1 Hive 的核心组成介绍
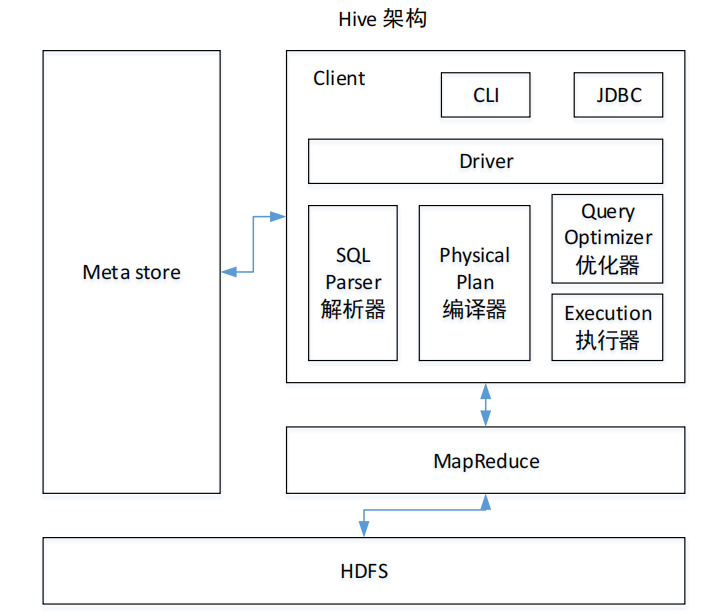
1)用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc 访问 hive)、WEBUI(浏览器访问 hive)
2)元数据:Metastore
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Metastore
3)Hadoop
使用 HDFS 进行存储,使用 MapReduce 进行计算。
4)驱动器:Driver
5)解析器(SQL Parser)
将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 antlr;
对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误。
6)编译器(Physical Plan)
将 AST 编译生成逻辑执行计划。
7)优化器(Query Optimizer)
对逻辑执行计划进行优化。
8)执行器(Execution)
把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来说,就是 MR/Spark。
2 HQL 转换为 MR 任务流程说明
1.进入程序,利用Antlr框架定义HQL的语法规则,对HQL完成词法语法解析,将HQL转换为为AST(抽象语法树);
2.遍历AST,抽象出查询的基本组成单元QueryBlock(查询块),可以理解为最小的查询执行单元;
3.遍历QueryBlock,将其转换为OperatorTree(操作树,也就是逻辑执行计划),可以理解为不可拆分的一个逻辑执行单元;
4.使用逻辑优化器对OperatorTree(操作树)进行逻辑优化。例如合并不必要的ReduceSinkOperator,减少Shuffle数据量;
5.遍历OperatorTree,转换为TaskTree。也就是翻译为MR任务的流程,将逻辑执行计划转换为物理执行计划;
6.使用物理优化器对TaskTree进行物理优化;
7.生成最终的执行计划,提交任务到Hadoop集群运行。