在执行流应用程序期间,Flink会定期检查状态的一致检查点。如果发生故障,Flink将会使用最近的检查点来一致恢复应用程序的状态,并重新启动处理流程。图3-18显示了恢复过程。
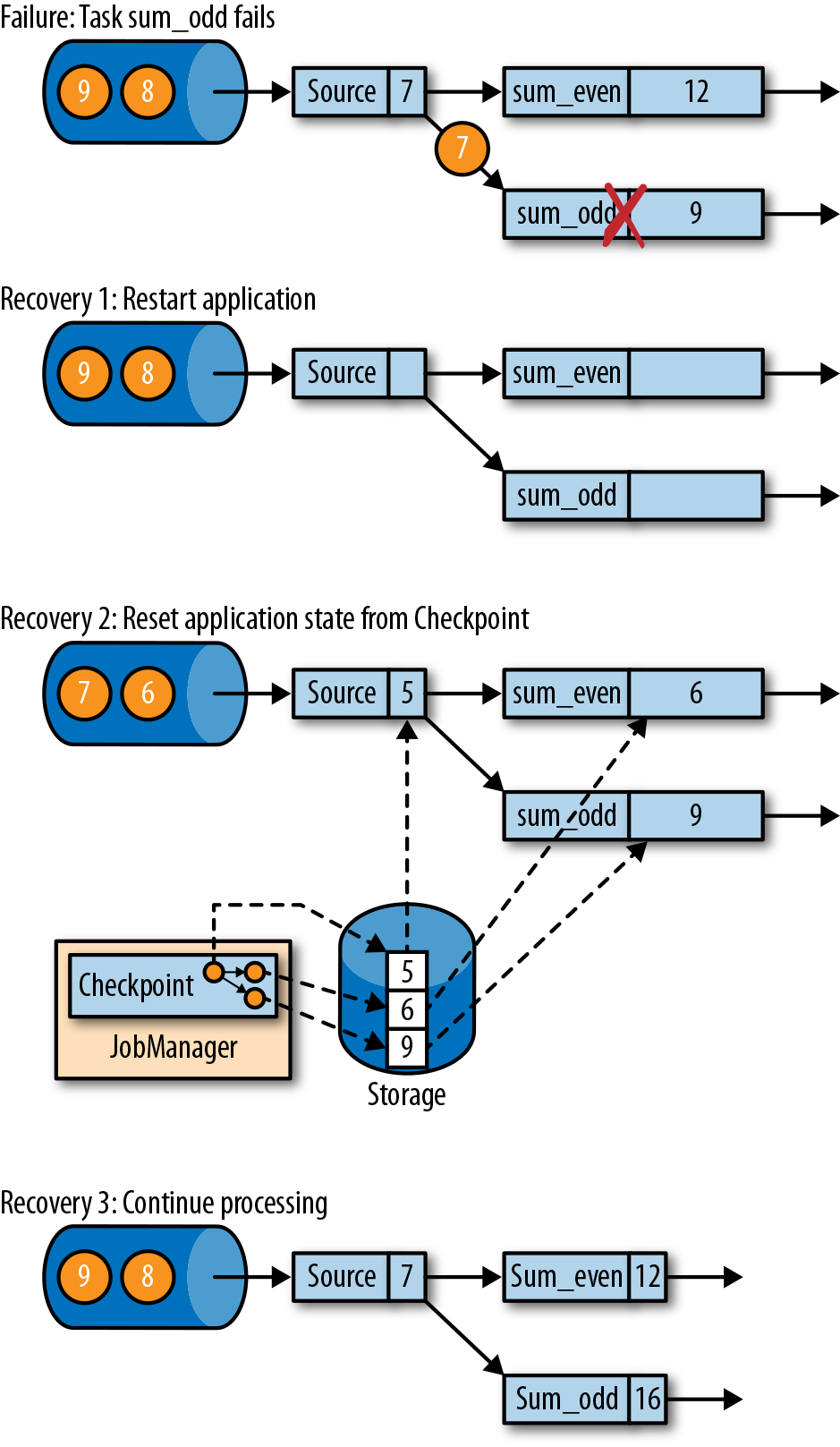
应用程序从检查点的恢复分为三步:
- 重新启动整个应用程序。
- 将所有的有状态任务的状态重置为最近一次的检查点。
- 恢复所有任务的处理。
这种检查点的保存和恢复机制可以为应用程序状态提供“精确一次”(exactly-once)的一致性,因为所有算子都会保存检查点并恢复其所有状态,这样一来所有的输入流就都会被重置到检查点完成时的位置。至于数据源是否可以重置它的输入流,这取决于其实现方式和消费流数据的外部接口。例如,像Apache Kafka这样的事件日志系统可以提供流上之前偏移位置的数据,所以我们可以将源重置到之前的偏移量,重新消费数据。而从套接字(socket)消费数据的流就不能被重置了,因为套接字的数据一旦被消费就会丢弃掉。因此,对于应用程序而言,只有当所有的输入流消费的都是可重置的数据源时,才能确保在“精确一次”的状态一致性下运行。
从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同。然后它就会开始消费并处理检查点和发生故障之间的所有数据。尽管这意味着Flink会对一些数据处理两次(在故障之前和之后),我们仍然可以说这个机制实现了精确一次的一致性语义,因为所有算子的状态都已被重置,而重置后的状态下还不曾看到这些数据。
我们必须指出,Flink的检查点保存和恢复机制仅仅可以重置流应用程序的内部状态。对于应用中的一些的输出(sink)算子,在恢复期间,某些结果数据可能会多次发送到下游系统,比如事件日志、文件系统或数据库。对于某些存储系统,Flink提供了具有精确一次输出功能的sink函数,比如,可以在检查点完成时提交发出的记录。另一种适用于许多存储系统的方法是幂等更新。在“应用程序一致性保证”一节中,我们还会详细讨论如何解决应用程序端到端的精确一次一致性问题。