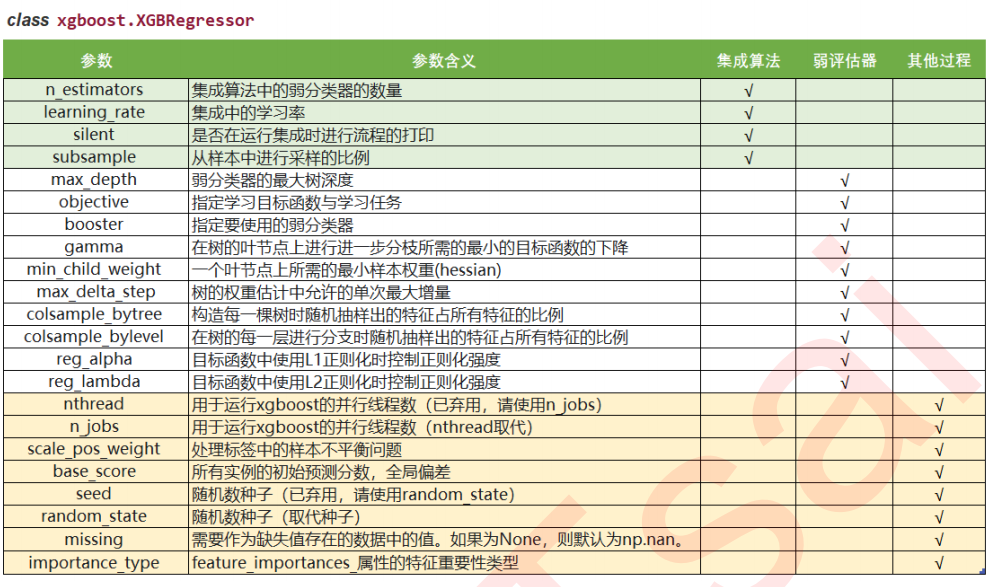
1 过拟合:剪枝参数与回归模型调参



dfull = xgb.DMatrix(X,y) param1 = {'silent':True #并非默认 ,'obj':'reg:linear' #并非默认 ,"subsample":1 ,"max_depth":6 ,"eta":0.3 ,"gamma":0 ,"lambda":1 ,"alpha":0 ,"colsample_bytree":1 ,"colsample_bylevel":1 ,"colsample_bynode":1 ,"nfold":5} num_round = 200 time0 = time() cvresult1 = xgb.cv(param1, dfull, num_round) print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f")) fig,ax = plt.subplots(1,figsize=(15,10)) #ax.set_ylim(top=5) ax.grid() ax.plot(range(1,201),cvresult1.iloc[:,0],c="red",label="train,original") ax.plot(range(1,201),cvresult1.iloc[:,2],c="orange",label="test,original") ax.legend(fontsize="xx-large") plt.show()

param1 = {'silent':True
,'obj':'reg:linear'
,"subsample":1
,"max_depth":6
,"eta":0.3
,"gamma":0
,"lambda":1
,"alpha":0
,"colsample_bytree":1
,"colsample_bylevel":1
,"colsample_bynode":1
,"nfold":5}
num_round = 200
time0 = time()
cvresult1 = xgb.cv(param1, dfull, num_round)
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))
fig,ax = plt.subplots(1,figsize=(15,8))
ax.set_ylim(top=5)
ax.grid()
ax.plot(range(1,201),cvresult1.iloc[:,0],c="red",label="train,original")
ax.plot(range(1,201),cvresult1.iloc[:,2],c="orange",label="test,original")
param2 = {'silent':True
,'obj':'reg:linear'
,"nfold":5}
param3 = {'silent':True
,'obj':'reg:linear'
,"nfold":5}
time0 = time()
cvresult2 = xgb.cv(param2, dfull, num_round)
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))
time0 = time()
cvresult3 = xgb.cv(param3, dfull, num_round)
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))
ax.plot(range(1,201),cvresult2.iloc[:,0],c="green",label="train,last")
ax.plot(range(1,201),cvresult2.iloc[:,2],c="blue",label="test,last")
ax.plot(range(1,201),cvresult3.iloc[:,0],c="gray",label="train,this")
ax.plot(range(1,201),cvresult3.iloc[:,2],c="pink",label="test,this")
ax.legend(fontsize="xx-large")
plt.show()
在这里,为大家提供我调出来的结果,供大家参考:
#默认设置 param1 = {'silent':True ,'obj':'reg:linear' ,"subsample":1 ,"max_depth":6 ,"eta":0.3 ,"gamma":0 ,"lambda":1 ,"alpha":0 ,"colsample_bytree":1 ,"colsample_bylevel":1 ,"colsample_bynode":1 ,"nfold":5} num_round = 200 time0 = time() cvresult1 = xgb.cv(param1, dfull, num_round) print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f")) fig,ax = plt.subplots(1,figsize=(15,8)) ax.set_ylim(top=5) ax.grid() ax.plot(range(1,201),cvresult1.iloc[:,0],c="red",label="train,original") ax.plot(range(1,201),cvresult1.iloc[:,2],c="orange",label="test,original")
#调参结果1 param2 = {'silent':True ,'obj':'reg:linear' ,"subsample":1 ,"eta":0.05 ,"gamma":20 ,"lambda":3.5 ,"alpha":0.2 ,"max_depth":4 ,"colsample_bytree":0.4 ,"colsample_bylevel":0.6 ,"colsample_bynode":1 ,"nfold":5}
#调参结果2 param3 = {'silent':True ,'obj':'reg:linear' ,"max_depth":2 ,"eta":0.05 ,"gamma":0 ,"lambda":1 ,"alpha":0 ,"colsample_bytree":1 ,"colsample_bylevel":0.4 ,"colsample_bynode":1 ,"nfold":5} time0 = time() cvresult2 = xgb.cv(param2, dfull, num_round) print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f")) ax.plot(range(1,201),cvresult2.iloc[:,0],c="green",label="train,final") ax.plot(range(1,201),cvresult2.iloc[:,2],c="blue",label="test,final") ax.legend(fontsize="xx-large") plt.show()


2 XGBoost模型的保存和调用

2.1 使用Pickle保存和调用模型

import pickle dtrain = xgb.DMatrix(Xtrain,Ytrain) #设定参数,对模型进行训练 param = {'silent':True ,'obj':'reg:linear' ,"subsample":1 ,"eta":0.05 ,"gamma":20 ,"lambda":3.5 ,"alpha":0.2 ,"max_depth":4 ,"colsample_bytree":0.4 ,"colsample_bylevel":0.6 ,"colsample_bynode":1} num_round = 180 bst = xgb.train(param, dtrain, num_round) #保存模型 pickle.dump(bst, open("xgboostonboston.dat","wb")) #注意,open中我们往往使用w或者r作为读取的模式,但其实w与r只能用于文本文件,当我们希望导入的不是文本文件,而 是模型本身的时候,我们使用"wb"和"rb"作为读取的模式。其中wb表示以二进制写入,rb表示以二进制读入 #看看模型被保存到了哪里? import sys sys.path #重新打开jupyter lab from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split as TTS from sklearn.metrics import mean_squared_error as MSE import pickle import xgboost as xgb data = load_boston() X = data.data y = data.target Xtrain,Xtest,Ytrain,Ytest = TTS(X,y,test_size=0.3,random_state=420) #注意,如果我们保存的模型是xgboost库中建立的模型,则导入的数据类型也必须是xgboost库中的数据类型 dtest = xgb.DMatrix(Xtest,Ytest) #导入模型 loaded_model = pickle.load(open("xgboostonboston.dat", "rb")) print("Loaded model from: xgboostonboston.dat") #做预测 ypreds = loaded_model.predict(dtest) from sklearn.metrics import mean_squared_error as MSE, r2_score MSE(Ytest,ypreds) r2_score(Ytest,ypreds)
2.2 使用Joblib保存和调用模型

bst = xgb.train(param, dtrain, num_round) import joblib #同样可以看看模型被保存到了哪里 joblib.dump(bst,"xgboost-boston.dat") loaded_model = joblib.load("xgboost-boston.dat") ypreds = loaded_model.predict(dtest) MSE(Ytest, ypreds) r2_score(Ytest,ypreds) #使用sklearn中的模型 from xgboost import XGBRegressor as XGBR bst = XGBR(n_estimators=200 ,eta=0.05,gamma=20 ,reg_lambda=3.5 ,reg_alpha=0.2 ,max_depth=4 ,colsample_bytree=0.4 ,colsample_bylevel=0.6).fit(Xtrain,Ytrain) joblib.dump(bst,"xgboost-boston.dat") loaded_model = joblib.load("xgboost-boston.dat") #则这里可以直接导入Xtest ypreds = loaded_model.predict(Xtest) MSE(Ytest, ypreds)

3 分类案例:XGB中的样本不均衡问题

1. 导库,创建样本不均衡的数据集
import numpy as np import xgboost as xgb import matplotlib.pyplot as plt from xgboost import XGBClassifier as XGBC from sklearn.datasets import make_blobs from sklearn.model_selection import train_test_split as TTS from sklearn.metrics import confusion_matrix as cm, recall_score as recall, roc_auc_score as auc class_1 = 500 #类别1有500个样本 class_2 = 50 #类别2只有50个 centers = [[0.0, 0.0], [2.0, 2.0]] #设定两个类别的中心 clusters_std = [1.5, 0.5] #设定两个类别的方差,通常来说,样本量比较大的类别会更加松散 X, y = make_blobs(n_samples=[class_1, class_2], centers=centers, cluster_std=clusters_std, random_state=0, shuffle=False) Xtrain, Xtest, Ytrain, Ytest = TTS(X,y,test_size=0.3,random_state=420) (y == 1).sum() / y.shape[0]
2. 在数据集上建模:sklearn模式
#在sklearn下建模# clf = XGBC().fit(Xtrain,Ytrain) ypred = clf.predict(Xtest) clf.score(Xtest,Ytest) cm(Ytest,ypred,labels=[1,0]) recall(Ytest,ypred) auc(Ytest,clf.predict_proba(Xtest)[:,1]) #负/正样本比例 clf_ = XGBC(scale_pos_weight=10).fit(Xtrain,Ytrain) ypred_ = clf_.predict(Xtest) clf_.score(Xtest,Ytest) cm(Ytest,ypred_,labels=[1,0]) recall(Ytest,ypred_) auc(Ytest,clf_.predict_proba(Xtest)[:,1]) #随着样本权重逐渐增加,模型的recall,auc和准确率如何变化? for i in [1,5,10,20,30]: clf_ = XGBC(scale_pos_weight=i).fit(Xtrain,Ytrain) ypred_ = clf_.predict(Xtest) print(i) print(" Accuracy:{}".format(clf_.score(Xtest,Ytest))) print(" Recall:{}".format(recall(Ytest,ypred_))) print(" AUC:{}".format(auc(Ytest,clf_.predict_proba(Xtest)[:,1])))
3. 在数据集上建模:xgboost模式
dtrain = xgb.DMatrix(Xtrain,Ytrain) dtest = xgb.DMatrix(Xtest,Ytest) #看看xgboost库自带的predict接口 param= {'silent':True,'objective':'binary:logistic',"eta":0.1,"scale_pos_weight":1} num_round = 100 bst = xgb.train(param, dtrain, num_round) preds = bst.predict(dtest) #看看preds返回了什么? preds #自己设定阈值 ypred = preds.copy() ypred[preds > 0.5] = 1 ypred[ypred != 1] = 0 #写明参数 scale_pos_weight = [1,5,10] names = ["negative vs positive: 1" ,"negative vs positive: 5" ,"negative vs positive: 10"] #导入模型评估指标 from sklearn.metrics import accuracy_score as accuracy, recall_score as recall, roc_auc_score as auc for name,i in zip(names,scale_pos_weight): param= {'silent':True,'objective':'binary:logistic' ,"eta":0.1,"scale_pos_weight":i} clf = xgb.train(param, dtrain, num_round) preds = clf.predict(dtest) ypred = preds.copy() ypred[preds > 0.5] = 1 ypred[ypred != 1] = 0 print(name) print(" Accuracy:{}".format(accuracy(Ytest,ypred))) print(" Recall:{}".format(recall(Ytest,ypred))) print(" AUC:{}".format(auc(Ytest,preds))) #当然我们也可以尝试不同的阈值 for name,i in zip(names,scale_pos_weight): for thres in [0.3,0.5,0.7,0.9]: param= {'silent':True,'objective':'binary:logistic' ,"eta":0.1,"scale_pos_weight":i} clf = xgb.train(param, dtrain, num_round) preds = clf.predict(dtest) ypred = preds.copy() ypred[preds > thres] = 1 ypred[ypred != 1] = 0 print("{},thresholds:{}".format(name,thres)) print(" Accuracy:{}".format(accuracy(Ytest,ypred))) print(" Recall:{}".format(recall(Ytest,ypred))) print(" AUC:{}".format(auc(Ytest,preds)))


4 XGBoost类中的其他参数和功能