1 认识高斯朴素贝叶斯




1. 展示我所使用的设备以及各个库的版本

%%cmd pip install watermark #在这里必须分开cell,魔法命令必须是一个cell的第一部分内容 #注意load_ext这个命令只能够执行一次,再执行就会报错,要求用reload命令 %load_ext watermark %watermark -a "TsaiTsai" -d -v -m -p numpy,pandas,matplotlib,scipy,sklearn
2. 导入需要的库和数据
import numpy as np import matplotlib.pyplot as plt from sklearn.naive_bayes import GaussianNB from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split digits = load_digits() X, y = digits.data, digits.target Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=420)
3. 建模,探索建模结果
gnb = GaussianNB().fit(Xtrain,Ytrain) #查看分数 acc_score = gnb.score(Xtest,Ytest) acc_score #查看预测结果 Y_pred = gnb.predict(Xtest) #查看预测的概率结果 prob = gnb.predict_proba(Xtest) prob.shape prob.shape #每一列对应一个标签下的概率 prob[1,:].sum() #每一行的和都是一 prob.sum(axis=1)
4. 使用混淆矩阵来查看贝叶斯的分类结果
from sklearn.metrics import confusion_matrix as CM CM(Ytest,Y_pred)
#注意,ROC曲线是不能用于多分类的。多分类状况下最佳的模型评估指标是混淆矩阵和整体的准确度
2 探索贝叶斯:高斯朴素贝叶斯擅长的数据集

import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.datasets import make_moons, make_circles, make_classification from sklearn.naive_bayes import GaussianNB h = .02 names = ["Multinomial","Gaussian","Bernoulli","Complement"] classifiers = [MultinomialNB(),GaussianNB(),BernoulliNB(),ComplementNB()] X, y = make_classification(n_features=2, n_redundant=0, n_informative=2, random_state=1, n_clusters_per_class=1) rng = np.random.RandomState(2) X += 2 * rng.uniform(size=X.shape) linearly_separable = (X, y) datasets = [make_moons(noise=0.3, random_state=0), make_circles(noise=0.2, factor=0.5, random_state=1), linearly_separable ] figure = plt.figure(figsize=(6, 9)) i = 1 for ds_index, ds in enumerate(datasets): X, y = ds X = StandardScaler().fit_transform(X) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.4, random_state=42) x1_min, x1_max = X[:, 0].min() - .5, X[:, 0].max() + .5 x2_min, x2_max = X[:, 1].min() - .5, X[:, 1].max() + .5 array1,array2 = np.meshgrid(np.arange(x1_min, x1_max, 0.2), np.arange(x2_min, x2_max, 0.2)) cm = plt.cm.RdBu cm_bright = ListedColormap(['#FF0000', '#0000FF']) ax = plt.subplot(len(datasets), 2, i) if ds_index == 0: ax.set_title("Input data") ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright,edgecolors='k') ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.6,edgecolors='k') ax.set_xlim(array1.min(), array1.max()) ax.set_ylim(array2.min(), array2.max()) ax.set_xticks(()) ax.set_yticks(()) i += 1 ax = plt.subplot(len(datasets),2,i) clf = GaussianNB().fit(X_train, y_train) score = clf.score(X_test, y_test) Z = clf.predict_proba(np.c_[array1.ravel(),array2.ravel()])[:, 1] Z = Z.reshape(array1.shape) ax.contourf(array1, array2, Z, cmap=cm, alpha=.8) ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright, edgecolors='k') ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, edgecolors='k', alpha=0.6) ax.set_xlim(array1.min(), array1.max()) ax.set_ylim(array2.min(), array2.max()) ax.set_xticks(()) ax.set_yticks(()) if ds_index == 0: ax.set_title("Gaussian Bayes") ax.text(array1.max() - .3, array2.min() + .3, ('{:.1f}%'.format(score*100)), size=15, horizontalalignment='right') i += 1 plt.tight_layout() plt.show()
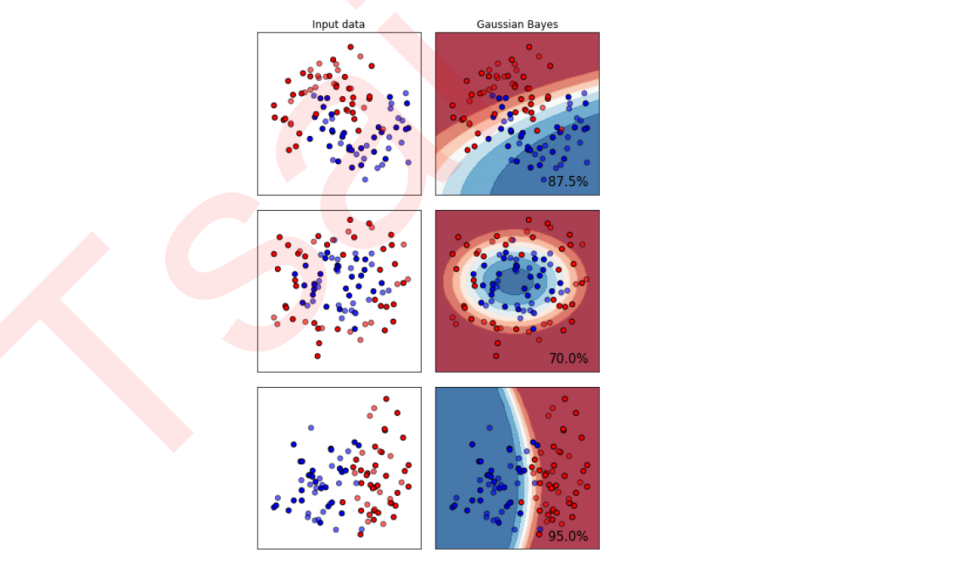

3 探索贝叶斯:高斯朴素贝叶斯的拟合效果与运算速度

1. 首先导入需要的模块和库
import numpy as np import matplotlib.pyplot as plt from sklearn.naive_bayes import GaussianNB from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier as RFC from sklearn.tree import DecisionTreeClassifier as DTC from sklearn.linear_model import LogisticRegression as LR from sklearn.datasets import load_digits from sklearn.model_selection import learning_curve from sklearn.model_selection import ShuffleSplit from time import time import datetime
2. 定义绘制学习曲线的函数
def plot_learning_curve(estimator,title, X, y, ax, #选择子图 ylim=None, #设置纵坐标的取值范围 cv=None, #交叉验证 n_jobs=None #设定索要使用的线程 ): train_sizes, train_scores, test_scores = learning_curve(estimator, X, y ,cv=cv,n_jobs=n_jobs) ax.set_title(title) if ylim is not None: ax.set_ylim(*ylim) ax.set_xlabel("Training examples") ax.set_ylabel("Score") ax.grid() #显示网格作为背景,不是必须 ax.plot(train_sizes, np.mean(train_scores, axis=1), 'o-' , color="r",label="Training score") ax.plot(train_sizes, np.mean(test_scores, axis=1), 'o-' , color="g",label="Test score") ax.legend(loc="best") return ax
3. 导入数据,定义循环
digits = load_digits() X, y = digits.data, digits.target X.shape X #是一个稀疏矩阵 title = ["Naive Bayes","DecisionTree","SVM, RBF kernel","RandomForest","Logistic"] model = [GaussianNB(),DTC(),SVC(gamma=0.001) ,RFC(n_estimators=50),LR(C=.1,solver="lbfgs")] cv = ShuffleSplit(n_splits=50, test_size=0.2, random_state=0)
4. 进入循环,绘制学习曲线
fig, axes = plt.subplots(1,5,figsize=(30,6)) for ind,title_,estimator in zip(range(len(title)),title,model): times = time() plot_learning_curve(estimator, title_, X, y, ax=axes[ind], ylim = [0.7, 1.05],n_jobs=4, cv=cv) print("{}:{}".format(title_,datetime.datetime.fromtimestamp(time()- times).strftime("%M:%S:%f"))) plt.show()


