.4.ver (u32) = 0 internal_configuration.service.5.name (str) = corosync_votequorum internal_configuration.service.5.ver (u32) = 0 logging.debug (str) = off logging.fileline (str) = off logging.logfile (str) = /var/log/cluster/corosync.log logging.logger_subsys.QUORUM.debug (str) = off logging.logger_subsys.QUORUM.subsys (str) = QUORUM logging.timestamp (str) = on logging.to_logfile (str) = yes logging.to_stderr (str) = no logging.to_syslog (str) = yes nodelist.local_node_pos (u32) = 0 nodelist.node.0.nodeid (u32) = 1 nodelist.node.0.ring0_addr (str) = node01.test.org nodelist.node.1.nodeid (u32) = 2 nodelist.node.1.ring0_addr (str) = node02.test.org quorum.provider (str) = corosync_votequorum runtime.blackbox.dump_flight_data (str) = no runtime.blackbox.dump_state (str) = no runtime.config.totem.block_unlisted_ips (u32) = 1 runtime.config.totem.consensus (u32) = 1200 runtime.config.totem.downcheck (u32) = 1000 runtime.config.totem.fail_recv_const (u32) = 2500 runtime.config.totem.heartbeat_failures_allowed (u32) = 0 runtime.config.totem.hold (u32) = 180 runtime.config.totem.join (u32) = 50 runtime.config.totem.max_messages (u32) = 17 runtime.config.totem.max_network_delay (u32) = 50 runtime.config.totem.merge (u32) = 200 runtime.config.totem.miss_count_const (u32) = 5 runtime.config.totem.rrp_autorecovery_check_timeout (u32) = 1000 runtime.config.totem.rrp_problem_count_mcast_threshold (u32) = 100 runtime.config.totem.rrp_problem_count_threshold (u32) = 10 runtime.config.totem.rrp_problem_count_timeout (u32) = 2000 runtime.config.totem.rrp_token_expired_timeout (u32) = 238 runtime.config.totem.send_join (u32) = 0 runtime.config.totem.seqno_unchanged_const (u32) = 30 runtime.config.totem.token (u32) = 1000 runtime.config.totem.token_retransmit (u32) = 238 runtime.config.totem.token_retransmits_before_loss_const (u32) = 4 runtime.config.totem.window_size (u32) = 50 runtime.connections.active (u64) = 1 runtime.connections.closed (u64) = 4 runtime.connections.corosync-cmapct:4355:0x55c18dd16300.client_pid (u32) = 4355 runtime.connections.corosync-cmapct:4355:0x55c18dd16300.dispatched (u64) = 0 runtime.connections.corosync-cmapct:4355:0x55c18dd16300.flow_control (u32) = 0 runtime.connections.corosync-cmapct:4355:0x55c18dd16300.flow_control_count (u64) = 0 runtime.connections.corosync-cmapct:4355:0x55c18dd16300.invalid_request (u64) = 0 runtime.connections.corosync-cmapct:4355:0x55c18dd16300.name (str) = corosync-cmapct runtime.connections.corosync-cmapct:4355:0x55c18dd16300.overload (u64) = 0 runtime.connections.corosync-cmapct:4355:0x55c18dd16300.queue_size (u32) = 0 runtime.connections.corosync-cmapct:4355:0x55c18dd16300.recv_retries (u64) = 0 runtime.connections.corosync-cmapct:4355:0x55c18dd16300.requests (u64) = 0 runtime.connections.corosync-cmapct:4355:0x55c18dd16300.responses (u64) = 0 runtime.connections.corosync-cmapct:4355:0x55c18dd16300.send_retries (u64) = 0 runtime.connections.corosync-cmapct:4355:0x55c18dd16300.service_id (u32) = 0 runtime.services.cfg.0.rx (u64) = 0 runtime.services.cfg.0.tx (u64) = 0 runtime.services.cfg.1.rx (u64) = 0 runtime.services.cfg.1.tx (u64) = 0 runtime.services.cfg.2.rx (u64) = 0 runtime.services.cfg.2.tx (u64) = 0 runtime.services.cfg.3.rx (u64) = 0 runtime.services.cfg.3.tx (u64) = 0 runtime.services.cfg.service_id (u16) = 1 runtime.services.cmap.0.rx (u64) = 3 runtime.services.cmap.0.tx (u64) = 2 runtime.services.cmap.service_id (u16) = 0 runtime.services.cpg.0.rx (u64) = 0 runtime.services.cpg.0.tx (u64) = 0 runtime.services.cpg.1.rx (u64) = 0 runtime.services.cpg.1.tx (u64) = 0 runtime.services.cpg.2.rx (u64) = 0 runtime.services.cpg.2.tx (u64) = 0 runtime.services.cpg.3.rx (u64) = 0 runtime.services.cpg.3.tx (u64) = 0 runtime.services.cpg.4.rx (u64) = 0 runtime.services.cpg.4.tx (u64) = 0 runtime.services.cpg.5.rx (u64) = 3 runtime.services.cpg.5.tx (u64) = 2 runtime.services.cpg.6.rx (u64) = 0 runtime.services.cpg.6.tx (u64) = 0 runtime.services.cpg.service_id (u16) = 2 runtime.services.pload.0.rx (u64) = 0 runtime.services.pload.0.tx (u64) = 0 runtime.services.pload.1.rx (u64) = 0 runtime.services.pload.1.tx (u64) = 0 runtime.services.pload.service_id (u16) = 4 runtime.services.quorum.service_id (u16) = 3 runtime.services.votequorum.0.rx (u64) = 7 runtime.services.votequorum.0.tx (u64) = 4 runtime.services.votequorum.1.rx (u64) = 0 runtime.services.votequorum.1.tx (u64) = 0 runtime.services.votequorum.2.rx (u64) = 0 runtime.services.votequorum.2.tx (u64) = 0 runtime.services.votequorum.3.rx (u64) = 0 runtime.services.votequorum.3.tx (u64) = 0 runtime.services.votequorum.service_id (u16) = 5 runtime.totem.pg.mrp.rrp.0.faulty (u8) = 0 runtime.totem.pg.mrp.srp.avg_backlog_calc (u32) = 0 runtime.totem.pg.mrp.srp.avg_token_workload (u32) = 0 runtime.totem.pg.mrp.srp.commit_entered (u64) = 2 runtime.totem.pg.mrp.srp.commit_token_lost (u64) = 0 runtime.totem.pg.mrp.srp.consensus_timeouts (u64) = 0 runtime.totem.pg.mrp.srp.continuous_gather (u32) = 0 runtime.totem.pg.mrp.srp.continuous_sendmsg_failures (u32) = 0 runtime.totem.pg.mrp.srp.firewall_enabled_or_nic_failure (u8) = 0 runtime.totem.pg.mrp.srp.gather_entered (u64) = 2 runtime.totem.pg.mrp.srp.gather_token_lost (u64) = 0 runtime.totem.pg.mrp.srp.mcast_retx (u64) = 0 runtime.totem.pg.mrp.srp.mcast_rx (u64) = 12 runtime.totem.pg.mrp.srp.mcast_tx (u64) = 13 runtime.totem.pg.mrp.srp.memb_commit_token_rx (u64) = 4 runtime.totem.pg.mrp.srp.memb_commit_token_tx (u64) = 4 runtime.totem.pg.mrp.srp.memb_join_rx (u64) = 5 runtime.totem.pg.mrp.srp.memb_join_tx (u64) = 3 runtime.totem.pg.mrp.srp.memb_merge_detect_rx (u64) = 1771 runtime.totem.pg.mrp.srp.memb_merge_detect_tx (u64) = 1771 runtime.totem.pg.mrp.srp.members.1.config_version (u64) = 0 runtime.totem.pg.mrp.srp.members.1.ip (str) = r(0) ip(192.168.0.41) runtime.totem.pg.mrp.srp.members.1.join_count (u32) = 1 runtime.totem.pg.mrp.srp.members.1.status (str) = joined runtime.totem.pg.mrp.srp.members.2.config_version (u64) = 0 runtime.totem.pg.mrp.srp.members.2.ip (str) = r(0) ip(192.168.0.42) runtime.totem.pg.mrp.srp.members.2.join_count (u32) = 1 runtime.totem.pg.mrp.srp.members.2.status (str) = joined runtime.totem.pg.mrp.srp.mtt_rx_token (u32) = 181 runtime.totem.pg.mrp.srp.operational_entered (u64) = 2 runtime.totem.pg.mrp.srp.operational_token_lost (u64) = 0 runtime.totem.pg.mrp.srp.orf_token_rx (u64) = 3624 runtime.totem.pg.mrp.srp.orf_token_tx (u64) = 2 runtime.totem.pg.mrp.srp.recovery_entered (u64) = 2 runtime.totem.pg.mrp.srp.recovery_token_lost (u64) = 0 runtime.totem.pg.mrp.srp.rx_msg_dropped (u64) = 0 runtime.totem.pg.mrp.srp.token_hold_cancel_rx (u64) = 0 runtime.totem.pg.mrp.srp.token_hold_cancel_tx (u64) = 0 runtime.totem.pg.msg_queue_avail (u32) = 0 runtime.totem.pg.msg_reserved (u32) = 1 runtime.votequorum.ev_barrier (u32) = 2 runtime.votequorum.highest_node_id (u32) = 2 runtime.votequorum.lowest_node_id (u32) = 1 runtime.votequorum.this_node_id (u32) = 1 runtime.votequorum.two_node (u8) = 0 totem.crypto_cipher (str) = aes256 totem.crypto_hash (str) = sha1 totem.interface.0.bindnetaddr (str) = node01.test.org totem.interface.0.mcastaddr (str) = 239.255.100.12 totem.interface.0.mcastport (u16) = 5405 totem.interface.0.ttl (u8) = 1 totem.version (u32) = 2 [root@node01 ~]#
提示:默认不跟任何选项表示答应当前CIB中保存的配置内容;

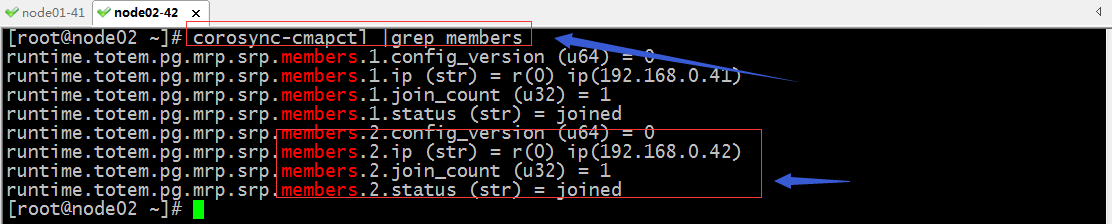
提示:通过grep过滤,可以看到有两个成员,他们的ip地址分别是192.168.0.41和42;到此corosync就配置并启动成功了;
完整的corosync.conf配置文件内容


[root@node01 ~]# grep -v "^[[:space:]].*#" /etc/corosync/corosync.conf # Please read the corosync.conf.5 manual page totem { version: 2 crypto_cipher: aes256 crypto_hash: sha1 interface { ringnumber: 0 bindnetaddr: 192.168.0.0 mcastaddr: 239.255.100.12 mcastport: 5405 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: yes logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } quorum { provider: corosync_votequorum } nodelist { node { ring0_addr: node01.test.org nodeid: 1 } node { ring0_addr: node02.test.org nodeid: 2 } } [root@node01 ~]#
启动pacamaker服务

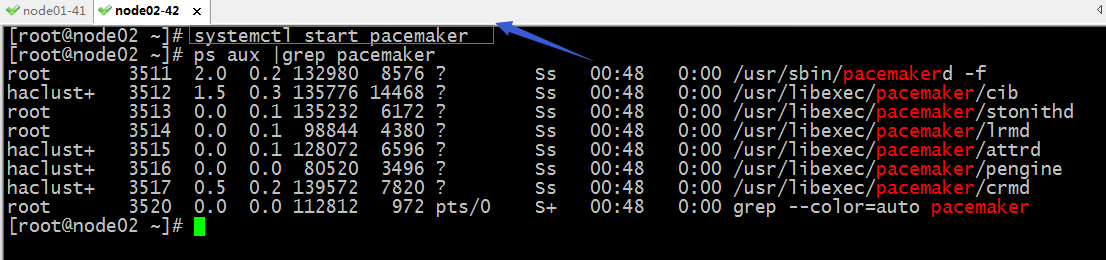
提示:pacemaker默认不需要怎么配置就可以启动,启动以后,我们可以通过管理接口来配置;默认才开始启动pacemaker时都会有一个pengine的进程启动,但是通常只有DC上的pengine才会生效;
验证:查看DC节点所在节点/集群状态信息
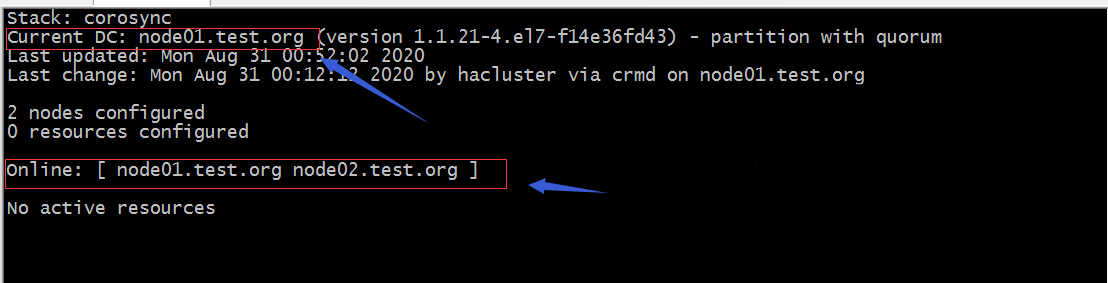
提示:在集群任何一个几点执行crm_mon就可以看到当前集群的状态信息;上面截图中可以看到node01.test.org是dc节点,在线的节点有两个,分别是node01.test.org和node02.test.org;
到此corosync+pacemaker高可用集群就搭建好了,后续我们就直接可以在上面托管服务;